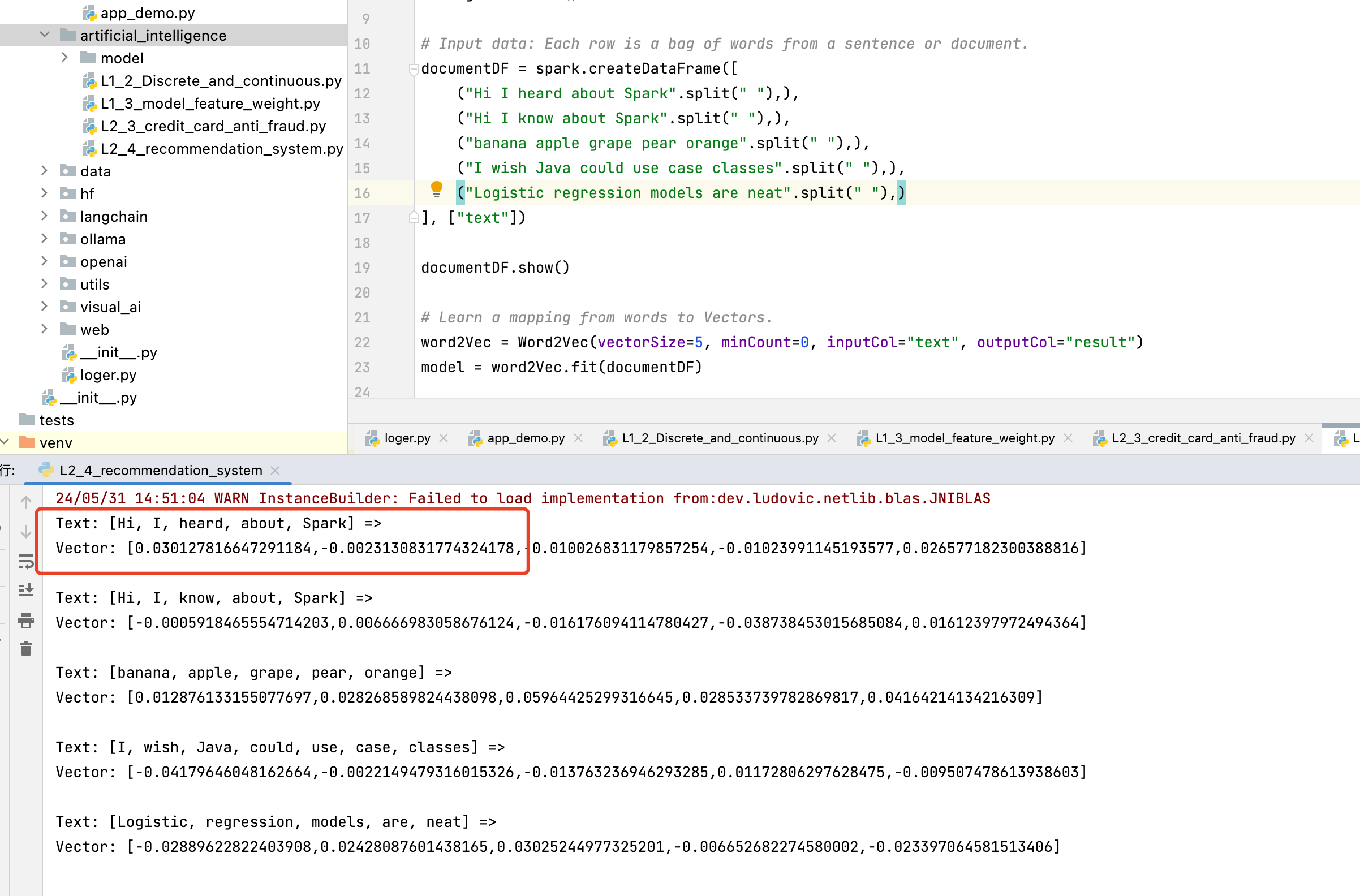
“上面是一个训练词向量的代码,它的计算原理大概可以描述为:在文本中选取中心词并选取中心词前后数个单词,并训练出这些词会出现在中心词周围的概率。 ”
可以理解为text中选出了某一个词做中心词,其他词和它比较的向量值为vector?
结果都比较低,接近于0,原点,可以怎么理解,相近还是不相近?
一个vector对应一个词的向量值?那么如果是自己和自己本身的比较,值也不高,没有接近1的,是因为,比较的不是相似性,而是前后出现的可能性?
可以用代码显示出这一次比较,选中的中心词是什么吗?
对于一批数据来说, 中心词是一样的。 一般训练的时候都会选择中心词的数量, 比如常用的是512维的词向量, 就可以理解为是512个中心词。 然后词表中每个词都会跟这512个中心词计算一个关联程度。 所以叫词向量么, 每个词都会被转成512的向量
可以理解越接近1越相近
