什么时候可以做UI自动化测试
- 业务流程不频繁改动
- UI 元素不频繁改动
- 需要频繁回归的场景
- 核心场景等
Driver的下载与配置步骤
- 下载浏览器对应的driver,谷歌浏览器和火狐浏览器选一个即可。
- 配置 driver 的环境变量
- 重启命令行工具,验证是否配置成功
1. chromedriver的下载-Windows
- chromedriver的下载
- 确定与浏览器匹配的driver版本
- 根据使用的操作系统下载相应的 chromedriver
- 淘宝镜像:
2. chromedriver 环境变量配置-Windows
- Windows详细配置步骤:
3. 验证配置chromedriver是否成功-Windows
- 重启命令行,输入:
chromedriver --version - 出现chromedriver版本信息则配置成功
geckodriver 配置-Windows
- 下载geckodriver。
- 没有chromedriver类似的对应关系,默认下载最新的driver版本
- 根据使用的操作系统下载相应的 geckodriver
- 淘宝镜像:CNPM Binaries Mirror
- 配置步骤与谷歌浏览器的相同。
- 输入
geckodriver --version,验证是否配置成功。
在 python 中的使用
# 导入selenium 包
from selenium import webdriver
# 创建一个 Chromdriver 的实例。Chrome()会从环境变量中寻找浏览器驱动
driver = webdriver.Chrome()
# 打开网址
driver.get("https://www.baidu.com/")
# 关闭driver
driver.quit()
- 火狐浏览器演示
# 导入selenium 包
from selenium import webdriver
# 创建一个 Geckodriver 的实例。Firefox()会从环境变量中寻找浏览器驱动
driver = webdriver.Firefox()
# 打开网址
driver.get("https://www.baidu.com/")
# 关闭driver
driver.quit()
用例结构对比
自动化测试用例 作用
用例标题 测试包、文件、类、方法名称 用例的唯一标识
前提条件 setup、setup_class(Pytest);
BeforeEach、BeforeAll(JUnit) 测试用例前的准备动作,比如读取数据或者driver的初始化
用例步骤 测试方法内的代码逻辑 测试用例具体的步骤行为
预期结果 assert 实际结果 = 预期结果 断言,印证用例是否执行成功
实际结果 assert 实际结果 = 预期结果 断言,印证用例是否执行成功
后置动作 teardown、teardown_class(Pytest);
@AfterEach、@AfterAll(JUnit) 脏数据清理、关闭driver进程
脚本优化
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestDemo01():
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
def test_demo01(self):
# 访问网站
self.driver.get("https://www.baidu.com/")
# 设置窗口
self.driver.set_window_size(1330, 718)
# 点击输入框
self.driver.find_element(By.ID, "kw").click()
# 输入框输入信息
self.driver.find_element(By.ID, "kw").send_keys("霍格沃兹测试开发")
# 点击搜索按钮
self.driver.find_element(By.ID, "su").click()
# 等待界面加载
time.sleep(5)
# 元素定位后获取文本信息
res = self.driver.find_element(By.XPATH, "//*[@id='1']/h3/a").get_attribute("text")
# 打印文本信息
print(res)
# 添加断言
assert "霍格沃兹测试开发" in res
# 查看界面展示
time.sleep(5)
web 浏览器控制
浏览器控制
- 模拟功能测试中对浏览器的操作
||操作|使用场景|
| — | — | — |
|get|打开浏览器|web自动化测试第一步|
|refresh|浏览器刷新|模拟浏览器刷新|
|back|浏览器退回|模拟退回步骤|
|maximize_window|最大化浏览器|模拟浏览器最大化|
|minimize_window|最小化浏览器|模拟浏览器最小化|
打开网页
- get方法打开浏览器
from selenium import webdriver
import time
def window_start():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get('http://www.ceshiren.com')
# 等待一秒
time.sleep(1)
if __name__ == '__main__':
window_start()
刷新
- refresh方法刷新页面
from selenium import webdriver
import time
def window_refresh():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get('http://www.ceshiren.com')
# 等待一秒
time.sleep(1)
# 刷新网页
driver.refresh()
# 等待一秒
time.sleep(1)
if __name__ == '__main__':
window_refresh()
回退
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
def window_back():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get('http://www.ceshiren.com')
# 等待一秒
time.sleep(1)
driver.find_element(By.XPATH,"//*[@id='ember35']").click()
# 等待一秒
time.sleep(1)
# 返回上一个界面
driver.back()
# 等待一秒
time.sleep(1)
if __name__ == '__main__':
window_back()
最大化
- maximize_window方法使窗口最大化
def max_window():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get('http://www.ceshiren.com')
# 等待一秒
time.sleep(1)
# 屏幕最大化
driver.maximize_window()
# 等待一秒
time.sleep(1)
if __name__ == '__main__':
max_window()
最小化
- minimize_window方法使窗口最小化
from selenium import webdriver
import time
def min_window():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get('http://www.ceshiren.com')
# 等待一秒
time.sleep(1)
# 屏幕最小化
driver.minimize_window()
# 等待一秒
time.sleep(1)
if __name__ == '__main__':
min_window()
常见控件定位方法
HTML铺垫
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>测试人论坛</title>
</head>
<body>
<a href="https://ceshiren.com/" class="link">链接</a>
</body>
</html>
- 标签:
<a> - 属性:href
- 类属性: class
Selenium定位方式
Selenium提供了八种定位方式:Locator strategies | Selenium
| 方式 | 描述 |
|---|---|
| class name | class 属性对应的值 |
| css selector(重点) | css 表达式 |
| id(重点) | id 属性对应的值 |
| name(重点) | name 属性对应的值 |
| link text | 查找其可见文本与搜索值匹配的锚元素 |
| partial link text | 查找其可见文本包含搜索值的锚元素。如果多个元素匹配,则只会选择第一个元素。 |
| tag name | 标签名称 |
| xpath(重点) | xpath表达式 |
selenium 常用定位方式
# 示例,两种方式作用一模一样
# 官方建议使用下面的方式
driver.find_element_by_id("su")
driver.find_element(By.ID, "su")
通过 id 定位
- 格式:
driver.find_element(By.ID, "ID属性对应的值")
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
def id_position_method():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get('http://www.ceshiren.com')
# 等待一秒
time.sleep(1)
# 点击“精华帖”
driver.find_element(By.ID,"ember35").click()
# 等待两秒
time.sleep(2)
if __name__ == '__main__':
id_position_method()
name 定位
- 格式:
driver.find_element(By.NAME, "Name属性对应的值")
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
def name_position_method():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get('http://www.baidu.com')
# 等待一秒
time.sleep(1)
# 点击更多
driver.find_element(By.NAME,"tj_briicon").click()
# 等待两秒
time.sleep(2)
if __name__ == '__main__':
name_position_method()
css selector 定位
- 格式:
driver.find_element(By.CSS_SELECTOR, "css表达式") - 复制绝对定位
- 编写 css selector 表达式(后面章节详细讲解)
