原创作者:山治
背景
2,3 年前更写过一些 UI 自动化的相关文章, 包括一些设计原则,怎么设计划分页面封装, 常用的设计模式等。 但是没有详细描述 UI 自动化中的分层理念, 赶上最近在新项目里做 UI 自动化测试并且今天有时间,所以补充一下 UI 自动化中比较重要的分层设计。 以前的帖子链接如下:
UI 自动化军规: 测试开发之路–UI 自动化设计军规 - 霍格沃兹测试开发学社 / 公众号 - 测试人社区 (ceshiren.com)
UI 自动化常用设计模式(一): 测试开发之路–UI 自动化常用设计模式 - 霍格沃兹测试开发学社 / 公众号 - 测试人社区 (ceshiren.com)
UI 自动化常用设计模式(二): 测试开发之路–UI 自动化常用设计模式 (二) - 霍格沃兹测试开发学社 / 公众号 - 测试人社区 (ceshiren.com)
以前的设计
在过去 UI 自动化测试领域有一个规范的设计模式是 page object 模式。 意思是测试用例不会直接定位页面元素, 而是把每一个页面封装成一个类。 在这个类中封装页面元素。 然后测试用例调用 page 类来操作页面元素完成测试用例。如下图:

但这个模式已经诞生了差不多 20 年了。 它是以当时的前端开发模式为基础进行规定的。 而 20 年间前端技术和研发模式已经发生了很大的变化,这个模式已经不再适用当前的 UI 自动化项目了。所以我在我的项目用将上面的模式做了一些改良
改良后的设计
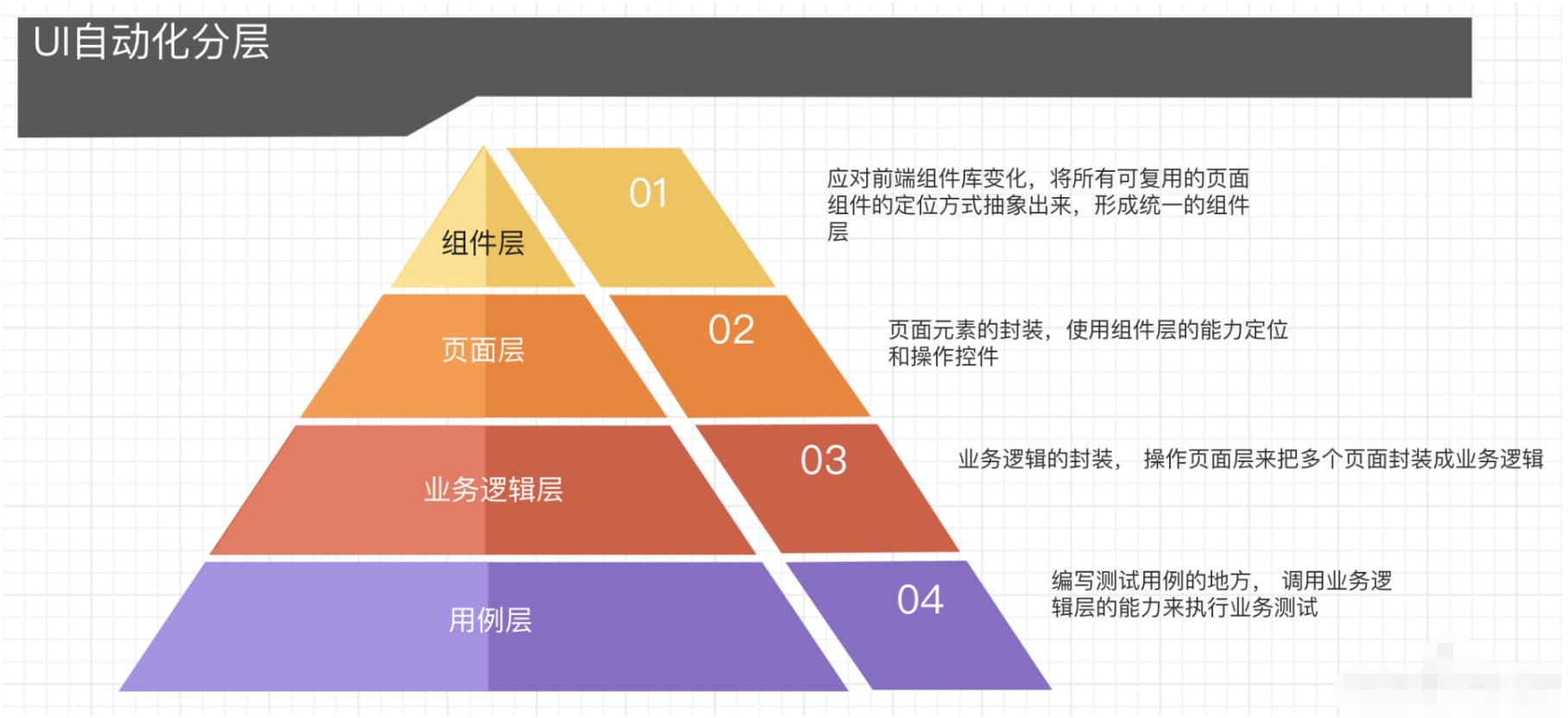
