问题
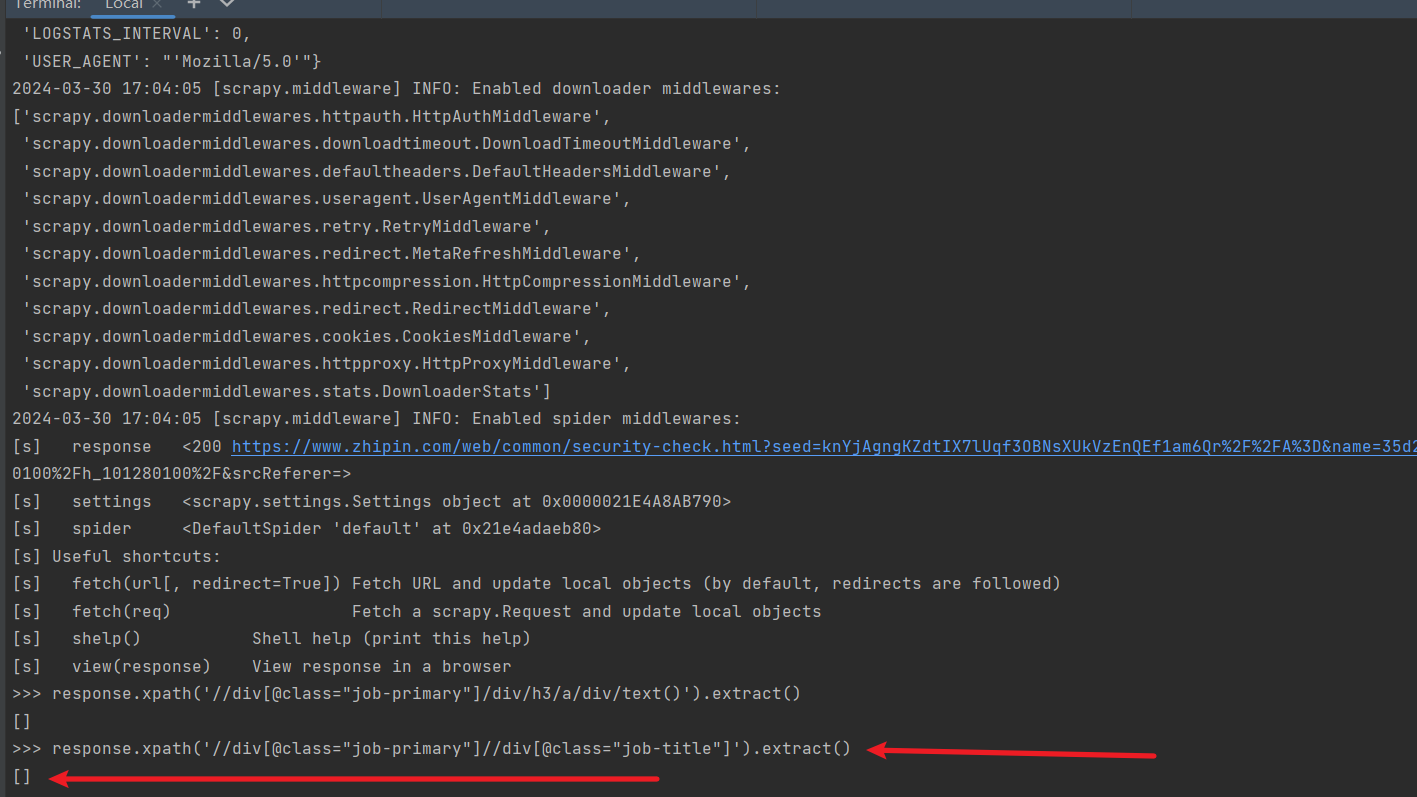
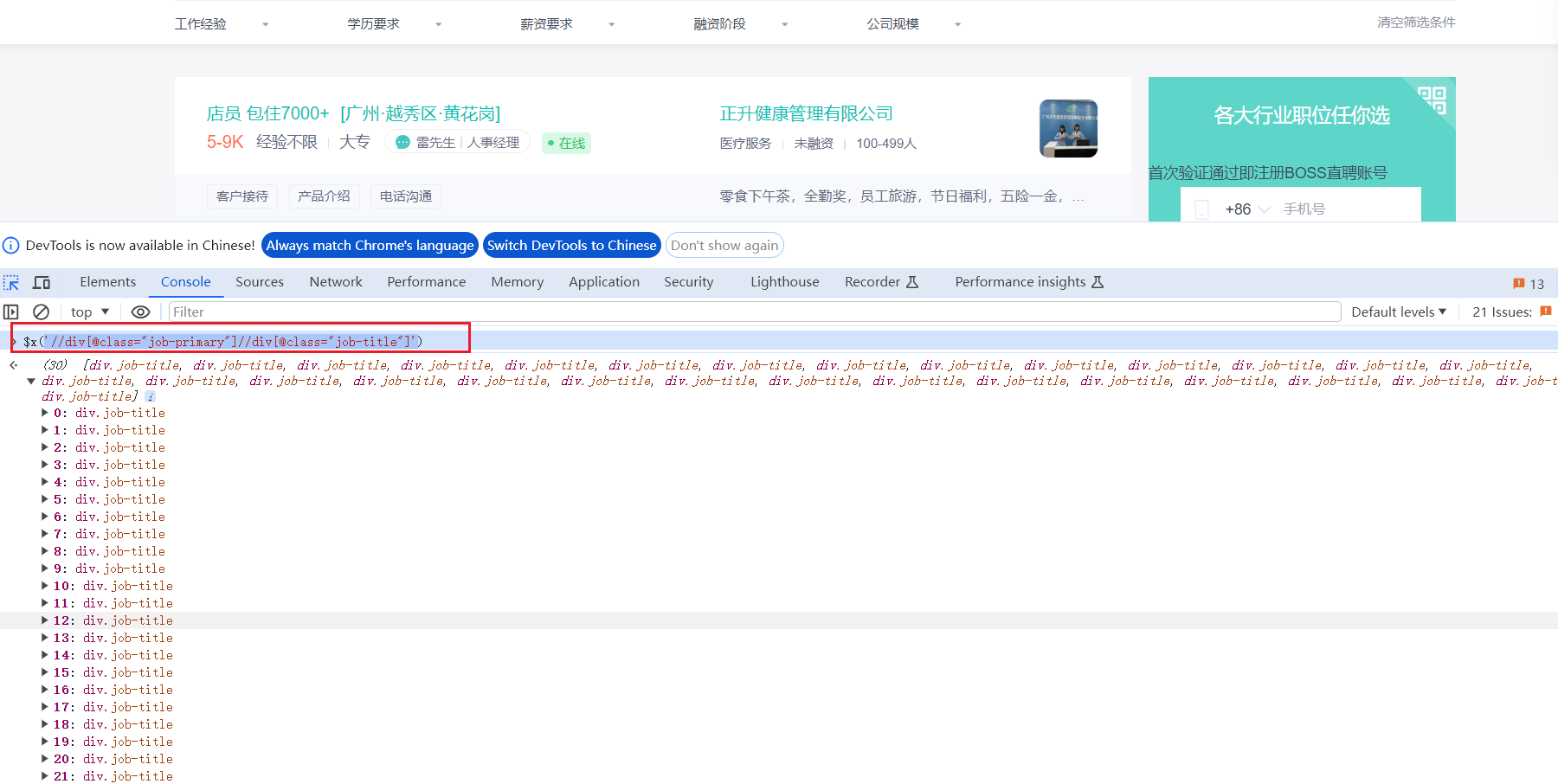
在使用scrapy框架提供的爬虫功能时,通过 在命令行中执行:scrapy shell -s USER_AGENT=‘Mozilla/5.0’ https://www.zhipin.com/c101280100/h_101280100/获取响应信息后,在返回的shell命令窗口执行response.xpath(‘//div[@class=“job-primary”]//div[@class=“job-title”]’).extract()获取指定页面信息时获取为空列表,但是实际通过在浏览器的consloe命令行下执行xpath定位:'//div[@class=“job-primary”]//div[@class=“job-title”]'是能正常获取到定位的数据值信息,请问下为啥在shell中执行获取的是空列表?跪求大佬解惑,感谢