xpath 定位
- 格式:
driver.find_element(By.XPATH, "xpath表达式") - 复制绝对定位
- 编写 xpath 表达式(后面章节详细讲解)
link 定位
- 格式:
driver.find_element(By.LINK_TEXT,"文本信息")
强制等待与隐式等待
为什么要添加等待
- 避免页面未渲染完成后操作,导致的报错
from selenium import webdriver
from selenium.webdriver.common.by import By
def wait_sleep():
"""
如果直接执行,不添加任何等待,可能会报错
"""
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/")
# 不加等待,可能会因为网速等原因产生报错
driver.find_element(By.XPATH, "//*[text()='个人中心']")
if __name__ == '__main__':
wait_sleep()
直接等待
- 解决方案:在报错的元素操作之前添加等待
- 原理:强制等待,线程休眠一定时间
- 演练环境:https://vip.ceshiren.com/
time.sleep(3)
隐式等待
- 问题:难以确定元素加载的具体等待时间。
- 解决方案:针对于寻找元素的这个动作,使用隐式等待添加配置。
- 演练环境:https://vip.ceshiren.com/
- 原理:设置一个等待时间,轮询查找(默认0.5秒)元素是否出现,如果没出现就抛出异常
#设置一个等待时间,轮询查找(默认0.5秒)元素是否出现,如果没出现就抛出异常
driver.implicitly_wait(3)
隐式等待无法解决的问题
元素可以找到,使用点击等操作,出现报错
原因:
页面元素加载是异步加载过程,通常html会先加载完成,js、css其后
元素存在与否是由HTML决定,元素的交互是由css或者js决定
隐式等待只关注元素能不能找到,不关注元素能否点击或者进行其他的交互
解决方案:使用显式等待
显式等待基本使用(初级)
- 示例:
WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件) - 原理:在最长等待时间内,轮询,是否满足结束条件
- 演练环境: 霍格沃兹测试开发
- 注意:在初级时期,先关注使用
def wait_until():
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/#/ui_study")
WebDriverWait(driver, 10).until(
expected_conditions.element_to_be_clickable(
(By.CSS_SELECTOR, '#success_btn')))
driver.find_element(By.CSS_SELECTOR, "#success_btn").click()
总结
| 类型 | 使用方式 | 原理 | 适用场景 |
|---|---|---|---|
| 直接等待 | time.sleep(等待时间)) | 强制线程等待 | 调试代码,临时性添加 |
| 隐式等待 | driver.implicitly_wait(等待时间) | 在时间范围内,轮询查找元素 | 解决找不到元素问题,无法解决交互问题 |
| 显式等待 | WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件) | 设定特定的等待条件,轮询操作 | 解决特定条件下的等待问题,比如点击等交互性行为 |
常见控件交互方法
点击,输入,清空
- 点击百度搜索框
- 输入”霍格沃兹测试开发”
- 清空搜索框中信息
- 演练地址: https://www.baidu.com/
# 点击百度搜索框
driver.find_element(By.ID,"kw").click()
# 输入"霍格沃兹测试开发"
driver.find_element(By.ID,"kw").send_keys("霍格沃兹测试开发")
# 清空搜索框中信息
driver.find_element(By.ID,"kw").clear()
获取元素属性信息
- 原因:
- 定位到元素后,获取元素的文本信息,属性信息等
- 目的:
- 根据这些信息进行断言或者调试
- 演练地址: 霍格沃兹测试开发
获取元素属性信息的方法
- 获取元素文本
- 获取元素的属性(html的属性值)
获取元素文本
driver.find_element(By.ID, “id”).text
获取这个元素的name属性的值
driver.find_element(By.ID, “id”).get_attribute(“name”)
自动化测试定位策略
- 不知道应该使用哪种定位方式?
- 元素定位不到无法解决?
选择定位器通用原则
-
与研发约定的属性优先(class属性:
[name='locate']) -
身份属性 id,name(web 定位)
-
复杂场景使用组合定位:
- xpath,css
- 属性动态变化(id,text)
- 重复元素属性(id,text,class)
- 父子定位(子定位父)
- js定位
Web 弹框定位
- 场景
- web 页面 alert 弹框
- 解决:
- web 需要使用
driver.switchTo().alert()处理
- web 需要使用
下拉框/日期控件定位
- 场景:
-
<input>标签组合的下拉框无法定位 -
<input>标签组合的日期控件无法定位
-
- 解决:
- 面对这些元素,我们可以引入 JS 注入技术来解决问题。
文件上传定位
- 场景:
- input 标签文件上传
- 解决:
- input 标签直接使用 send_keys()方法
高级定位-css
css 定位场景
- 支持web产品
- 支持app端的webview
css 相对定位的优点
- 可维护性更强
- 语法更加简洁
- 解决各种复杂的定位场景
# 绝对定位
$("#ember63 > td.main-link.clearfix.topic-list-data > span > span > a")
# 相对定位
$("#ember63 [title='新话题']")
css 定位的调试方法
- 进入浏览器的console
- 输入:
$("css表达式")- 或者
$("css表达式")
css基础语法
| 类型 | 表达式 |
|---|---|
| 标签 | 标签名 |
| 类 | .class属性值 |
| ID | #id属性值 |
| 属性 | [属性名=‘属性值’] |
//在console中的写法
// https://www.baidu.com/
//标签名
$('input')
//.类属性值
$('.s_ipt')
//#id属性值
$('#kw')
//[属性名='属性值']
$('[name="wd"]')
css关系定位
| 类型 | 格式 |
|---|---|
| 并集 | 元素,元素 |
| 邻近兄弟(了解即可) | 元素+元素 |
| 兄弟(了解即可) | 元素1~元素2 |
| 父子 | 元素>元素 |
| 后代 | 元素 元素 |
//在console中的写法
//元素,元素
$('.bg,.s_ipt_wr,.new-pmd,.quickdelete-wrap')
//元素>元素
$('#s_kw_wrap>input')
//元素 元素
$('#form input')
//元素+元素,了解即可
$('.soutu-btn+input')
//元素1~元素2,了解即可
$('.soutu-btn~i')
css 顺序关系
| 类型 | 格式 |
|---|---|
| 父子关系+顺序 | 元素 元素 |
| 父子关系+标签类型+顺序 | 元素 元素 |
//:nth-child(n)
$('#form>input:nth-child(2)')
//:nth-of-type(n)
$('#form>input:nth-of-type(1)')
高级定位-xpath
xpath 定位场景
- web自动化测试
- app自动化测试
xpath 相对定位的优点
- 可维护性更强
- 语法更加简洁
- 相比于css可以支持更多的方式
# 复制的绝对定位
$x('//*[@id="ember75"]/td[1]/span/a')
# 编写的相对行为
$x("//*[text()='技术分享 | SeleniumIDE用例录制']")
xpath 定位的调试方法
- 浏览器-console
$x("xpath表达式")
- 浏览器-elements
- ctrl+f 输入xpath或者css
xpath 基础语法(包含关系)
| 表达式 | 结果 |
|---|---|
| / | 从该节点的子元素选取 |
| // | 从该节点的子孙元素选取 |
| * | 通配符 |
| nodename | 选取此节点的所有子节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
整个页面
$x(“/”)
页面中的所有的子元素
$x(“/*”)
整个页面中的所有元素
$x(“//*”)
查找页面上面所有的div标签节点
$x(“//div”)
查找id属性为site-logo的节点
$x(‘//*[@id=“site-logo”]’)
查找节点的父节点
$x(‘//*[@id=“site-logo”]/…’)
xpath 顺序关系(索引)
- xpath通过索引直接获取对应元素
获取此节点下的所有的li元素
$x(“//*[@id=‘ember21’]//li”)
获取此节点下【所有的节点的】第一个li元素
$x(“//*[@id=‘ember21’]//li[1]”)
xpath 高级用法
-
[last()]: 选取最后一个 -
[@属性名='属性值' and @属性名='属性值']: 与关系 -
[@属性名='属性值' or @属性名='属性值']: 或关系 -
[text()='文本信息']: 根据文本信息定位 -
[contains(text(),'文本信息')]: 根据文本信息包含定位 - 注意:所有的表达式需要和
[]结合
# 选取最后一个input标签
//input[last()]
# 选取属性name的值为passward并且属性pwd的值为123456的input标签
//input[@name='passward' and @pwd='123456']
# 选取属性name的值为passward或属性pwd的值为123456的input标签
//input[@name='passward' or @pwd='123456']
# 选取所有文本信息为'霍格沃兹测试开发'的元素
//*[text()='霍格沃兹测试开发']
# 选取所有文本信息包'霍格沃兹'的元素
//*[contains(text(),'霍格沃兹')]
显式等待高级使用
显示等待原理
- 在代码中定义等待一定条件发生后再进一步执行代码
- 在最长等待时间内循环执行结束条件的函数
- WebDriverWait(driver 实例, 最长等待时间, 轮询时间).until(结束条件函数)

显示等待-expected_conditions
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