组件层
当下前端框架都有组件库的概念。 目的是封装通用的页面元素来让各个页面统一调用。 避免了重复开发的问题并且保持风格统一, 比如我之前在写前端项目的时候也会封装组件库, 然后在各个页面调用组件库中的组件。 我拿我之前写的前端项目举例:

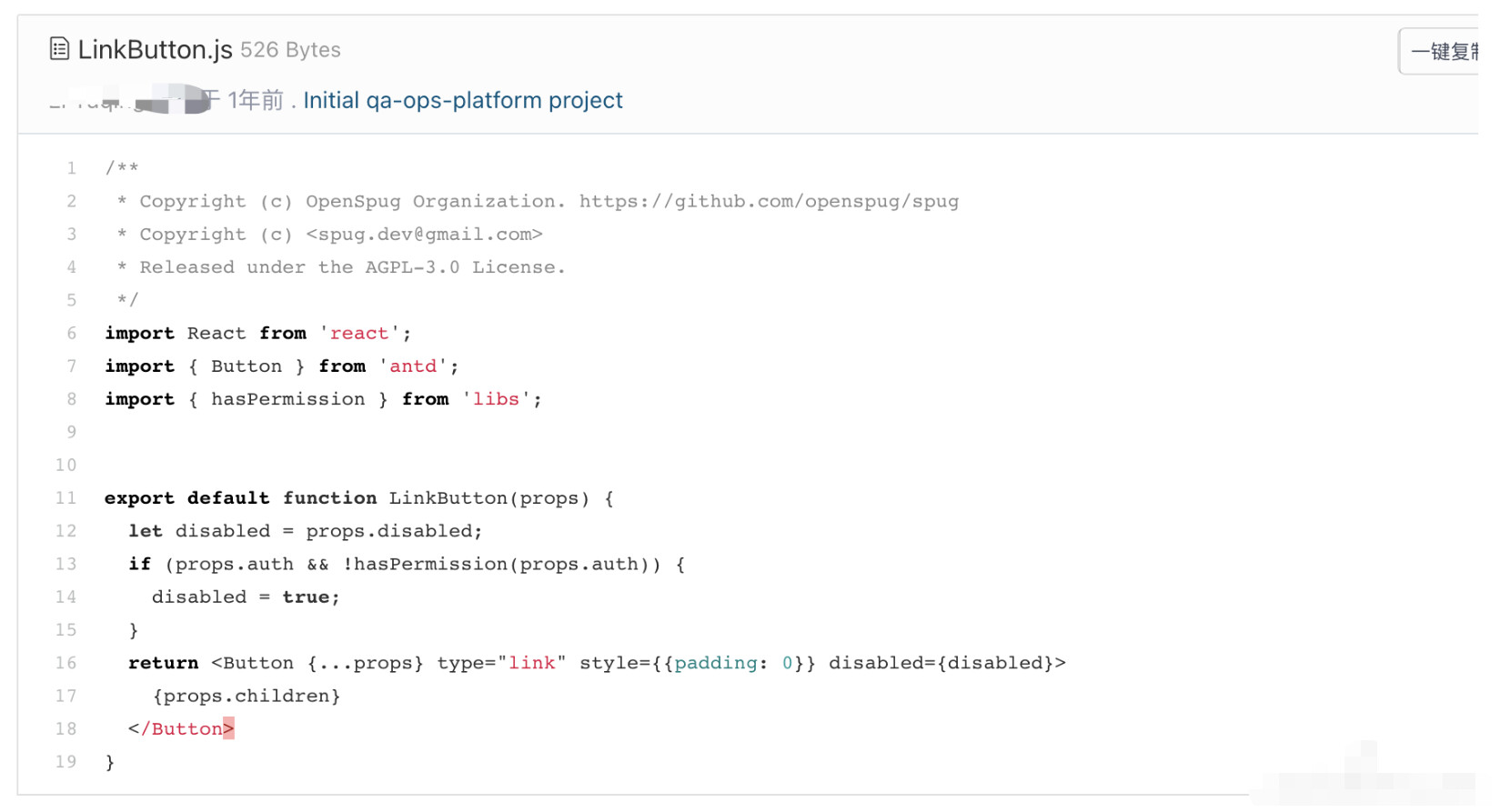

如上图中在一个前端项目中, 会专门有一个叫 component 的目录(第一张图),该目录里会封装常用的页面组件,比如 button,input,dropdown,link 等。 而每个组件都会编写独立的逻辑代码和 css 代码(第二张图)。 最后在页面中通过调用组件库的组件来完成页面逻辑(第三张图, 页面中调用了第二张图里展示的 LinkButton)。 所以我们在产品界面中才会发现很多控件长得都一样, 连属性都一样, 比如 class 里的值都是一样的。 这是因为他们其实是完完全全的同一个组件。 PS:在 CSS 中比较常用 class 来定位控件。 所以我们在控件中一般能看到各种 class 定义。 这就是现代前端项目的开发模式, 我们总能听到前端研发工程师们说的组件化,其实就是这个了。 这也是为什么我们会专门抽象出一层组件层的原因。 如果研发在迭代过程中修改了组件库, 那么会影响所有的页面。 一般这对 UI 自动化来说是一个很大的打击。 所以为了避免这种情况出现,同时为了简化页面定位成本。 所以 UI 自动化项目中也要对应的封装出一个组件层来专门做元素的定位和操作。 比如我之前曾经在产品中见过这样的情况, 之前我们的 button 都是下面这个样子的。
