系统:Window11
环境:Pycharm uv虚拟环境
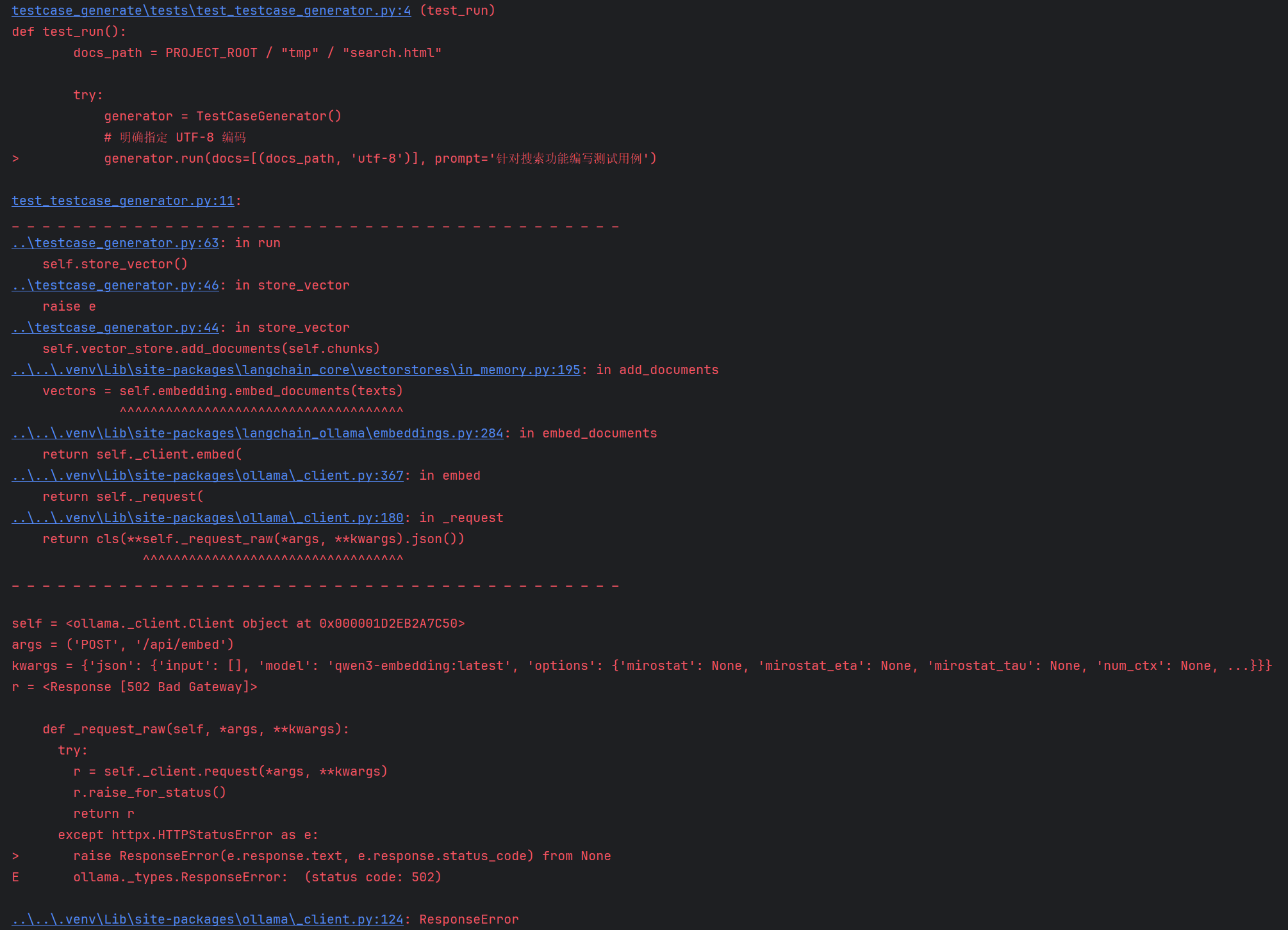
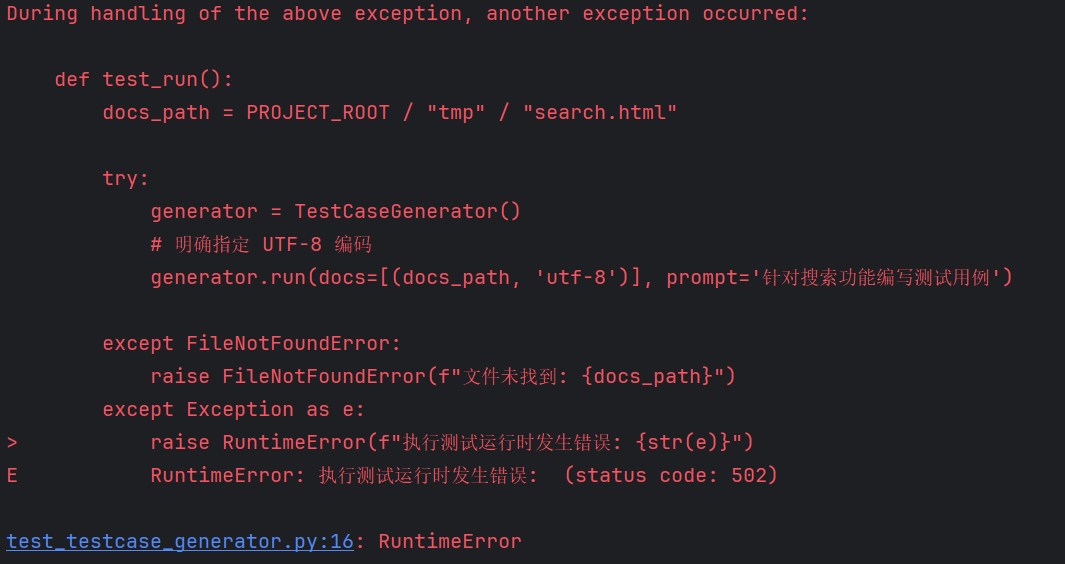
运行test_run代码报错:
def test_run():
docs_path = PROJECT_ROOT / "tmp" / "search.html"
try:
generator = TestCaseGenerator()
# 明确指定 UTF-8 编码
generator.run(docs=[(docs_path, 'utf-8')], prompt='针对搜索功能编写测试用例')
except FileNotFoundError:
raise FileNotFoundError(f"文件未找到: {docs_path}")
except Exception as e:
raise RuntimeError(f"执行测试运行时发生错误: {str(e)}")
报错如下:
testcase_geneator.py如下:
···
class TestCaseGenerator:
def __init__(self):
self.doc_list = []
self.chunks = []
# vector store in memory
self.ollama_embedding=OllamaEmbeddings(model="qwen3-embedding:latest")
# self.ollama_embedding=OllamaEmbeddings(model="bge-m3:latest")
self.vector_store = InMemoryVectorStore(self.ollama_embedding)
def load_docs(self, docs):
for doc in docs:
if isinstance(doc, tuple):