def wait_until():
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/#/ui_study")
WebDriverWait(driver, 10).until(
expected_conditions.element_to_be_clickable(
(By.CSS_SELECTOR, '#success_btn')))
driver.find_element(By.CSS_SELECTOR, "#success_btn").click()
常见 expected_conditions
| 类型 | 示例方法 | 说明 |
|---|---|---|
| element | element_to_be_clickable() | |
| visibility_of_element_located() | 针对于元素,比如判断元素是否可以点击,或者元素是否可见 | |
| url | url_contains() | 针对于 url |
| title | title_is() | 针对于标题 |
| frame | frame_to_be_available_and_switch_to_it(locator) | 针对于 frame |
| alert | alert_is_present() | 针对于弹窗 |
显式等待-封装等待条件
- 官方的 excepted_conditions 不可能覆盖所有场景
- 定制封装条件会更加灵活、可控
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.support.wait import WebDriverWait
class TestWebdriverWait:
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(5)
driver.get("https://vip.ceshiren.com/#/ui_study")
def teardown(self):
self.driver.quit()
def test_webdriver_wait(self):
# 解决的问题:有的按钮点击一次没有反应,可能要点击多次,比如企业微信的添加成员
# 解决的方案:一直点击按钮,直到下个页面出现,封装成显式等待的一个条件
def muliti_click(button_element,until_ele):
# 函数封装
def inner(driver):
# 封装点击方法
driver.find_element(By.XPATH,button_element).click()
return driver.find_element(By.XPATH,until_ele)
return inner
time.sleep(5)
# 在限制时间内会一直点击按钮,直到展示弹框
WebDriverWait(self.driver,10).until(muliti_click("//*[text()='点击两次响应']","//*[text()='该弹框点击两次后才会弹出']"))
time.sleep(5)
高级控件交互方法
使用场景
| 使用场景 | 对应事件 |
|---|---|
| 复制粘贴 | 键盘事件 |
| 拖动元素到某个位置 | 鼠标事件 |
| 鼠标悬停 | 鼠标事件 |
| 滚动到某个元素 | 滚动事件 |
| 使用触控笔点击 | 触控笔事件(了解即可) |
ActionChains解析
- 实例化类ActionChains,参数为driver实例。
- 中间可以有多个操作。
-
.perform()代表确定执行。
ActionChains(self.driver).操作.perform()
键盘事件
- 按下、释放键盘键位
- 结合send_keys回车
键盘事件-使用shift实现大写
-
ActionChains(self.driver): 实例化ActionChains类 -
key_down(Keys.SHIFT, ele): 按下shift键实现大写 -
send_keys("selenium"): 输入大写的selenium -
perform(): 确认执行
class TestKeyBoardDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_key_down_up(self):
# 演练环境
self.driver.get("https://ceshiren.com/")
self.driver.find_element(By.ID, "search-button").click()
ele = self.driver.find_element(By.ID, "search-term")
ActionChains(self.driver).key_down(Keys.SHIFT, ele).\
send_keys("selenium").perform()
键盘事件-输入后回车
- 直接输入回车: 元素.send_keys(Keys.ENTER)
- 使用ActionChains: key_down(Keys.ENTER)
class TestKeyBoardDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_enter(self):
# 演练环境
self.driver.get("https://www.sogou.com/")
ele = self.driver.find_element(By.ID, "query")
ele.send_keys("selenium")
# 第一种方式
ele.send_keys(Keys.ENTER)
# 第二种方式
# ActionChains(self.driver).\
# key_down(Keys.ENTER).\
# perform()
time.sleep(3)
键盘事件-复制粘贴
- 多系统兼容
- mac 的复制按钮为 COMMAND
- windows 的复制按钮为 CONTROL
- 左箭头:
Keys.ARROW_LEFT - 按下COMMAND或者CONTROL:
key_down(cmd_ctrl) - 按下剪切与粘贴按钮:
send_keys("xvvvvv")
class TestKeyBoardDemo:
# driver 初始化
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
# 关闭driver进程
def teardown_class(self):
self.driver.quit()
# 复制粘贴逻辑
def test_copy_and_paste(self):
# 演练环境
self.driver.get("https://ceshiren.com/")
cmd_ctrl = Keys.COMMAND if sys.platform == 'darwin' else Keys.CONTROL
self.driver.find_element(By.ID, "search-button").click()
ele = self.driver.find_element(By.ID, "search-term")
# 打开搜索,选择搜索框,输入selenium,剪切后复制,几个v就代表复制几次
ActionChains(self.driver)\
.key_down(Keys.SHIFT, ele)\
.send_keys("Selenium!")\
.send_keys(Keys.ARROW_LEFT)\
.key_down(cmd_ctrl)\
.send_keys("xvvvvv")\
.key_up(cmd_ctrl)\
.perform()
time.sleep(5)
鼠标事件
- 双击
- 拖动元素
- 指定位置(悬浮)
鼠标事件-双击
-
double_click(元素对象): 双击元素
class TestMouseDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_double_click(self):
# 演练环境
self.driver.get("https://vip.ceshiren.com/#/ui_study")
ele = self.driver.find_element(By.ID, "primary_btn")
ActionChains(self.driver).double_click(ele).perform()
time.sleep(2)
鼠标事件-拖动元素
-
drag_and_drop(起始元素对象, 结束元素对象): 拖动并放开元素
class TestMouseDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_drag_and_drop(self):
# 演练环境
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains")
item_left = self.driver.find_element(By.CSS_SELECTOR,'#item1')
item_right = self.driver.find_element(By.CSS_SELECTOR,'#item3')
ActionChains(self.driver).drag_and_drop(item_left, item_right).perform()
time.sleep(5)
鼠标事件-悬浮
-
move_to_element(元素对象): 移动到某个元素
class TestMouseDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_hover(self):
# 演练环境
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains2")
time.sleep(2)
title = self.driver.find_element(By.CSS_SELECTOR, '.title')
ActionChains(self.driver).move_to_element(title).perform()
options = self.driver.find_element(By.CSS_SELECTOR,'.options>div:nth-child(1)')
ActionChains(self.driver).click(options).perform()
time.sleep(5)
滚轮/滚动操作
- 滚动到元素
- 根据坐标滚动
- 注意: selenium 版本需要在 4.2 之后
滚轮/滚动操作-滚动到元素
-
scroll_to_element(WebElement对象):滚动到某个元素
class TestScrollDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_scoll_to_element(self):
# 演练环境
self.driver.get("https://ceshiren.com/")
# 4.2 之后才提供这个方法
ele = self.driver.find_element\
(By.XPATH, "//*[text()='怎么写高可用集群部署的测试方案?']")
ActionChains(self.driver).scroll_to_element(ele).perform()
time.sleep(5)
滚轮/滚动操作-根据坐标滚动
scroll_by_amount(横坐标, 纵坐标)
class TestScrollDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_scroll_to_amount(self):
# 演练环境
self.driver.get("https://ceshiren.com/")
# 4.2 之后才提供这个方法
ActionChains(self.driver).scroll_by_amount(0, 10000).perform()
time.sleep(5)
#多窗⼜处理与⽹页frame
自动化关键数据记录
什么是关键数据
- 代码的执行日志
- 代码执行的截图
- page source(页面源代码)
记录关键数据的作用
| 内容 | 作用 |
|---|---|
| 日志 | 1. 记录代码的执行记录,方便复现场景 |
- 可以作为bug依据|
|截图|1. 断言失败或成功截图
2.异常截图达到丰富报告的作用 - 可以作为bug依据|
|page source|1. 协助排查报错时元素当时是否存在页面上|
行为日志记录
- 日志配置
- 脚本日志级别
- debug记录步骤信息
- info记录关键信息,比如断言等
行为日志记录
# 日志配置
import logging
# 创建logger实例
logger = logging.getLogger('simple_example')
# 设置日志级别
logger.setLevel(logging.DEBUG)
# 流处理器
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 日志打印格式
formatter = logging.Formatter\
('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 添加格式配置
ch.setFormatter(formatter)
# 添加日志配置
logger.addHandler(ch)
# 日志与脚本结合
class TestDataRecord:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_log_data_record(self):
# 实例化self.driver
search_content = "霍格沃兹测试开发"
# 打开百度首页
self.driver.get("https://www.sogou.com/")
logger.debug("打开搜狗首页")
# 输入霍格沃兹测试学院
self.driver.find_element(By.CSS_SELECTOR, "#query").\
send_keys(search_content)
logger.debug(f"搜索的内容为{search_content}")
# 点击搜索
self.driver.find_element(By.CSS_SELECTOR, "#stb").click()
# 搜索结果
search_res = self.driver.find_element(By.CSS_SELECTOR, "em")
logger.info(f"搜索结果为{search_res.text}")
assert search_res.text == search_content
步骤截图记录
save_screenshot(截图路径+名称)- 记录关键页面
- 断言页面
- 重要的业务场景页面
- 容易出错的页面
# 调用save方法截图并保存保存在当前路径下的images文件夹下
driver.save_screenshot('./images/search1.png')
page_source记录
- 使用page_source属性获取页面源码
- 在调试过程中,如果有找不到元素的错误可以保存当时的page_source调试代码
# 在报错行前面添加保存page_source的操作
with open("record.html", "w", encoding="u8") as f:
f.write(self.driver.page_source)
Web自动化测试之复用浏览器
复用浏览器简介
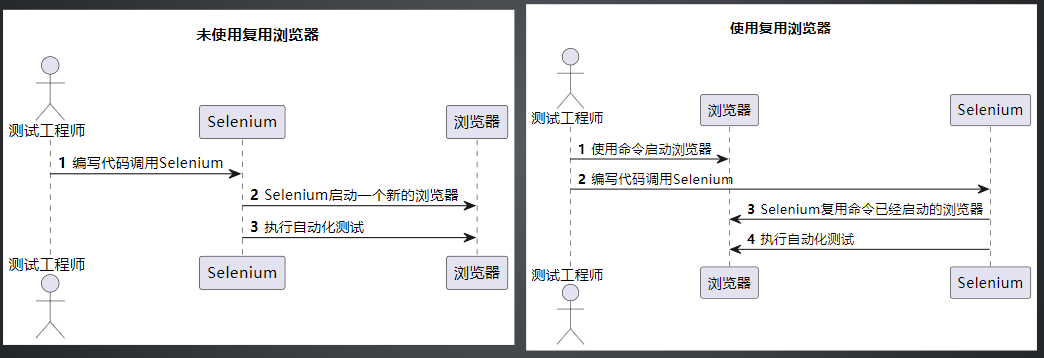
为什么要学习复用浏览器
- 自动化测试过程中,存在人为介入场景
- 提高调试UI自动化测试脚本效率
复用已有浏览器-配置步骤
- 需要退出当前所有的谷歌浏览器(特别注意)
- 输入启动命令,通过命令启动谷歌浏览器
- 找到 chrome 的启动路径(下一页 ppt)
- 配置环境变量(下一页 ppt)
- 验证是否启动成功
- windows:chrome –remote-debugging-port=9222
- mac:Google Chrome –remote-debugging-port=9222
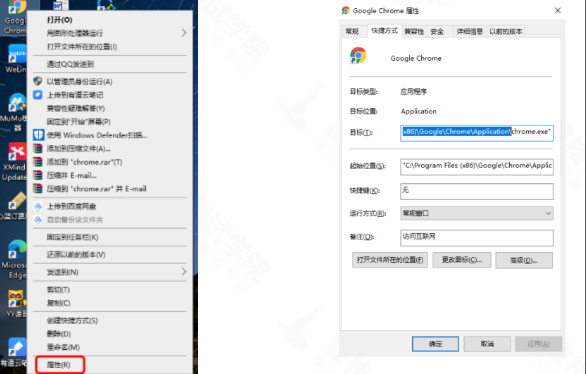
windows 环境变量配置:1. 获取启动路径
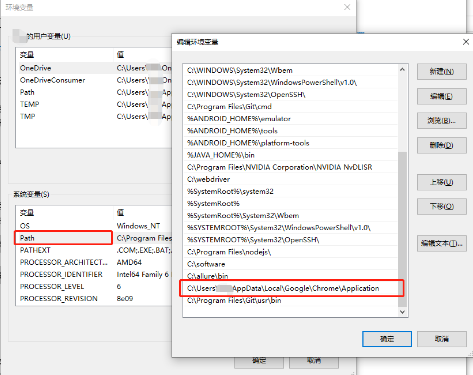
windows 环境变量配置:2. 配置环境变量
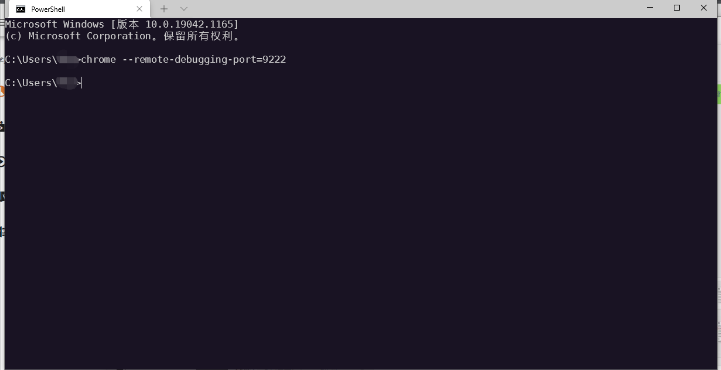
windows 环境变量配置:3. 重启命令行
windows关闭谷歌浏览器进程

复用已有浏览器-代码设置(Python)
from selenium.webdriver.chrome.options import Options
option = Options()
option.debugger_address = "localhost:9222"
self._driver = webdriver.Chrome(options=option)
self._driver.get("https://work.weixin.qq.com/wework_admin/frame")
复用浏览器实战演示1
- 问题1:企业微信登录无法通过输入用户名密码的方式解决登录问题,后面所有的脚本都无法执行。
- 解决方案: 通过remote复用浏览器人工登录企业微信。后面的脚本自动执行
复用浏览器实战演示2
- 问题2:编写自动化测试脚本过程中,用例的某一步骤出现问题。调试时需要将此步骤前面所有的步骤执行完成之后再复现调试。
- 解决方案:使用复用浏览器的方式跳过前面的自动化执行步骤,轻松复现出问题的场景,只对问题行代码进行调试。
Web自动化测试之Cookie登录
cookie 是什么
- Cookie 是一些认证数据信息,存储在电脑的浏览器上
- 当 web 服务器向浏览器发送 web 页面时,在连接关闭后,服务端不会记录用户的信息
为什么要使用Cookie自动化登录
- 复用浏览器仍然在每次用例开始都需要人为介入
- 若用例需要经常执行,复用浏览器则不是一个好的选择
- 大部分cookie的时效性都很长,扫一次可以使用多次
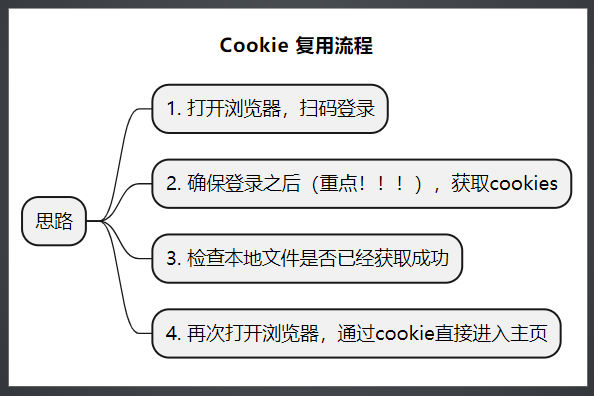
思路
常见问题
- 企业微信cookie有互踢机制。在获取cookie成功之后。不要再进行扫码操作!!!!