<button> 确定 </button>
但是突然研发修改了 button 组件库。 于是所有的 button 就变成了下面这个样子:
<button>
<span> 确定 </span>
</button>
在修改之前一切很美好, 我们只需要用 bytext 方法或者用一个 xpath: //button[text()=‘确定’] 就能很方便的找到这个 button 并点击. 但某一天研发的组件库变了, button 不在有文案了, 而是在 button 里加了个 span 的子元素放置文案。 于是在 UI 自动化项目中以前所有页面的所有 button 定位和操作都挂了, 都需要改一遍。所以我们一般在 UI 自动化中通过增加一个组件层来解决这个问题。 如下图:
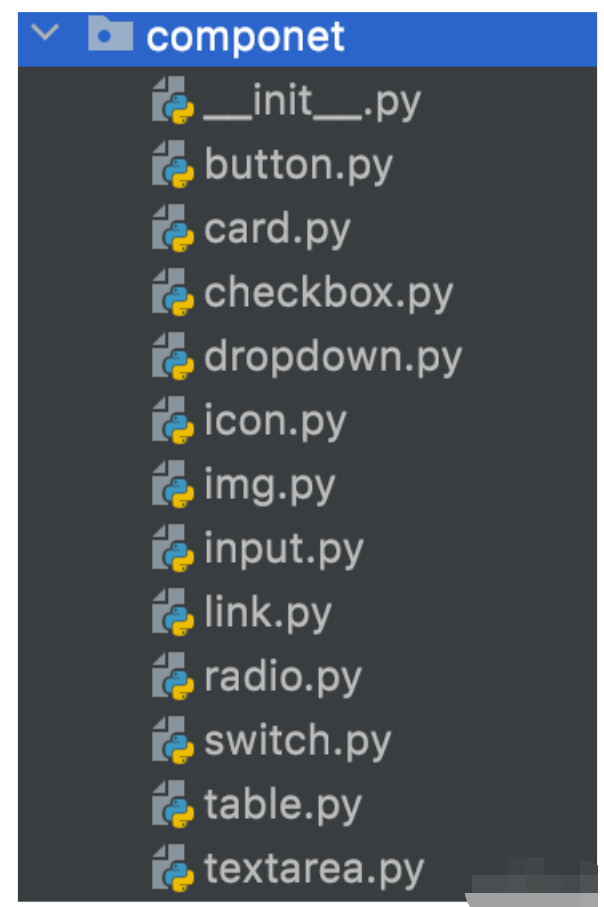
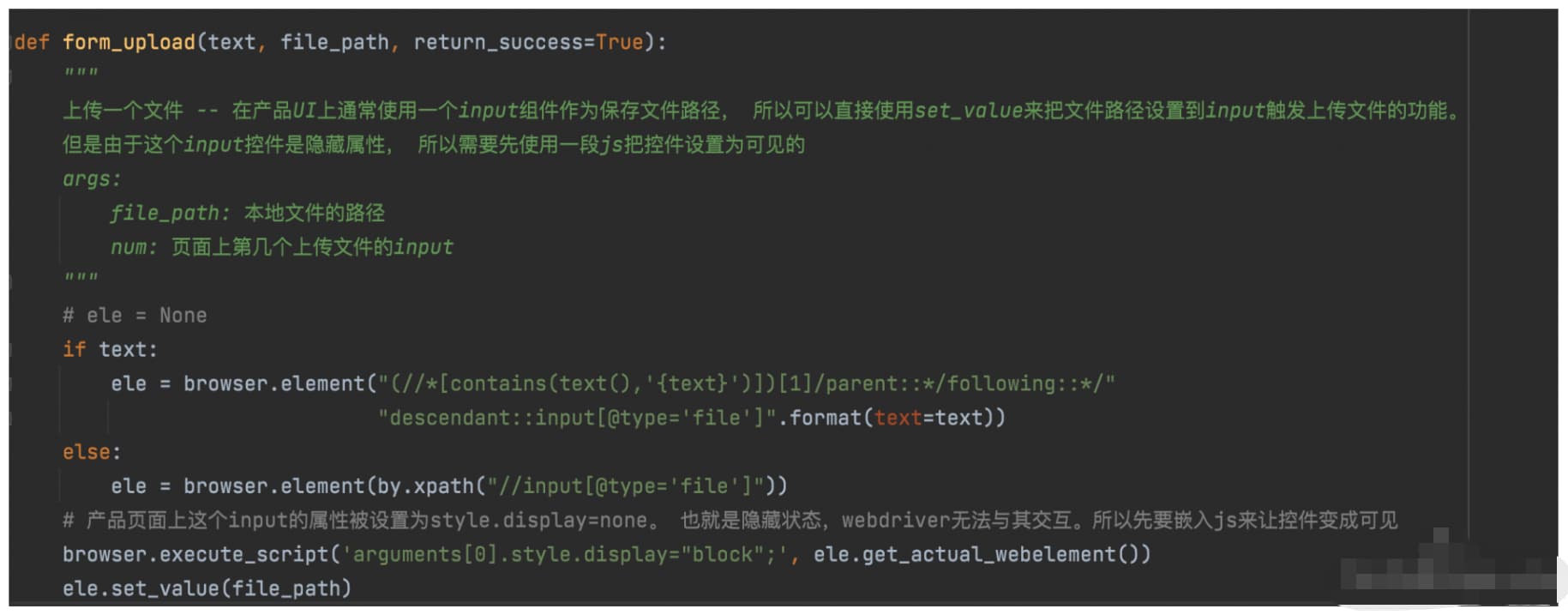
如上图, 在我们的测试代码中专门有一个名字叫 component 的目录, 里面根据控件的类型划分了很多文件, 每个文件里定义着这个类型的控件常用的定位和操作方式。 第二张图中我们看到的是 input 这个组件在产品中通用的逻辑。 比如拿 form_upload 这个控件来解释, 在产品中绝大部分上传文件的控件是由 input 组件来封装的。 点击上传操作其实触发的就是往一个属性 type=file 的 input 元素写入文件路径。 所以其实所有页面的上传操作都可以调用这个逻辑完成。 特别需要注意一点, 组件层不仅仅是封装元素的定位逻辑的, 也会封装一些常用操作。 还是拿上传控件来说, 用户在前端是要点击上传这个 button 后跳出一个文件选择框来完成上传操作的。 但是这个逻辑在 UI 自动化中是不可行的, 因为跳出这个文件选择框并不是浏览器的行为,而是当前操作系统的行为。 所以这个框实际上不受 webdriver 控制,并且不同的操作系统下这个框的样子也是不一样的。 所以在 UI 自动化中,我们只能通过给这个 input 元素直接写入上传的文件路径来触发文件操作。 但是这个 input 元素的 css 代码中设置了 style.display=none, 把这个 input 元素设置为了隐藏, 而 webdriver 是没办法与隐藏元素交互的。 所以我们需要先通过嵌入一段 js 代码, 把这个 input 修改成可见元素才能完成剩下的操作。 通过这个案例我想说明在组件层除了封装元素的定位方式外, 也会封装元素的操作方式。
原则上,我们所有的页面元素的交互都需要通过调用组件层的函数来完成, 一个是加快元素定位的速度 – 调用者不再需要自己定位了, 只需要调用组件层的方法,传递参数即可。 第二个是通过统一调用, 一旦后续前端组件库发生变化,导致元素定位方式也要改变。 我们只需要修改组件层非常少量的代码即可。 而不是研发动了一行代码, 测试项目这边需要成片的逻辑修改。
页面层
页面层与老式的 page object 模式中的页面层基本类似。 一个页面封装成一个 class, 在这个 class 里定义所有的元素和对应的操作。 只不过这类对元素的定位工作基本都是通过调用组件层的能力来完成的。 如下图:
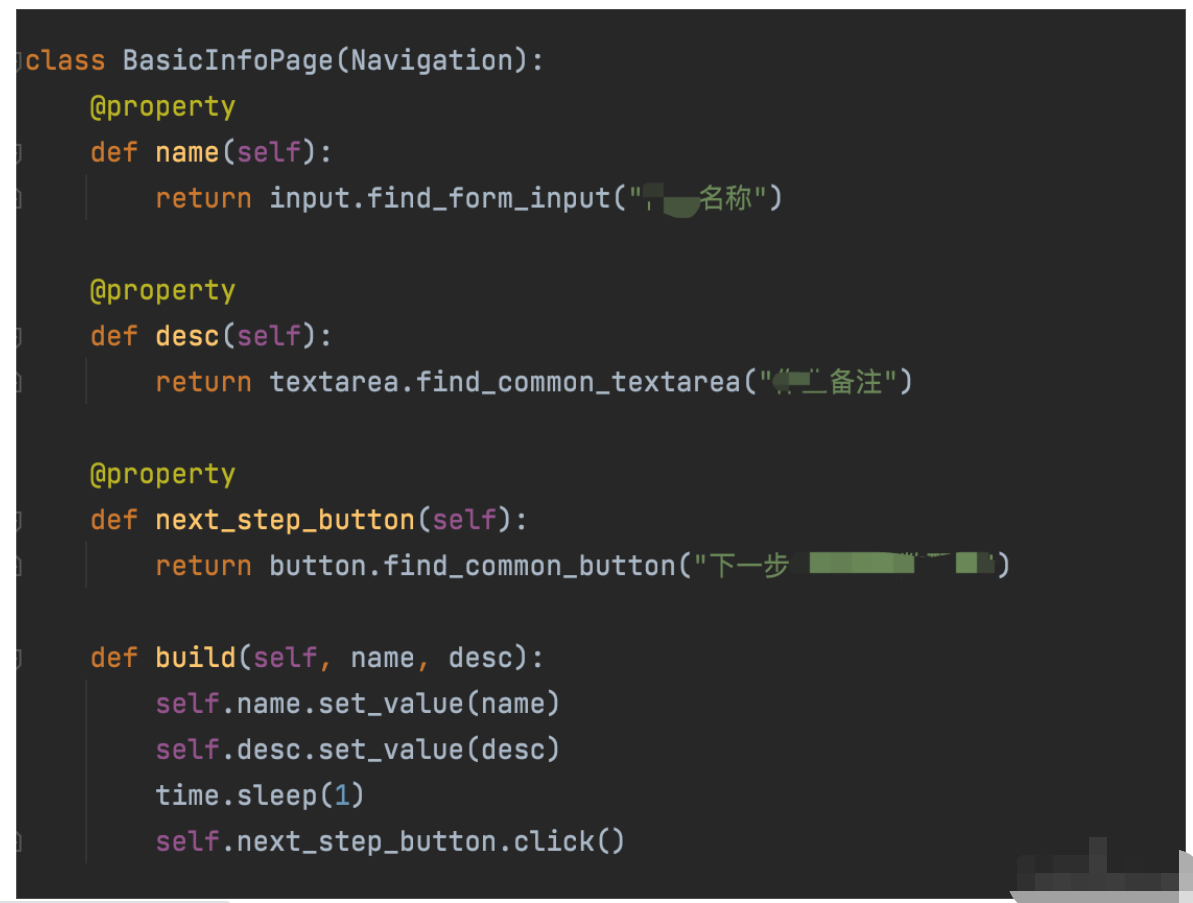
可以看到,一个页面上的所有元素都是定义在这个 class 里面的。 并且这些元素的定位都是通过组件层的方法来完成的。 我们在文件开头就会引入这些组件库来帮助页面层来完成元素的定位于操作。 同时建议页面层文件不仅仅是封装单个元素的定位, 也可以封装页面里常用的操作。 我们推荐这种封装方式, 我们应该尽量避免在 case 中直接调用页面元素操作。 原因有二
- 代码复用, 大量 case 其实都需要调用相同的逻辑,封装成可复用的代码可以减少 case 编写成本
- 当页面元素出现变化,比如增删元素的时候。 可只修改封装的逻辑, 而不必大量修改 case。
组件层封装基本控件,应对前端组件库的变化, 而页面层就是对产品界面进行封装, 应对的是页面逻辑发生的变动
业务逻辑层
在我们的代码里, 每个模块都有 service 文件, 这个文件就是封装的业务逻辑的文件。 我们在页面层上封装的逻辑都是单页面逻辑。 而在测试中我们往往要执行一个很复杂的业务流程。 为了执行这样一个业务流程我们跳转了很多个页面。 所以我们有必要单独封装这样一层来把业务逻辑进行封装。 