工作集大小 (WSS) 是应用程序需要多少内存才能保持工作。您的应用程序可能分配了 100 GB 的主内存并进行了页面映射,但它每秒只触及 50 MB 来完成它的工作。这就是工作集大小:经常使用的“热”内存。了解容量规划和可扩展性分析很有用。
您可能从未见过任何工具测量的 WSS(当我创建此页面时,我也没有)。操作系统通常会向您显示以下指标:
- 虚拟内存 :不是真实内存。它是虚拟内存系统的产物。对于像 Linux 这样的按需内存系统,malloc() 立即返回虚拟内存,仅在稍后使用时才提升为实际内存(通过页面错误提升)。
- 驻留内存 或驻留集大小 (RSS):主内存。当前映射的实际内存页。
- 比例集大小 (PSS):在用户之间分配共享内存的 RSS
当内核管理虚拟和主内存分配时,它们很容易被内核跟踪。但是,当您的应用程序处于用户模式下通过其 WSS 执行加载和存储指令时,内核(通常)不参与。因此,内核没有明显的方式可以提供 WSS 指标。
在此页面上,我将总结 WSS 目标和 WSS 估计的不同方法,适用于任何操作系统。这包括我的 Linux wss工具,它通过使用引用和空闲页面标志进行基于页面的 WSS 估计,以及我的WSS 配置文件图表。
目录:
目标
您打算使用 WSS 的目的将指导您如何衡量它。考虑以下三种情况:
A) 您正在为应用程序调整主内存大小,以防止它分页(交换)。WSS 将在很长一段时间内以字节为单位进行测量,例如一分钟。
B)您正在优化 CPU 缓存。WSS 将在短时间间隔内访问的唯一缓存行中测量,例如一秒或更短时间。缓存线大小取决于体系结构,通常为 64 字节。
C)您正在优化 TLB 缓存(转换后备缓冲区:用于虚拟到物理转换的内存管理单元缓存)。WSS 将在短时间间隔内访问的唯一页面中测量,例如一秒或更短。页面大小取决于体系结构和操作系统配置,通常使用 4 KB。
您可以使用cpuid计算Linux 上的缓存线大小,使用pmap -XX计算页面大小。
1. 估计
您可以尝试估计它:您的应用程序将接触多少内存来服务请求,或者在很短的时间间隔内?如果您可以访问应用程序的开发人员,他们可能已经有了合理的想法。根据您的目标,您需要询问将引用多少个唯一字节、缓存行或页面。
2. 观察:分页/交换指标
分页指标通常在不同的操作系统中可用。Linux、BSD 和其他 Unix 将它们打印在vmstat中,OS X 在vm_stat中打印。通常还有扫描指标,表明系统内存不足,并且花费更多时间来填充空闲列表。
这些指标的基本思想是:
- 持续分页/交换 == WSS 大于主内存。
- 没有分页/交换,但持续扫描 == WSS 接近主内存大小。
- 没有分页/交换或扫描 == WSS 小于主内存大小。
与其他内存计数器(如常驻内存又名 RSS:常驻集大小、虚拟内存、Linux“活动”/“非活动”内存等)相比,持续分页的有趣之处在于,持续分页告诉我们,应用程序实际上是在使用该内存来完成它的工作。使用像驻留集大小 (RSS) 这样的计数器,您不知道应用程序每秒实际使用了多少。
在 Linux 上,这需要将交换设备配置为分页目标,而在许多系统上并非如此。如果没有交换设备,Linux 内存不足 (OOM) 杀手可以杀死牺牲进程以释放空间,这并不能告诉我们很多关于 WSS 的信息。
2.1。分页/交换
查找分页/交换计数器通常很容易。它们在 Linux 上(输出列不与标题对齐):
2. 观察:分页/交换指标
分页指标通常在不同的操作系统中可用。Linux、BSD 和其他 Unix 将它们打印在vmstat中,OS X 在vm_stat中打印。通常还有扫描指标,表明系统内存不足,并且花费更多时间来填充空闲列表。
这些指标的基本思想是:
- 持续分页/交换 == WSS 大于主内存。
- 没有分页/交换,但持续扫描 == WSS 接近主内存大小。
- 没有分页/交换或扫描 == WSS 小于主内存大小。
与其他内存计数器(如常驻内存又名 RSS:常驻集大小、虚拟内存、Linux“活动”/“非活动”内存等)相比,持续分页的有趣之处在于,持续分页告诉我们,应用程序实际上是在使用该内存来完成它的工作。使用像驻留集大小 (RSS) 这样的计数器,您不知道应用程序每秒实际使用了多少。
在 Linux 上,这需要将交换设备配置为分页目标,而在许多系统上并非如此。如果没有交换设备,Linux 内存不足 (OOM) 杀手可以杀死牺牲进程以释放空间,这并不能告诉我们很多关于 WSS 的信息。
2.1。分页/交换
查找分页/交换计数器通常很容易。它们在 Linux 上(输出列不与标题对齐):
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 1 0 64166788 36348 5396380 0 0 0 1 1 1 9 0 91 0 0
0 1 0 64166656 36348 5396388 0 0 0 18432 318 510 0 0 97 3 0
0 1 0 64167276 36348 5396356 0 0 0 21504 359 551 0 0 97 3 0
[...]
Linux calls paging “swapping” (in other Unixes, swapping refers to moving entire threads to the swap device, and paging refers to just the pages). The above example shows no swapping is active.
2.2. Scanning
Linux 将分页称为“交换”(在其他 Unix 中,交换是指将整个线程移动到交换设备,而分页仅指页面)。上面的示例显示没有交换处于活动状态。
2.2. 扫描
较旧的 Unix 使用页面扫描器在所有内存中搜索最近未使用的页面以进行分页,并在 vmstat 中报告扫描率。仅当系统内存不足时,扫描率才非零,并根据需求增加。该扫描速率可以用作系统即将耗尽主内存(如果它还没有分页)的早期警告,并将速率用作幅度。请注意,需要持续扫描(例如,30 秒)才能给出有关 WSS 的指示。应用程序可以分配和填充已扫描和分页但随后不再使用的内存,从而导致扫描和分页突发。那是冷酷的记忆:它不是 WSS。WSS 处于活动状态,如果被调出会很快又被调回,造成分页流失:持续扫描和分页。
Linux 维护“活动”和“非活动”内存列表,因此可以通过遍历非活动列表快速找到符合条件的页面。在不同的时间点,页面将从活动列表移动到非活动列表,在那里它们有机会被“回收”并移回活动状态,然后在需要时换出。/proc/meminfo 中提供了活动/非活动内存大小。要检查系统是否接近交换点,可以使用 vmscan tracepouints。例如:
# perf stat -e 'vmscan:*' -a
^C
Performance counter stats for 'system wide':
1 vmscan:mm_vmscan_kswapd_sleep
16 vmscan:mm_vmscan_kswapd_wake
8 vmscan:mm_vmscan_wakeup_kswapd
4 vmscan:mm_vmscan_direct_reclaim_begin
0 vmscan:mm_vmscan_memcg_reclaim_begin
0 vmscan:mm_vmscan_memcg_softlimit_reclaim_begin
4 vmscan:mm_vmscan_direct_reclaim_end
0 vmscan:mm_vmscan_memcg_reclaim_end
0 vmscan:mm_vmscan_memcg_softlimit_reclaim_end
1,407 vmscan:mm_shrink_slab_start
1,407 vmscan:mm_shrink_slab_end
10,280 vmscan:mm_vmscan_lru_isolate
0 vmscan:mm_vmscan_writepage
8,567 vmscan:mm_vmscan_lru_shrink_inactive
1,713 vmscan:mm_vmscan_lru_shrink_active
2,743 vmscan:mm_vmscan_inactive_list_is_low
You could choose just the vmscan:mm_vmscan_kswapd_wake tracepoint as a low-overhead (because it is low frequency) indicator. Measuring it per-second:
# perf stat -e vmscan:mm_vmscan_kswapd_wake -I 1000 -a
# time counts unit events
1.003586606 0 vmscan:mm_vmscan_kswapd_wake
2.013601131 0 vmscan:mm_vmscan_kswapd_wake
3.023623081 0 vmscan:mm_vmscan_kswapd_wake
4.033634433 30 vmscan:mm_vmscan_kswapd_wake
5.043653518 24 vmscan:mm_vmscan_kswapd_wake
6.053670317 0 vmscan:mm_vmscan_kswapd_wake
7.063690060 0 vmscan:mm_vmscan_kswapd_wake
You may also see kswapd show up in process monitors, consuming %CPU.