- 获取cookie的时候,即执行代码获取cookie时,一定要确保已经登录
- 植入cookie之后需要进入登录页面,刷新验证是否自动登录成功。
代码(Python)
- 获取 cookie
driver.get_cookies() - 添加 cookie
driver.add_cookie(cookie)
class TestCookieLogin:
def setup_class(self):
self.drvier = webdriver.Chrome()
def test_get_cookies(self):
# 1. 访问企业微信主页/登录页面
self.drvier.get("https://work.weixin.qq.com/wework_admin/frame#contacts")
# 2. 等待20s,人工扫码操作
time.sleep(20)
# 3. 等成功登陆之后,再去获取cookie信息
cookie = self.drvier.get_cookies()
# 4. 将cookie存入一个可持久存储的地方,文件
# 打开文件的时候添加写入权限
with open("cookie.yaml", "w") as f:
# 第一个参数是要写入的数据
yaml.safe_dump(cookie, f)
def test_add_cookie(self):
# 1. 访问企业微信主页面
self.drvier.get("https://work.weixin.qq.com/wework_admin/frame#contacts")
# 2. 定义cookie,cookie信息从已经写入的cookie文件中获取
cookie = yaml.safe_load(open("cookie.yaml"))
# 3. 植入cookie
for c in cookie:
self.drvier.add_cookie(c)
time.sleep(3)
# 4.再次访问企业微信页面,发现无需扫码自动登录,而且可以多次使用
self.drvier.get("https://work.weixin.qq.com/wework_admin/frame#contacts")
yaml相关依赖
<properties>
<!--对应解析-->
<jackson.version>2.13.1</jackson.version>
</properties>
<dependencies>
<!-- yaml文件解析-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-yaml</artifactId>
<version>${jackson.version}</version>
</dependency>
</dependencies>
selenium 多浏览器处理
多浏览器测试概述
- 是跨不同浏览器组合验证网站或 web 应用程序功能的过程
- 是兼容性测试的一个分支,用于保持功能和质量的一致性
- 适用于面向客户的网站和组织内部使用的站点
多浏览器的实现方案
pytest hook 函数
-
pytest_addoption添加命令行参数组/命令行参数 -
pytest_configure解析命令行选项,每个插件都会用到这个hook函数
pytest_addoption 与 pytest_configure
- pytest_addoption:
- parser.getgroup 创建/获取组名
- addoption 添加一个命令行选项
- pytest_configure:
- 通过config 对象的getoption()方法获取命令行参数
- 将命令行获取到的内容赋值给变量
pytest_addoption 与 pytest_configure代码示例
def pytest_addoption(parser):
# group 将下面所有的 option都展示在这个group下。
mygroup = parser.getgroup("hogwarts")
# 注册一个命令行选项
mygroup.addoption("--browser",
# 参数的默认值
default='Chrome',
# 存储的变量
dest='browser',
# 参数的描述信息
help='set your browser, \
such as:Chrome, Firefox, Headless...'
)
def pytest_configure(config):
browser = config.getoption("--browser", default='Chrome')
tmp = {"browser": browser}
global_env.append(tmp)
命令行参数处理
- 通过 pytest_addoption hook 函数,配置命令行参数
- 通过 pytest_configure 函数,接收命令行参数信息
- 将参数保存到变量中
global_env = {}
def pytest_addoption(parser):
# group 将下面所有的 option都展示在这个group下。
mygroup = parser.getgroup("hogwarts")
# 注册一个命令行选项
mygroup.addoption("--browser",
# 参数的默认值
default='Chrome',
# 存储的变量
dest='browser',
# 参数的描述信息
help='set your browser, \
such as:Chrome, Firefox, Headless...'
)
def pytest_configure(config):
browser = config.getoption("browser", default='Chrome')
browser_conf = {"browser": browser}
global_env.update(browser_conf)
测试代码
- 通过命令行执行测试用例:
pytest 测试用例文件.py --browser="浏览器名称" - 后续结合 jenkins 实现切换浏览器+持续集成
# test_args.py
from selenium import webdriver
from conftest import global_env
class TestArgs():
def setup(self):
self.browser = global_env.get("browser")
print(self.browser)
if self.browser == 'Firefox':
self.driver = webdriver.Firefox(executable_path="/path/to/geckodriver")
elif self.browser == 'Remote':
executor_url = "https://selenium-node.hogwarts.ceshiren.com/wd/hub"
capabilities = {"browserName": "chrome", "browserVersion": "99.0"}
self.driver = webdriver.Remote(command_executor=executor_url, desired_capabilities=capabilities)
else:
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(5)
self.driver.maximize_window()
def test_option(self):
print("用例")
执行JavaScript脚本
自动化测试中使用JavaScript脚本
使用场景:部分场景使用selenium原生方法无法解决
- 修改时间控件
- 滚动到某个元素
- 其他场景
JavaScript 使用思路
- 页面调试 js 脚本
- Selenium执行js
JavaScript调试方法
- 进入 console 调试
- js 脚本如果有返回值则会在浏览器返回
JS 脚本-元素操作
- 通过 css 查找元素
- 点击元素(对应click)
- input标签对应的值(对应send_keys)
- 元素的类属性
- 元素的文本属性
// 百度首页:https://www.baidu.com/
// 修改属性值
document.querySelector("#kw").value = "霍格沃兹测试学院"
// 点击操作
document.querySelector("#su").click()
// 淘宝首页: https://www.taobao.com/
// 修改元素的类属性
document.querySelector("#J_SiteNavMytaobao").className\
="site-nav-menu site-nav-mytaobao site-nav-multi-menu J_MultiMenu site-nav-menu-hover"
// 测试人首页:https://ceshiren.com/
// 获取元素内的文本信息
document.querySelector("#ember63").innerText
JS脚本滚动操作
- 页面滚动到底部
- 指定到滚动的位置
document.documentElement.scrollTop=10000
document.querySelector(‘css表达式’).scrollIntoView();
Selenium执行js
- Selenium执行js
- 调用执行js方法
- 在 js 语句中添加 return:代码可以获取js的执行结果
- 结合 find_element 方法
示例代码
直接执行
execute_script(“js脚本”)
获取js执行结果
execute_script(“return js脚本”)
js处理-案例1-展示下拉框
- 案例一:通过属性修改展示下拉框
- 打开淘宝首页https://www.taobao.com/
- 修改下拉框属性
- 点击悬浮框内的选项
def test_select_down():
driver = webdriver.Chrome()
driver.implicitly_wait(3) # 打开网址
driver.get("https://www.taobao.com/")
# 修改下拉框属性
sleep(1)
driver.execute_script('document.querySelector("#J_SiteNavMytaobao").'