self.doc_list.extend(DocumentLoaderFactory.get_docs(doc))
else:
self.doc_list.extend(DocumentLoaderFactory.get_docs(doc))
# debug(self.doc_list)
def split_docs(self):
for doc in self.doc_list:
chunks = SplitterFactory.split(doc, 'html')
self.chunks += chunks
# debug(self.chunks)
# embedding
def store_vector(self):
try:
self.vector_store.add_documents(self.chunks)
except Exception as e:
raise e
def search(self, query):
docs = self.vector_store.search("测试人", search_type="mmr", k=3)
for doc in docs:
debug(doc)
def run(self, docs: List[Union[Tuple[Union[str, Path], str], Union[str, Path]]], prompt: str = None):
# 创建知识库,工厂,可以读取所有文档,loader完成后 得到文档列表
# for doc in docs:
# # 得到很大的文档,需要二次切割
# doc_list = DocumentLoaderFactory.get_docs(doc)
# self.doc_list += doc_list
self.load_docs(docs)
self.split_docs()
self.store_vector()
···
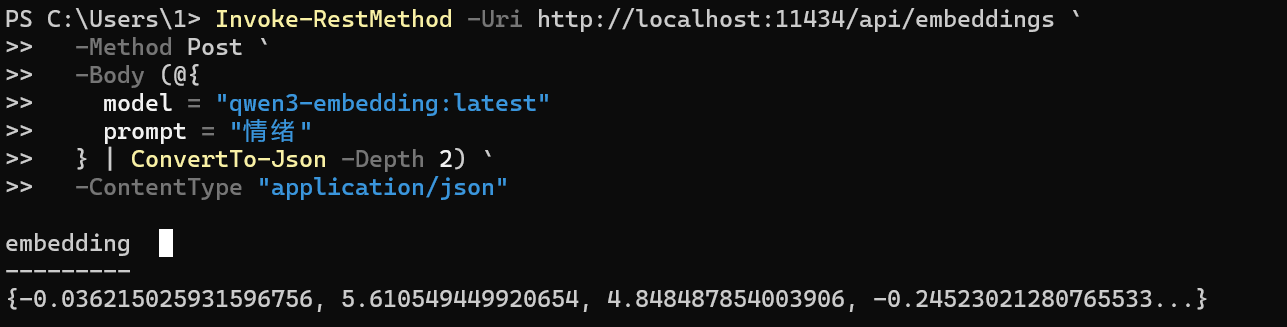
在powshell调用qwen3-embedding返回正常: