转载自 微信公众号 哔哩哔哩技术
传统软件测试技术主要基于测试人员对业务的理解,但由于经验的局限性、被测系统的复杂性以及与真实业务数据的差距,肯定存在测试不充分的情况,所以,虽然整个测试流程很规范,但最终软件质量还是不尽如人意 。而随着分布式、微服务架构、大数据技术的出现,软件越来越复杂,迭代越来越快,测试的挑战性越来越大。测试人员急切的需要一套更加精确、高效的测试技术和方法 。精准化测试技术就在这种背景下应运而生并快速发展。
精准化测试技术是一种可追溯的软件测试技术,通过构建一套计算机测试辅助分析系统,对测试过程的活动进行监控,将采集到的监控数据进行分析,得到精准的量化数据,使用这些量化数据进行质量评价,利用这些分析数据可以促进测试过程的不断完善,形成度量及分析闭环,实现软件测试从经验型方法向技术型方法的转型 。
02 定义
在对精准测试下定义之前我们先看几个精准测试需要解决的问题:
- 如何刻画和度量有限测试集合的充分性
- 如何挑选有限测试集合并充分执行
- 如何让上述过程更加自动化、更加精准
那我们可以得到精准测试需要包含的几个特性:
- 全不全:通过代码覆盖率度量测试充分性
- 准不准:通过精准推荐代替人工进行变更影响范围评估指导用例回归
- 快不快:精准推荐自动化&用例执行失败快速定位等
然后我们可以将其定义为:精准测试是基于代码和用例关联关系的测试充分性度量和提升手段之一。
03 实现思路
首先贴一张流程图:
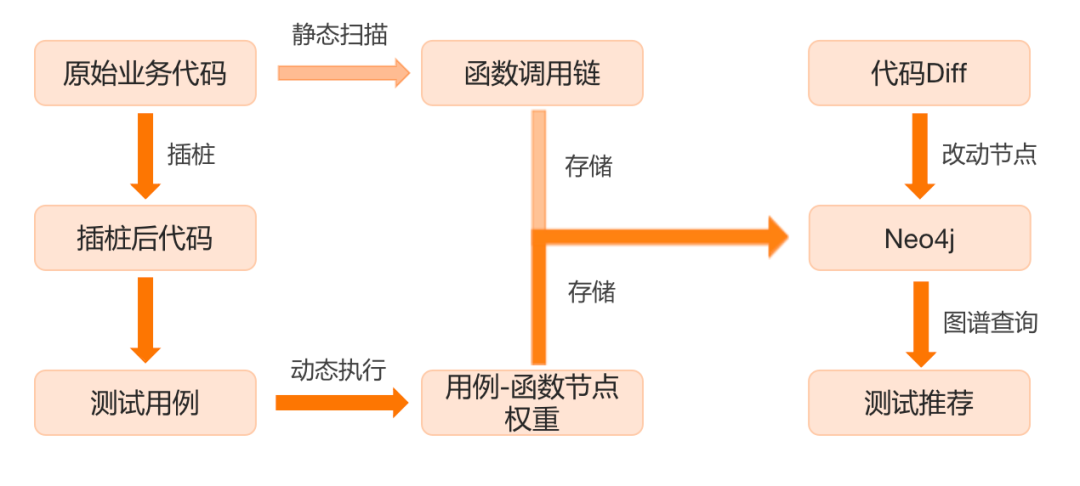
整体使用有两条链路:
- 静态扫描+推荐测试范围,流程如下:
- 原始代码静态扫描,获取基础函数调用链
- 原数据解析,扫描结果存储至Neo4j
- 代码diff获取版本差异,图谱查询影响接口范围
- 测试范围推荐
- 动态追踪+推荐测试用例,流程如下:
- 业务代码插桩
- 插桩后执行业务/自动化测试用例
- 采集“用例-函数调用链”权重
- 代码diff获取版本差异
- 测试用例推荐
04 技术架构
4.1 技术选型
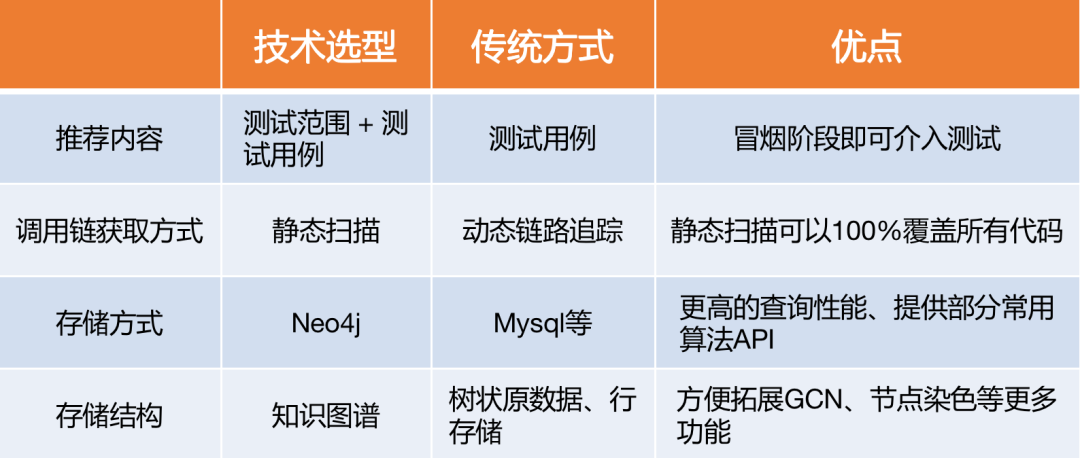
4.2 测试范围评估实践
4.2.1
原始代码静态扫描,获取基础函数调用链
首先会有两轮扫描:
-
自研算法获取函数的基础调用链,获取函数节点及调用关系
-
AST扫描,获取函数节点补充信息