3. 实验:主内存缩小
值得一提但不推荐:我在多年前看到这种方法在 Unix 系统上使用,其中更常配置和使用分页,并且可以通过实验减少正在运行的应用程序的可用内存,同时观察它的分页量。有时应用程序通常“快乐”(低分页),然后又不是(突然高分页)。该点是 WSS 的度量。
4. 观察:PMC
性能监控计数器 (PMC) 可以为您的 WSS 提供一些线索,并且可以在 Linux 上使用perf进行测量。以下是一些工作负载,使用我的pmc-cloud-tools中的 pmcarch 工具测量:
workload_A# ./pmcarch
K_CYCLES K_INSTR IPC BR_RETIRED BR_MISPRED BMR% LLCREF LLCMISS LLC%
3062544 4218774 1.38 498585136 540218 0.11 455116420 680676 99.85
3053808 4217232 1.38 499144330 524938 0.11 454770567 667970 99.85
3132681 4259505 1.36 515882929 680336 0.13 457656727 980983 99.79
[...]
workload_B# ./pmcarch
K_CYCLES K_INSTR IPC BR_RETIRED BR_MISPRED BMR% LLCREF LLCMISS LLC%
3079239 2314148 0.75 273159770 512862 0.19 243202555 148518182 38.93
3079912 2308655 0.75 273788704 494820 0.18 245159935 149093401 39.19
3090707 2316591 0.75 274770578 523050 0.19 243819132 148390054 39.14
[...]
工作负载 A 的最后一级缓存(LLC,又名 L3)命中率超过 99.8%。它的 WSS 会小于 LLC 的大小吗?大概。LLC 大小为 24 MB(CPU 为:Intel(R) Xeon(R) Platinum 8124M CPU @ 3.00GHz)。这是具有统一访问分布的合成工作负载,我知道 WSS 为 10 MB。
工作负载 B 的 LLC 命中率为 39%。根本不合适。它也是合成和统一的,WSS 为 100 MB,比 LLC 大。所以这是有道理的。
这个怎么样?
workload_B# ./pmcarch
K_CYCLES K_INSTR IPC BR_RETIRED BR_MISPRED BMR% LLCREF LLCMISS LLC%
3076373 6509695 2.12 931282340 620013 0.07 8408422 3273774 61.07
3086379 6458025 2.09 926621170 616174 0.07 11152959 4388135 60.65
3094250 6487365 2.10 932153872 629623 0.07 8865611 3402170 61.63
如果 LLC 命中率为 61%,您可能会猜测它介于工作负载 A(10 MB)和 B(100 MB)之间。但是不,这也是 100 MB。我通过使访问模式不统一来提高其 LLC 命中率。我们能做些什么呢?有很多 PMC:用于缓存、MMU 和 TLB 以及内存事件,所以我认为我们可以为 CPU 建模,插入所有这些数字,让它不仅估计 WSS,而且估计访问模式. 我还没有看到有人尝试过这个(肯定有人尝试过),所以我没有任何关于它的参考。它已经在我的待办事项清单上尝试了一段时间。它还涉及真正了解每个 PMC:它们通常有测量警告。
这是我刚刚添加到 pmc-cloud-tools 的新工具 cpucache 的屏幕截图,其中显示了其中一些额外的 PMC:
# ./cpucache
All counter columns are x 1000
CYCLES INSTR IPC L1DREF L1DMISS L1D% L2REF L2MISS L2% LLCREF LLCMISS LLC%
13652088 5959020 0.44 1552983 12993 99.16 19437 8512 56.20 10224 4306 57.88
7074768 5836783 0.83 1521268 12965 99.15 21182 10380 51.00 13081 4213 67.79
7065207 5826542 0.82 1520193 12905 99.15 19397 8612 55.60 10319 4118 60.09
[...]