这里需要提一下, 业务逻辑层相当于页面层的上层封装。 封装了完成一个业务逻辑的所有操作,比如我们假设创建一个工作流, 需要先填写基本配置, 然后跳转到高级配置页面继续填写, 填写玩后点击确定显示创建成功, 到了这里还没结束,还需要等待这个工作流程执行到某个状态,比如运行成功状态。 这里面需要跳转多个页面,甚至还需要给定一个超时时间并轮询工作流程的状态。 为什么要封装这么一层呢, 因为必然有非常多的 case 去完成这样一个流程。
需要注意的是, 我们每个模块都需要封装自己的业务逻辑层。 因为一个产品里必然有非常多的模块并且这些模块之间是有依赖关系的。 比如我在之前讲大数据的时候介绍过, 一个大数据平台的产品中做什么事都需要先把外部数据源中的数据同步到本系统里对吧, 所以数据中心的测试人员就的把自己模块的业务逻辑封装一下给其他模块的人用。 同样的,模型中心模块的人要测试得先有个模型对吧, 那用来建模的建模中心就得把自己的业务逻辑封装好了给其他人用。 在 UI 自动化中往往就是这样的,各个模块之间需要互相配合,互相调用。 因为就是有很多 case 是横跨多个模块,链路非常长非常复杂的。
用例层
用例层就没啥好说的, 就是写 case 而已。 只不过在我的这个设计里, 用例层很轻, 大部分逻辑都已经被上面的 3 层做完了。 用例层大多数时候再调用业务逻辑层, 少数情况调用页面层。 所以 case 层很轻,代码很少。 没什么可以特别强调的。
总结
就写到这吧, 最近又开始写 UI 自动化所以有些感受, 组织了一篇帖子跟大家探讨一下。