'className="site-nav-menu site-nav-mytaobao '
'site-nav-multi-menu J_MultiMenu '
'site-nav-menu-hover"')
driver.find_element(By.XPATH, "//*[text()='已买到的宝贝']").click()
sleep(5)
driver.quit()
js处理-案例2-时间控件
- 案例二:通过属性修改时间控件的值
- 打开12306网站
- 修改时间控件值
- 打印出发日期
示例代码-Python
def test_data_time():
# 打开网址
driver = webdriver.Chrome()
driver.implicitly_wait(3)
driver.get("https://www.12306.cn/index/")
sleep(1)
# 修改出发日期
driver.execute_script('document.querySelector("#train_date").value="2022-12-22"')
sleep(1)
# 打印出发日期, 返回值的使用
train_data = driver.execute_script('return document.querySelector("#train_date").value')
print(train_data)
sleep(3)
selenium option 常用操作
headless无头浏览器使用
Options概述
- 是一个配置浏览器启动的选项类,用于自定义和配置Driver会话
- 常见使用场景:
- 设置无头模式:不会显示调用浏览器,避免人为干扰的问题。
- 设置调试模式:调试自动化测试代码(浏览器复用)
添加启动配置(arguments)-Python版本
- 无头模式:
--headless - 窗体最大化
start-maximized - 指定浏览器分辨率
window-size=1920x3000
from selenium import webdriver
from selenium.webdriver.common.by import By
def test_chrome_pref():
options = webdriver.ChromeOptions()
# 无头模式
options.add_argument('--headless')
# 窗体最大化
options.add_argument('start-maximized')
# 指定浏览器分辨率
options.add_argument('window-size=1920x3000')
driver = webdriver.Chrome(chrome_options=options)
# 打开测试人页面
driver.get("https://ceshiren.com/")
# 点击登录
login_button_text = driver.find_element(By.CSS_SELECTOR, ".login-button").text
print(login_button_text) #打印:登录
driver.quit()
capability 配置参数解析与分布式运行
capability概述
- Capabilities是WebDriver支持的标准命令之外的扩展命令(配置信息)
- 配置web驱动的属性,如浏览器名称、浏览器平台等。
- 结合Selenium Grid完成分布式、兼容性等测试
- 官网地址: https://www.selenium.dev/zh-cn/documentation/webdriver/capabilities/shared/
capability 使用示例-Python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
def test_ceshiren():
# 切换成 windows 就会报错
capabilities = {"browserName":"chrome","platformName":"mac"}