请注意,CPU 缓存通常在缓存线(例如,64 字节)上运行,因此随机 1 字节读取的工作负载变为 64 字节读取,从而使 WSS 膨胀。虽然,如果我正在分析 CPU 缓存可扩展性,无论如何我都想了解 WSS 的缓存线,因为这就是将被缓存的内容。
至少,PMC 可以告诉您:
如果 L1、L2 或 LLC 具有 ~100% 的命中率和 高引用计数,则基于单线程高速缓存行的 WSS 比该高速缓存小,并且可能比之前的任何高速缓存都大。
如果 L2 为 8 MB,LLC 为 24 MB,并且 LLC 的命中率约为 100%且 引用计数很高,则您可能会得出结论,WSS 介于 8 到 24 MB 之间。如果它小于 8 MB,那么它将适合 L2,并且 LLC 将不再具有高引用计数。我说“可能是”是因为较小的工作负载可能不会因为其他原因缓存在 L2 中:例如,设置关联性。
我还必须将其限定为单线程。多线程有什么问题?考虑一个运行多线程应用程序的多核多插槽服务器,其中每个线程有效地拥有自己正在运行的工作集。应用程序的组合工作集大小可以由多个 CPU 缓存进行缓存:多个 L1、L2 和 LLC。它的 LLC 命中率可能约为 100%,但 WSS 比单个 LLC 大,因为它存在于多个 LLC 中。
5. 实验:CPU Cache Flushing
只是一个想法。我找不到任何人这样做的例子,但对于 CPU 缓存,我想缓存刷新与 PMC 相结合可用于 WSS 估计。刷新缓存,然后测量 LLC 填充并再次开始驱逐所需的速度。速度越慢,WSS 越小(可能)。通常有 CPU 指令来帮助缓存刷新,前提是它们已启用:
cpuid -1 | grep -i flush
CLFLUSH line size = 0x8 (8)
CLFLUSH instruction = true
CLFLUSHOPT instruction = true
这种方法还可以应用于其他缓存。可以刷新 MMU TLB(至少内核知道如何刷新)。Linux 文件系统缓存可以使用 /proc/sys/vm/drop_caches 刷新,然后通过操作系统指标(例如free)随时间跟踪增长。
6. 实验:PTE Accessed Bit
这些方法使用页表条目(PTE)“已访问”位,通常由 CPU MMU 在访问内存页面时更新,并且可以由内核读取和清除。这可用于提供基于页面的 WSS 估计,方法是清除所有进程页面上的访问位,等待一段时间,然后检查该位返回到多少页。当访问的位被更新时,它的优点是没有额外的开销,因为 MMU 无论如何都会这样做。
6.1. Linux 参考页标志
这使用了 Linux 2.6.22 中添加的内核功能:从用户空间设置和读取引用页面标志的能力,添加用于分析内存使用情况。引用的页面标志实际上是 PTE 访问位(Linux 中的_PAGE_BIT_ACCESSED)。我开发了wss.pl作为此功能的前端。下面在 MySQL 数据库服务器 (mysqld) 上使用它,PID 423,并测量其工作集大小为 0.1 秒(100 毫秒):
# ./wss.pl 423 0.1
Watching PID 423 page references during 0.1 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
0.107 403.66 400.59 28.02
在 100 毫秒内,mysqld 在其 404 MB 的总主内存中访问了 28 MB 的页面。为什么我使用 100 毫秒的间隔?较短的持续时间有助于了解 WSS 与 CPU 缓存(L1/L2/L3、TLB L1/L2 等)的匹配程度。在这种情况下,28 MB 比该 CPU 的 LLC 稍大,因此缓存可能不会那么好(无论如何,在单个 LLC 中)。
这里打印的列是:
- Est(s) :估计的 WSS 测量持续时间:这说明了设置和读取页面地图数据的延迟。
- RSS(MB) :驻留集大小(Mbytes)。主存大小。
- PSS(MB) :比例集大小(Mbytes)。占共享页面。
- Ref(MB) :在指定的持续时间内被引用(Mbytes)。这是工作集大小指标。
我将在 6.7 节中详细介绍估计的持续时间。
6.1.1. 这个怎么运作
它通过重置内存页面上的引用标志来工作,然后稍后检查该标志返回到多少页。我想起了旧的 Unix 页面扫描器,它会使用类似的方法来查找最近未使用的页面,这些页面有资格分页到交换设备(也称为交换)。我的工具使用 /proc/PID/clear_refs 和 /proc/PID/smaps 中的引用值,它们是由 David Rientjes 在 2007 年添加的。他还在他的补丁中描述了内存占用估计。我只看到了对此功能的另一种描述:我真正使用了多少内存?,作者:Jonathan Corbet(lwn.net编辑)。我将此归类为一种实验方法,因为它会修改系统的状态:更改引用的页面标志。
我之前的 PMC 分析将 WSS 向上舍入到缓存线大小(例如,64 字节)。这种方法将它向上舍入到页面大小(例如,4 KB),因此可能会向您展示最坏情况的 WSS。对于 2 MB 页面大小的大页面,它可能会使 WSS 膨胀得超出现实。但是,有时基于页面大小的 WSS 正是您想要的:了解 TLB 命中率,它存储页面映射。
6.1.2. 警告
该工具使用 /proc/PID/clear_refs 和 /proc/PID/smaps,当内核遍历页面结构时,这可能会导致稍高的应用程序延迟(例如,10%)。对于大型进程(> 100 GB),这种较高延迟的持续时间可能会持续超过 1 秒,在此期间此工具会消耗系统 CPU 时间。考虑这些开销。这也会重置引用的标志,这可能会使内核混淆要回收哪些页面,尤其是在交换处于活动状态时。这也激活了一些以前可能未在您的环境中使用过的旧内核代码,并修改了页面标志:我猜存在未被发现的内核恐慌的风险(Linux mm 社区可能会说这有多真实风险是)。在实验室环境中测试您的内核版本,并考虑这个实验性:使用风险自负。
请参阅第 7 节,了解在 Linux 4.3+ 上使用空闲页面标志的更安全的方法,它还跟踪未映射的文件 I/O 内存。
6.1.3. 累计增长
这是相同的过程,但测量 WSS 的时间为 1、10 和 60 秒(这不会产生额外的开销,因为无论如何该工具都会在这段时间内休眠):
