#!/usr/bin/bash
script_path=$(cd "$(dirname "$0")"; pwd)
log_file=$script_path/nginx.log
#正则 /topics/16689/replies/124751/edit 把数字替换为 /topics/int/replies/int/edit
reg_01='\/topics\/([0-9]+)\/replies\/([0-9]+)\/edit'
#正则 /_img/uploads/photo/2018/c54755ee-6bfd-489a-8a39-81a1d7551cbd.png!large 变成 /_img/uploads/photo/2018/id.png!large
reg_02='^\/photo\/[0-9]{4}\/.*'
#正则 /topics/9497 改成 /topics/int
reg_03='\/topics\/([0-9]+)'
url_summary(){
less $log_file | awk '{print $7}' \
|sed -r 's#$reg_01#\/topics\/int\/replies\/int\/edit#g' \
|sed -r 's#$reg_02#\/_img\/uploads\/photo\/int\/id#g' \
|sed -r 's#reg_03#\/topics\/int#g' \
|sort | uniq -c| sort -nr | head -n 10
}
echo 'top 10请求量的url如下:'
url_summary
2 个赞
因为shell中支持的正则表达式和python是不一样的,python扩展了很多强大的功能~
‘’’
url_summary() {
less nginx.log | awk '{print $7}' |
sed -r 's#\/topics\/([0-9]+)\/replies\/([0-9]+)\/edit#\/topics\/int\/replies\/int\/edit#g' |
sed -r 's#^\/.*\/photo\/([0-9]{4})\/.*#\/_img\/uploads\/photo\/2018\/id.png!large#g' |
sed -r 's#\/topics\/([0-9]+)#\/topics\/int#g' |
sort | uniq -c | sort -nr | head -10
}
‘’’
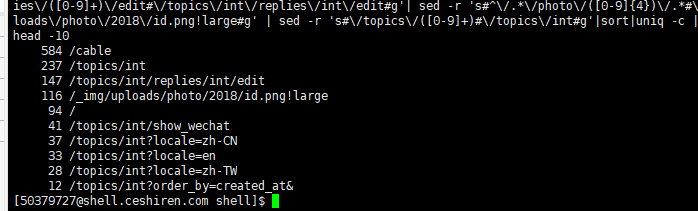
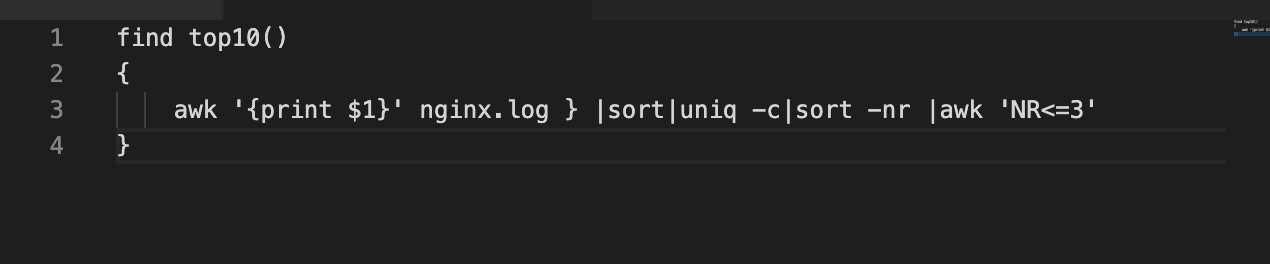
这个结果是0.0034215 ,是不对的,应该是0.0727979。大致的问题在于命令行中NR表示awk开始执行程序后所读取的数据行数,并不表示符合$7==’/’ 的行数,正确的应该是在首选过滤出首页的记录,再使用一次awk统计NR。

一、find_error_log
编写一个函数 find_error_log()
找出log中的404 500的报错
方法一:
find_error_log1(){
less nginx.log|grep -E '(" 404 |" 500)'
}
方法二:(这个方法比较好)
find_error_log(){
less nginx.log|awk '$9~/404|500/'
}
二、find_top_3
找出访问量最高的ip, 统计分析,取出top3的ip和数量,打印出来。把函数和执行结果贴到回复里。记得使用代码格式化
find_top_3(){
less nginx.log|awk '{print$1}'|sort|uniq -c|sort -nr|head -3
}
三、url_avg_time
找出首页访问 / 的平均响应时间,把函数与结果打印出来贴到回复里
首页访问示例,get后面的地址是/,每次访问的响应时间是倒数第二个字段
136.243.151.90 - - [05/Dec/2018:00:00:51 +0000] "GET / HTTP/1.1" 200 10088 "-" "Mozilla/5.0 (compatible; BLEXBot/1.0; +http://webmeup-crawler.com/)" 0.078 0.078 .
url_avg_time(){
less nginx.log|awk '$7=="/"'|awk '{sum+=$(NF-1)}END{print sum/NR}'
}
课后作业 url_summary
找出访问量最高的页面地址 借助于sed的统计分析
- /topics/16689/replies/124751/edit 把数字替换为 /topics/ int /replies/ int /edit
- /_img/uploads/photo/2018/c54755ee-6bfd-489a-8a39-81a1d7551cbd.png!large 变成 /_img
/uploads/photo/2018/ id .png!large - /topics/9497 改成 /topics/ int
- 其他规则参考如上
输出
- url pattern对应的请求数量
- 取出top 10请求量的url pattern
类似
288 url1
3000 url2
url_summary(){
}


请问:这行 sed ‘s/([0-9][0-9]/).(.jpg)/\1id\2/g’ |
能稍微解释下吗?
不是很清楚这行的具体是怎么执行的
老师,想问一下:
less nginx.log | awk ‘$9~/404|500/’
$9后面的”~“ 符号的作用是什么?以及后面404和500的两边为什么要带上”/”这个符号?
这是正则匹配的用法 ~表示使用正则匹配模式,/ /内的内容表示里面的内容正则表达式
好的,了解了,谢谢老师答疑
课后作业:
url_summary(){
less nginx.log | awk '{print $7}' | \
sed 's#s/[0-9]*#s/int#g' | \
sed 's/\([0-9][0-9]*\/\).*\(.jpg\)/\1id\2/g' | \
sed 's/\([0-9][0-9]*\/\).*\(.png\)/\1id\2/g' | \
sed 's/\([0-9][0-9]*\/\).*\(.gif\)/\1id\2/g' | \
sed 's/\([0-9][0-9]*\/\).*\(.jpeg\)/\1id\2/g' | \
sort | uniq -c | sort -nr | head -10
}课堂练习1:
find_error_log() {
less nginx.log | awk '$9~/404|500/'
}
课堂练习2:
find_top3() {
less nginx.log | awk '{print $1}' | sort |uniq -c | sort -nr | head -3
}
课堂练习3:
url_avg_time() {
less nginx.log | awk '$7 == "/"' | awk '{ sum += $(NF-1)} END {print sum/NF}'
}