# 通过 desired_capabilities 添加配置信息
driver = webdriver.Chrome(desired_capabilities=capabilities)
driver.implicitly_wait(5)
driver.get("https://ceshiren.com/")
text = driver.find_element(By.CSS_SELECTOR, ".login-button").text
print(text) #打印:登录
time.sleep(30)
driver.quit()
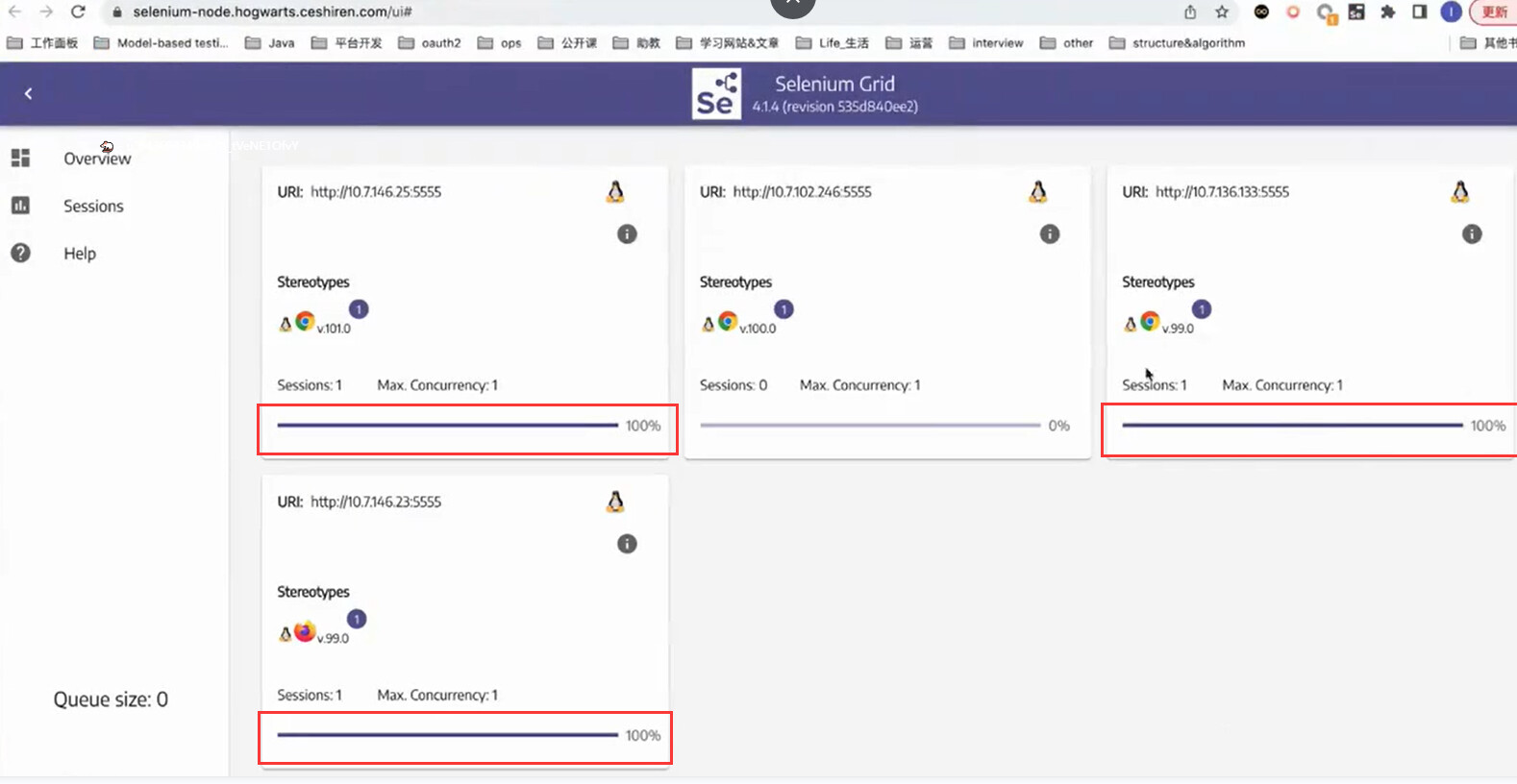
Selenium Grid
- elenium Grid 允许我们在多台机器上并行运行测试,并集中管理不同的浏览器版本和浏览器配置(而不是在每个单独的测试中)。
- 官网地址:Grid | Selenium
演示环境
- 学院搭建的演示环境:Selenium Grid
- (搭建教程会在 docker 章节讲解)
- 保证本地可以正常调通
- 实例化Remote()类并添加相应的配置
- 远程地址
- 设备配置
代码示例-Python
def test_ceshiren2():
hogwarts_grid_url = "https://selenium-node.hogwarts.ceshiren.com/wd/hub"
capabilities = {"browserName":"chrome","browserVersion":"101.0"}
# 配置信息
# 实例化Remote,获取可以远程控制的driver实例对象
# 通过 command_executor 配置selenium hub地址
# 通过 desired_capabilities 添加配置信息
driver = webdriver.Remote(
command_executor=hogwarts_grid_url,
desired_capabilities=capabilities)
driver.implicitly_wait(5)
driver.get("https://ceshiren.com/")
text = driver.find_element(By.CSS_SELECTOR, ".login-button").text
print(text)
time.sleep(3)
driver.quit()
Playwright 自动化测试框架
Playwright 简介
- Web 自动化测试框架。
- 跨平台多语言支持。
- 支持 Chromium、Firefox、WebKit 等主流浏览器自动化操作。
Playwright 的优点
- 支持所有流行的浏览器。
- 速度更快,更可靠的执行。
- 更强大的自动化测试配置。
- 强大的工具库:Codegen、Playwright inspector、Trace Viewer。
Playwright 与 selenium 对比
| 项目 | Playwright | Selenium |
|---|---|---|
| 是否需要驱动 | 否 | 需要对应浏览器 webdriver |
| 支持语言 | Java, Python, Javascript | Java, Python, Javascript, Ruby, C#等 |
| 支持浏览器 | Chrome、Firefox 等 | Chrome、Firefox 等 |
| 通讯方式 | websocket 双向通讯协议 | http 单向通讯协议 |
| 使用的测试框架 | 无限制(pytest,unittest) | 无限制(pytest,unittest) |
| 测试速度 | 快 | 慢 |
| 录制测试视频、快照 | 支持 | 支持 |
| 社区支持 | 微软 | thoughtworks 公司 |
Playwright 核心工具
- Codegen:通过记录你的操作来生成测试。 将它们保存为任何语言。
- Playwright inspector: 检查页面、生成选择器、逐步执行测试、查看点击点、探索执行日志。
- Trace Viewer:捕获所有信息以调查测试失败。 Playwright 跟踪包含测试执行截屏、实时 DOM 快照、动作资源管理器、测试源等等。