# ./wss.pl `pgrep -n mysqld` 1
Watching PID 423 page references during 1 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
1.012 403.66 400.75 69.44
# ./wss.pl `pgrep -n mysqld` 10
Watching PID 423 page references during 10 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
10.019 403.66 400.75 80.79
# ./wss.pl `pgrep -n mysqld` 60
Watching PID 423 page references during 60 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
60.068 403.66 400.60 84.50
一秒后,该进程引用了 69 MB,十秒后引用了 81 MB,这表明在第一秒内已经引用了 WSS 的大部分内容。
该工具具有累积模式 (-C),它将产生滚动输出,显示工作集如何增长。这仅通过在开始时重置引用标志一次,然后为每个间隔打印当前引用的大小来工作。显示滚动的一秒输出:
# ./wss `pgrep -n mysqld` 1
Watching PID 423 page references grow, output every 1 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
1.014 403.66 400.59 86.00
2.034 403.66 400.59 90.75
3.054 403.66 400.59 94.29
4.074 403.66 400.59 97.53
5.094 403.66 400.59 100.33
6.114 403.66 400.59 102.44
7.134 403.66 400.59 104.58
8.154 403.66 400.59 106.31
9.174 403.66 400.59 107.76
10.194 403.66 400.59 109.14
[...]
6.1.4。与 PMC 相比
作为测试,我在一些规模越来越大的 MySQL sysbench OLTP 工作负载上运行了这个。这是–oltp-table-size=10000:
# ./wss.pl -C `pgrep -nx mysqld` 1
Watching PID 423 page references grow, output every 1 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
1.014 403.66 400.77 12.46
2.033 403.66 400.77 12.64
3.043 403.66 400.77 12.70
4.053 403.66 400.77 12.79
5.063 403.66 400.77 12.88
6.073 403.66 400.77 12.98
[...]
# ./pmcarch
K_CYCLES K_INSTR IPC BR_RETIRED BR_MISPRED BMR% LLCREF LLCMISS LLC%
3924948 4900967 1.25 983842564 8299056 0.84 49012994 423312 99.14
3741509 4946034 1.32 984712358 8397732 0.85 47532624 476105 99.00
3737663 4903352 1.31 987003949 8219215 0.83 48084819 469919 99.02
3772954 4898714 1.30 980373867 8259970 0.84 47347470 445533 99.06
3762491 4915739 1.31 983279742 8320859 0.85 48034764 398616 99.17
3764673 4912087 1.30 983237267 8308238 0.84 47989639 479042 99.00
[...]
wss 工具显示了一个 12 MB 的工作集,而 pmcarch 显示了 99% 的 LLC 命中率。这个 CPU 上的 LLC 是 24 MB,所以这是有道理的。
现在 --oltp-table-size=10000000:
# ./wss.pl -C `pgrep -nx mysqld` 1
Watching PID 423 page references grow, output every 1 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
1.010 403.66 400.59 86.88
2.020 403.66 400.59 90.40
3.040 403.66 400.59 93.71
4.050 403.66 400.59 96.19
5.060 403.66 400.59 99.02
6.080 403.66 400.59 100.80
[...]
# ./pmcarch
K_CYCLES K_INSTR IPC BR_RETIRED BR_MISPRED BMR% LLCREF LLCMISS LLC%
3857663 4361549 1.13 875905306 8270478 0.94 57942970 4478859 92.27
3674356 4403851 1.20 869671764 8307450 0.96 57444045 4518955 92.13
3858828 4483705 1.16 893992312 8480271 0.95 57808518 4843476 91.62
3701744 4321834 1.17 861744002 8144426 0.95 56775802 4456817 92.15
4067889 4932042 1.21 994934844 12570830 1.26 63358558 5001302 92.11
3703030 4378543 1.18 874329407 8307769 0.95 58147001 4529388 92.21
[...]