AST是抽象语法树(Abstract Syntax Tree)的简称,AST以树状形式表现编程语言的语法结构,树上每个节点都表示源代码中的一种结构。
4.2.2
原数据解析,扫描结果存储至Neo4j
在获取到调用链的graph数据后,遍历转换成存入Neo4j所需的cypher语句
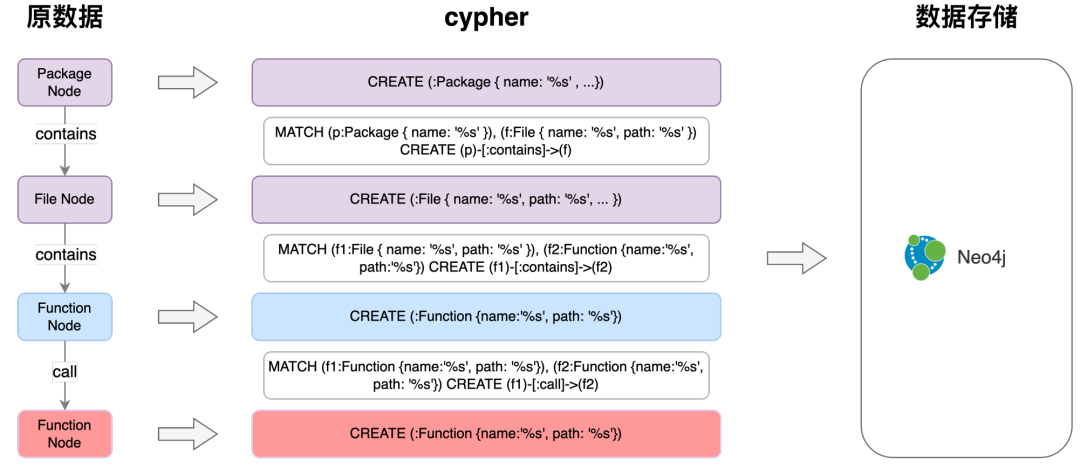
如上图所示,图谱最基本的组成单位,存在 (代码所属包)-[包含]->(文件)-[包含]->(函数)-[调用]->(函数)的结构
在获取项目调用链原数据后,再深度遍历每一条调用链路采集每个包、文件、函数的对应关系,以及路径、所处位置、出参入参、注释、代码行等信息,写入Neo4j。