Playwright 环境安装
- 安装 playwright 插件
- pip install pytest-playwright
- 安装所需的浏览器
- playwright install
Codegen
设定展示窗口大小
playwright codegen --viewport-size=800,600 地址
指定设备
playwright codegen --device=“iPhone 11” 地址
Codegen-保存登录状态
- 场景:单点登录、验证码问题
保存登录状态
playwright codegen --save-storage=auth.json
加载认证信息
playwright codegen --load-storage=auth.json 地址
Playwright 常用API
| 常用API | 含义 |
|---|---|
| start() | 实例化playwright |
| chromium().launch() | 打开chrome浏览器 |
| new_page() | 打开一个窗口页面 |
| page.goto() | 跳转到某个地址 |
| page.locator(““) | 定位某个元素 |
| click() | 点击元素 |
| fill() | 输入内容 |
| keyboard().down() | 键盘事件 |
| screenshot() | 截图操作 |
Playwright 使用实例
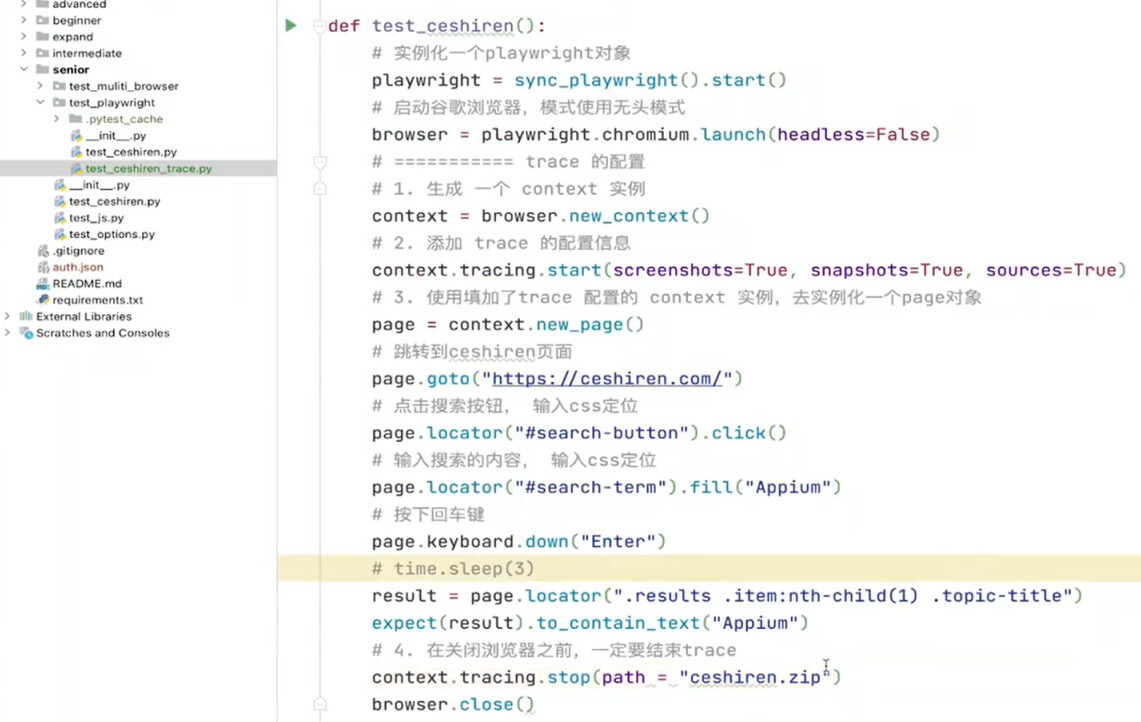
from playwright.sync_api import sync_playwright, expect
def test_playwright():
# 实例化playwright
playwright = sync_playwright().start()
# 打开chrome浏览器,headless默认是True,无头模式,这里设置为False方便查看效果
browser = playwright.chromium.launch(headless=False)
# 打开一个窗口页面
page = browser.new_page()
# 在当前窗口页面打开测试人网站
page.goto("https://ceshiren.com/")
# 定位搜索按钮并点击
page.locator("#search-button").click()
# 定位搜索框并输入web自动化
page.locator("#search-term").fill("web自动化")
# 使用keyboard.down模拟键盘的enter事件
page.keyboard.down("Enter")
# 断言搜索结果
result = page.locator(".list>li:nth-child(1) .topic-title>span")
expect(result).to_contain_text("自动化测试")
# 截图
page.screenshot(path='screenshot.png')
# 用例完成后先关闭浏览器
browser.close()
# 然后关闭playwright服务
playwright.stop()
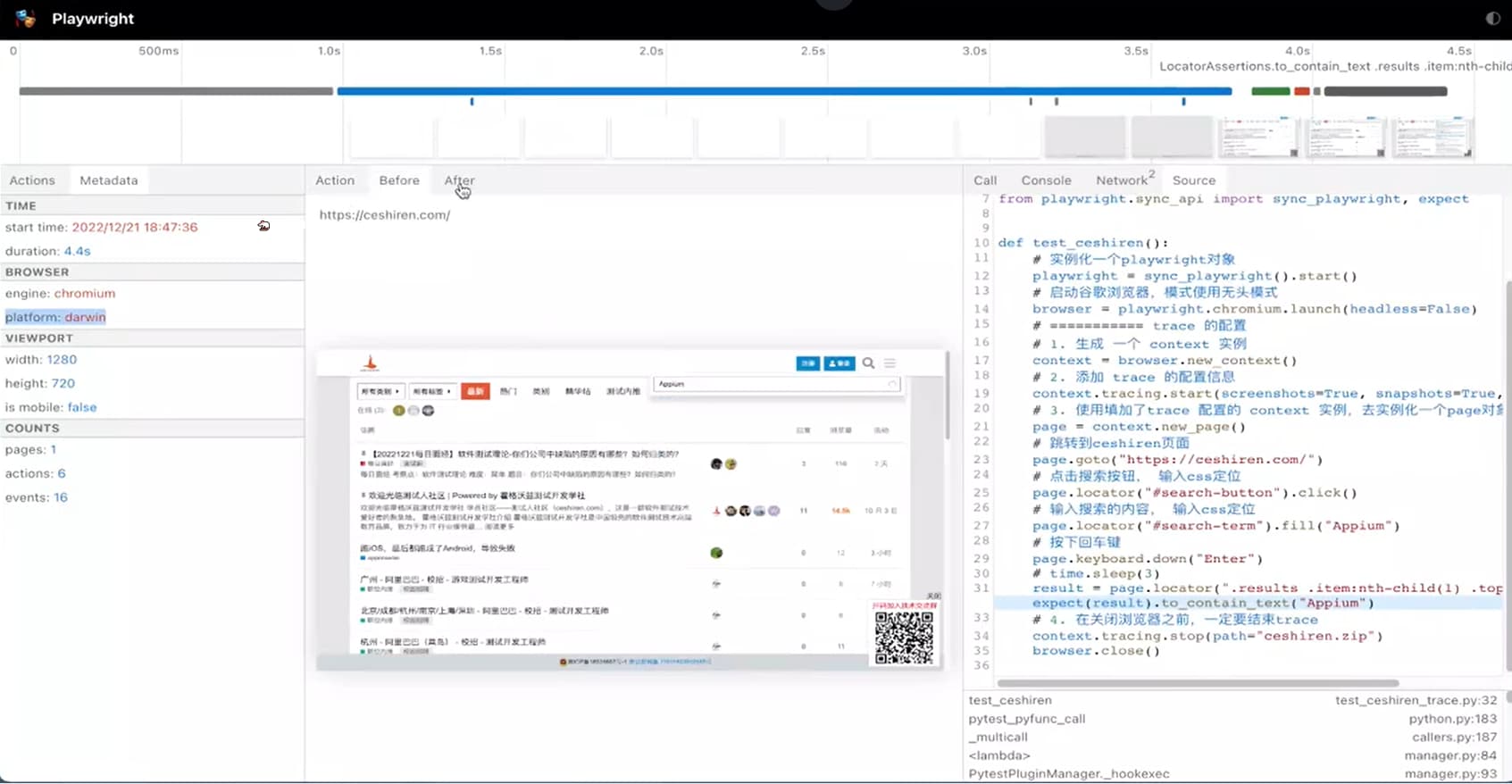
Trace Viewer 简介
Trace Viewer 使用
# trace 在代码中的配置
browser = chromium.launch()
# 实例化一个新的context
context = browser.new_context()
# 设置trace的参数信息
context.tracing.start(screenshots=True, snapshots=True, sources=True)
# 使用context生成的page实例进行对应的操作
page = context.new_page()
# 结束追踪
context.tracing.stop(path = "trace.zip")
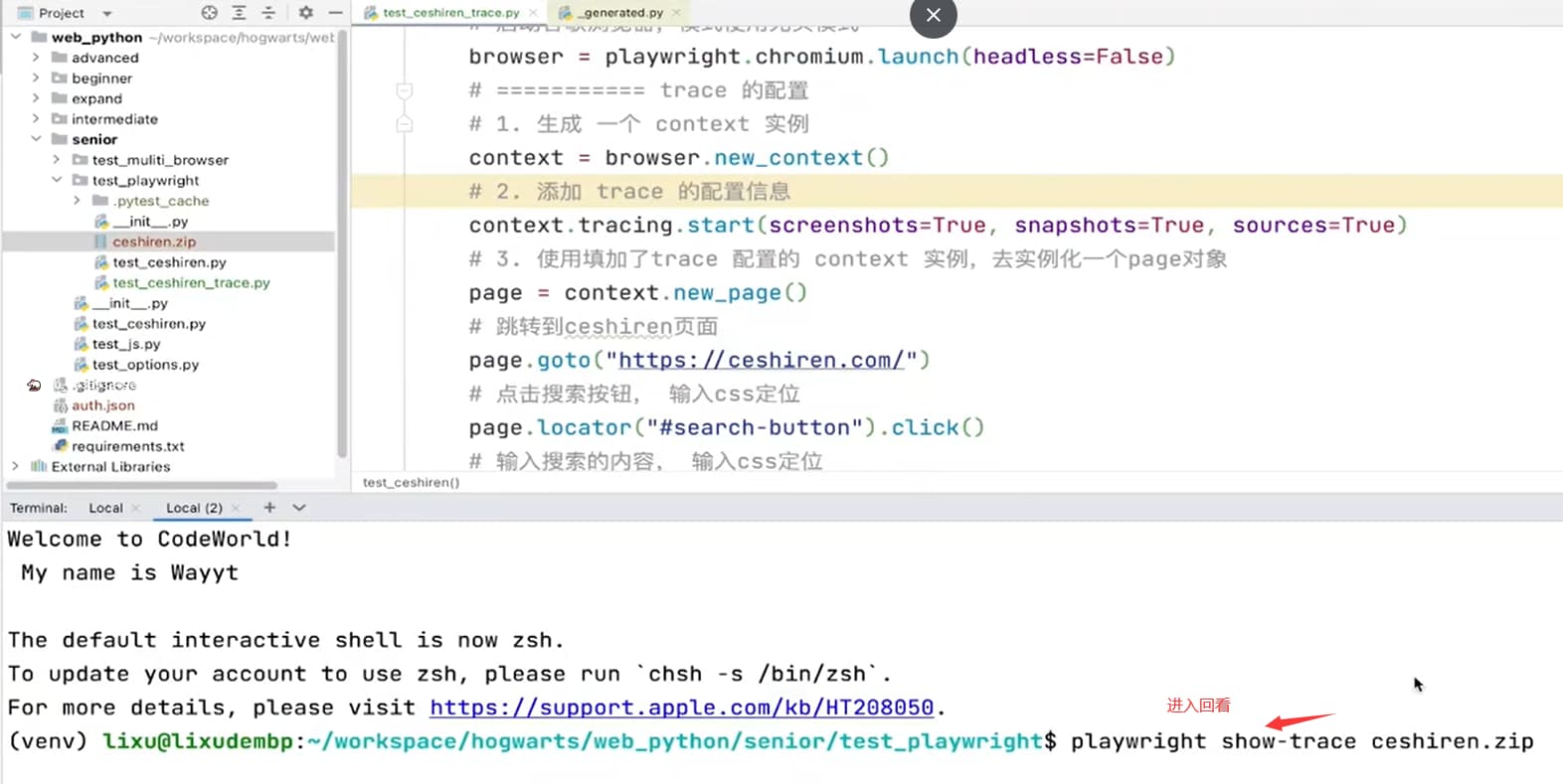
打开trace
playwright show-trace trace.zip