现在 WSS 超过 80 MB,这应该会破坏 LLC,但是,它的命中率仅下降到 92%。这可能是因为访问模式不统一,并且该工作集的较热区域比较冷区域受到 LLC 的打击更多。
6.1.5。工作集大小分析
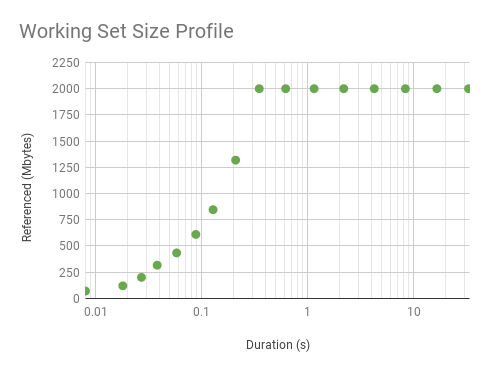
我在 wss 工具中添加了一个配置文件模式,以阐明访问模式。它通过 2 的幂来增加样本持续时间。这是相同的 MySQL 工作负载:
# ./wss.pl -P 16 `pgrep -n mysqld` 0.001
Watching PID 423 page references grow, profile beginning with 0.001 seconds, 16 steps...
Est(s) RSS(MB) PSS(MB) Ref(MB)
0.008 403.66 400.76 8.79
0.018 403.66 400.76 13.98
0.027 403.66 400.76 17.69
0.038 403.66 400.76 21.70
0.058 403.66 400.76 27.83
0.088 403.66 400.76 35.51
0.128 403.66 400.76 43.43
0.209 403.66 400.76 55.08
0.349 403.66 400.76 69.95
0.620 403.66 400.76 84.18
1.150 403.66 400.76 86.18
2.190 403.66 400.76 89.43
4.250 403.66 400.76 94.41
8.360 403.66 400.76 101.38
16.570 403.66 400.76 107.49
32.980 403.66 400.76 113.05
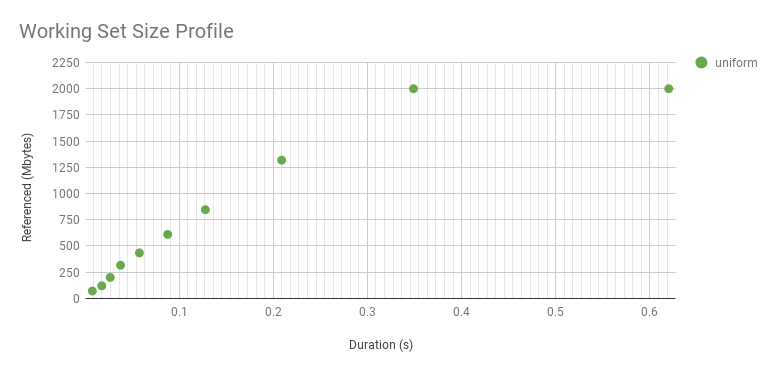
这是一个综合工作负载,它达到 100 MB,具有统一的访问分布:
# ./wss.pl -P 16 `pgrep -n bench` 0.001
Watching PID 34274 page references grow, profile beginning with 0.001 seconds, 16 steps...
Est(s) RSS(MB) PSS(MB) Ref(MB)
0.008 201.11 200.11 46.29
0.017 201.11 200.11 100.03
0.027 201.11 200.11 100.03
0.037 201.11 200.11 100.03
0.048 201.11 200.11 100.03
0.067 201.11 200.11 100.03
0.107 201.11 200.11 100.03
0.177 201.11 200.11 100.03
0.318 201.11 200.11 100.03
0.577 201.11 200.11 100.03
1.098 201.11 200.11 100.03
2.128 201.11 200.11 100.03
4.188 201.11 200.11 100.03
8.298 201.11 200.11 100.03
16.508 201.11 200.11 100.03
32.918 201.11 200.11 100.03
这为 WSS 的不同用途提供了信息:研究 WSS CPU 缓存的持续时间短,研究主内存驻留的持续时间长。
由于工作负载可能会有所不同,请注意,这只是显示该工具运行期间 WSS 的增长情况。您可能需要多次收集这些信息以确定正常 WSS 配置文件的外观。
6.1.6。WSS 配置文件图表
绘制前面的两个配置文件:
它向上弯曲,因为它是对数轴。这是线性的(放大的)。虽然看起来很有趣,但这条曲线只是反映了 WSS 样本持续时间,而不是访问分布。分布确实是均匀的,如大约 0.3 秒后的平线所示。此图中的拐点显示了我们可以识别此 WSS 和程序逻辑的统一访问分布的最小间隔。超出这一点的配置文件反映了访问分布。超出这一点的配置文件反映了访问分布,并且对于了解主内存使用情况很有趣。前面的配置文件很有趣,原因不同:了解 CPU 缓存在短时间内处理的工作负载。
6.1.7. 预计持续时间和准确性
以下是您可能想象的此工具的工作方式:
- 重置进程的引用页面标志(即时)
- 睡眠时间
- 读取引用的页面标志(瞬时)
这是真正发生的事情:
- 重置进程的第一页标志
- […重置下一页标志,然后是下一个,然后是下一个,等等…]
- 页面标志重置完成
- 睡一段时间
- 读取进程的第一页标志
- […阅读下一页标志,然后是下一个,然后是下一个,等等…]
- 读完
工作集只应该在第 4 步(预期持续时间)期间进行测量。但是应用程序可以在第 2 步中设置标志之后和第 4 步中的持续时间开始之前接触内存页面。第 6 步中的读取也会发生同样的情况:应用程序可能会在这个阶段在检查标志之前接触内存页面. 因此,第 2 步和第 6 步有效地延长了睡眠时间。大型进程(>100 GB)的这些阶段可能会占用超过 500 毫秒的 CPU 时间,因此 10 毫秒的目标持续时间实际上可以反映 100 毫秒的内存更改。