4.2.3
**代码diff获取版本差异,**图谱查询影响接口范围
通过git开放api,我们可以在git diff内获取两次commit对比

通过文件路径与函数名,我们可以找到对应的函数节点
然后通过图谱向上追踪查询完整的调用链路,最终获取到影响的接口

4.2.4 测试范围推荐
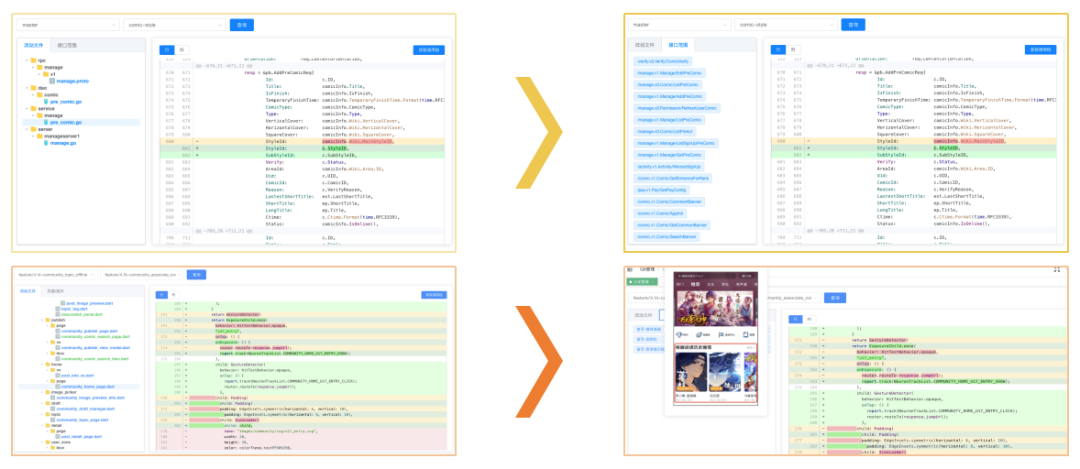
可视化页面展示版本代码对比,与影响的接口(服务端)、页面/组件(客户端)
4.3 测试用例推荐实践
下面主要讲解调用链获取及加权部分
4.3.1 业务代码插桩
修改编译逻辑,在开始编译前通过AST解析插入覆盖率和Trace的采集器
4.3.2 用例执行
通过代理服务执行测试用例,采集“用例-调用链”的映射关系
4.3.3 采集“用例-函数调用链”权重
对关联关系进行加权计算后,存入Neo4j。
下面举例几种不同的权重计算方式:
调用次数加权
假如有一条测试用例,执行时经过了Api_1和Api_2两个接口
然后Api_1执行时经过了函数FuncA、FuncC、FuncE
Api_2执行时经过了函数FuncB、FuncD、FuncE
我们可以理解为该条测试用例,对于函数A、B、C、D、E的调用次数加权分别为1、1、1、1、2
业务模块加权
这是半手工的方式,如果在用例管理系统中,有一条case属于“书架”模块,那我们可以将不同层级的代码,处于bookshelf目录下的函数,都与该case绑定一个“同模块(module_weight)”的关系(relationship)
文本相似度加权
通过对测试用例库内的所有用例,进行分词、建立词库,使用tf-idf的方式计算用例与用例间的文本相似度,来计算用例的相似性
此方案对测试人员编写用例时的要求较高,如果会有不同的测试人员去测试相同模块,因为书写习惯不一样,可能会导致case计算结果不准确,所以我们引入GCN计算case的相似性
GCN(图卷积神经网络)计算用例相似性
实际使用中,我们会采取不同的特征来训练GCN,用于计算不同场景的结果
在这里我们举一个简单的例子,用于计算case的相似性:
-
我们通过采集不同case对函数的调用层级,构成一个C × N的稀疏矩阵 (**C:**测试用例个数,**N:**函数节点数)
-
将调用层级数取反,然后归一化,得到训练模型用的矩阵
-
根据GCN的定义**X’=σ(L ̃sym XW)**来定义GCN层,然后堆叠两层GCN构建图卷积网络
-
训练完后,通过TSNE将输出层的score嵌入进行二维化处理,计算每个节点与节点的欧式距离,再存入Neo4j
4.3.4 代码diff获取版本差异
与步骤4.2.4一样,通过代码diff获取改动的函数节点,然后通过权重计算获取测试用例。
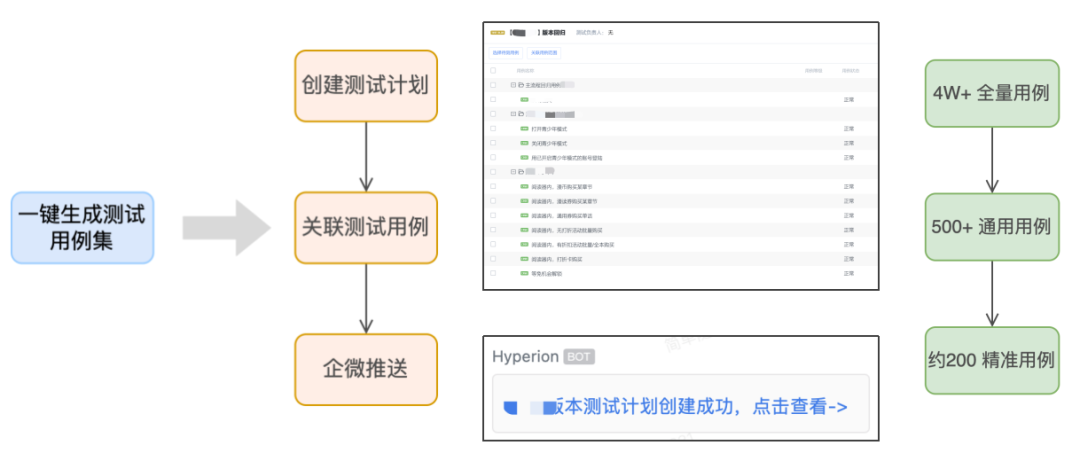
4.3.5 测试用例推荐
如果是业务用例则自动创建测试计划,并关联测试用例。
如果是自动化测试用例,则自动导入用例所处的文件、函数信息。
05 落地效果
目前平台在MR、冒烟、提测、回归、上线等不同阶段,采取了8种不同的质量保障措施:
- 迭代时间由3周缩短至2周
- 版本平均需执行自动化用例数减少80%
- 回归测试阶段平均需执行用例数减少60%
- 覆盖率需统计代码减少90%

06 未来展望
- 随着增量用例的增多,数据量提高,进一步提高GCN的计算结果准确度
- 打造调用链代码染色+页面可视化功能,助力测试环境问题定位
以上是今天的分享内容,如果你有什么想法或疑问,欢迎大家在留言区与我们互动,如果喜欢本期内容的话,请给我们点个赞吧!