为了告知最终用户这种持续时间膨胀,该工具提供了估计的持续时间,从第 2 阶段的中点到第 6 阶段的中点进行测量。对于小型流程,这个估计的持续时间可能等于预期的持续时间。但是对于大型流程,它会显示夸大的时间。
6.1.8。精确的工作集大小持续时间
我尝试了一种获得精确持续时间的方法:发送目标进程 SIGSTOP 和 SIGCONT 信号,以便在设置和读取页面映射时暂停,并且仅在预期的测量持续时间内运行。这很危险
6.2. 实验:Linux 空闲页面标志
这是Vladimir Davydov在 Linux 4.3 中添加的一种较新的方法,它引入了 Idle 和 Young 页面标志以实现更可靠的工作集大小分析,并且没有像使用可能混淆内核回收逻辑的引用标志这样的缺点。Jonathan Corbet 再次写了关于这个主题的文章:跟踪实际内存利用率。Vladimir 将其称为空闲内存跟踪,不要与多年前的空闲页面跟踪补丁集混淆,后者在 /sys 中引入了用于页面扫描和摘要统计的 kstaled(未合并)。
这仍然是一种 PTE 访问位的方法:这些额外的空闲和年轻标志仅在内核的扩展页表条目(page_ext_flags)中,用于帮助回收逻辑。
空闲内存跟踪使用起来有点复杂。从内核文档vm/idle_page_tracking.txt:
That said, in order to estimate the amount of pages that are not used by a
workload one should:
1. Mark all the workload's pages as idle by setting corresponding bits in
/sys/kernel/mm/page_idle/bitmap. The pages can be found by reading
/proc/pid/pagemap if the workload is represented by a process, or by
filtering out alien pages using /proc/kpagecgroup in case the workload is
placed in a memory cgroup.
2. Wait until the workload accesses its working set.
3. Read /sys/kernel/mm/page_idle/bitmap and count the number of bits set. If
one wants to ignore certain types of pages, e.g. mlocked pages since they
are not reclaimable, he or she can filter them out using /proc/kpageflags.
I've written two proof-of-concept tools that use this, which are in the wss collection.
6.2.1. wss-v1: small process optimized
这个工具的这个版本一个一个地遍历页面结构,并且只适用于小型进程。在大型进程(>100 GB)上,此工具可能需要几分钟才能写入。请参阅 wss-v2.c,它使用页面数据快照并且对于大型进程 (50x) 更快,以及 wss.pl,它甚至更快(尽管使用引用的页面标志)。
这是一些示例输出,将此工具与早期的 wss.pl 进行比较:
# ./wss-v1 33583 0.01
Watching PID 33583 page references during 0.01 seconds...
Est(s) Ref(MB)
0.055 10.00
# ./wss.pl 33583 0.01
Watching PID 33583 page references during 0.01 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
0.011 21.07 20.10 10.03
The output shows that that process referenced 10 Mbytes of data (this is correct: it’s a synthetic workload).
Columns:
Est(s): Estimated WSS measurement duration: this accounts for delays with setting and reading pagemap data.
Ref(MB): Referenced (Mbytes) during the specified duration. This is the working set size metric.
6.2.2. wss-v1 WARNINGs
这个工具的这个版本一个一个地遍历页面结构,并且只适用于小型进程。在大型进程(>100 GB)上,此工具可能需要几分钟才能写入。请参阅 wss-v2.c,它使用页面数据快照并且对于大型进程 (50x) 更快,以及 wss.pl,它甚至更快(尽管使用引用的页面标志)。
这是一些示例输出,将此工具与早期的 wss.pl 进行比较:
Watching PID 33583 page references during 0.01 seconds...
Est(s) Ref(MB)
0.055 10.00
# ./wss.pl 33583 0.01
Watching PID 33583 page references during 0.01 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
6.2.3. wss-v2: large process optimized
此工具的此版本对系统的空闲页面标志进行快照,这加快了对大型进程的分析,但不是小进程。请参阅 wss-v1.c,它对于小型进程可能更快,以及 wss.pl,它甚至更快(尽管使用引用的页面标志)。
以下是一些示例输出,将此工具与 wss-v1(运行速度慢得多)和早期的 wss.pl 进行比较:
# ./wss-v2 27357 0.01
Watching PID 27357 page references during 0.01 seconds...
Est(s) Ref(MB)
0.806 15.00
# ./wss-v1 27357 0.01
Watching PID 27357 page references during 0.01 seconds...
Est(s) Ref(MB)
44.571 16.00
# ./wss.pl 27357 0.01
Watching PID 27357 page references during 0.01 seconds...
Est(s) RSS(MB) PSS(MB) Ref(MB)
0.080 20001.12 20000.14 15.03
输出显示该进程引用了 15 MB 的数据(这是正确的:这是一个合成工作负载)。
列:
Est(s):估计的 WSS 测量持续时间:这说明了设置和读取页面地图数据的延迟。
Ref(MB):在指定的持续时间内被引用(Mbytes)。这是工作集大小指标。
6.2.4. wss-v2 警告
此工具设置和读取系统和进程页面标志,这可能会占用超过一秒的 CPU 时间,在此期间应用程序可能会遇到稍高的延迟(例如,5%)。考虑这些开销。此外,这会激活一些您以前可能从未执行过的 Linux 4.3 中添加的新内核代码。与任何此类代码的情况一样,存在未被发现的内核恐慌的风险(我没有具体的理由担心,只是偏执)。在实验室环境中测试您的内核版本,并考虑此实验:使用风险自负。
- 实验:MMU 失效
这种方法使 MMU 中的内存页面无效,因此 MMU 将在下次访问时出现软故障。这会导致加载/存储操作将控制权交给内核以服务故障,此时内核只是重新映射页面并跟踪它被访问过。它可以由内核或用于监控来宾 WSS 的管理程序来完成。
7.2. Windows 参考集
微软对此有一个很好的页面:参考集和系统范围对内存使用的影响。一些术语差异:
Linux 常驻内存 == Windows 工作集
Linux 工作集 == Windows 参考集
此方法使用 WPR 或 Xperf 来收集“引用集”,这是对访问页面的跟踪。我自己还没有完成这些,但它似乎使用了 MMU 失效方法,然后是页面错误的事件跟踪。文档记录了开销:
警告:“记录引用集的跟踪可能会对系统性能产生重大影响,因为在清空工作集后,所有进程都必须将大量页面错误地返回到它们的工作集中。”
一旦我使用它,我会用更多的细节更新这个页面。到目前为止,这些是我见过的(除了我写的)唯一用于进行 WSS 估计的工具。
其他
WSS 估计的其他技术包括:
应用程序指标:它取决于应用程序,但有些可能已经将使用中的内存作为 WSS 近似值进行跟踪。
应用程序修改:我已经看到这个研究,其中应用程序代码被修改以跟踪正在使用的内存对象。这会增加大量开销,并且需要更改代码。
CPU 模拟:跟踪负载/存储。应用程序在此类模拟器中的运行速度可能会慢 10 倍或更多。
内存断点:例如调试器可以配置的断点。我预计会有大量开销。
内存观察点:可以建立一种方法来使用它们;观察点最近得到了 bpftrace 的支持。
MMU 页面失效:强制页面在访问时出错,显示正在使用的页面。这可以由内核或用于监控来宾 WSS 的管理程序来完成。
处理器跟踪:以及可以记录加载/存储的类似处理器级功能。处理日志的预期开销很高。
内存总线侦听:使用物理连接到内存总线的自定义硬件和软件来总结观察到的访问。
我还没有看到用于进行 WSS 估计的现成通用工具。这就是促使我编写基于 Linux 引用和空闲页面标志的 wss 工具的原因,尽管每个工具都有自己的警告(尽管没有其他方法那么糟糕)。
转载翻译自: https://www.brendangregg.com

{kind=link}