我之前写过有关FlameScope工具的文章,以及它如何帮助您识别配置文件中的模式,尤其是 CPU 堆栈样本,并从这些模式中生成火焰图。我也在会谈中谈到了 FlameScope 的起源;这是一个快速帖子,也可以在这里分享详细信息。
1. 问题陈述
在 Netflix,我的同事 Vadim 正在调试一个间歇性性能问题,即应用程序请求延迟每 15 分钟短暂增加一次。这是一个大问题。我们特别选择了一项服务来分析,“嗯”。
以下是它在我们的全云监控工具 Atlas(已编辑)中的外观:
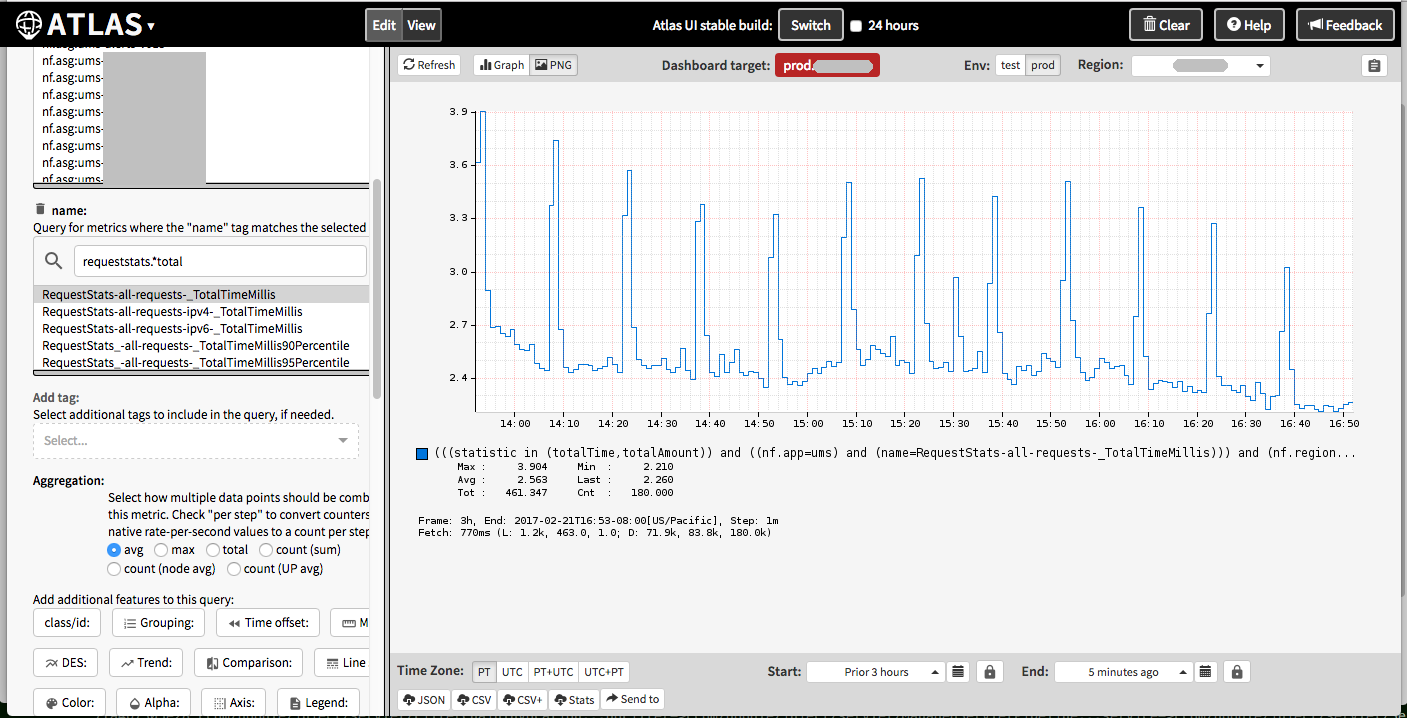
支柱显示延迟显着增加。
我们还查看了许多其他指标,看看是否存在相关性。CPU 利用率确实增加了一点,但是工作负载(以操作率衡量:NumCompleted)并没有增加。
2. 采集样本
Vadim 在观察 Atlas 延迟指标的同时不断收集 3 分钟的性能配置文件。
# perf record -F 49 -a -g -- sleep 180
# perf script > ums.stacks01
他终于在收集配置文件时看到了延迟上升。我们现在有一个 3 分钟的档案要研究。
3.单CPU运行
每 15 分钟左右出现一次延迟听起来像是垃圾收集,但它与 Java GC 活动不匹配。
为了找出问题所在,我想分析perf 脚本输出,它本质上是一个包含时间戳、元数据和堆栈跟踪的样本列表。我一直在研究一个perf2runs工具,该工具可以识别“单 CPU 运行”,我以前曾用它来发现问题(例如我在YOW!演讲开始时讨论的代码缓存)。但我一直在思考其他方法来分割这个输出。
4. 对时间范围进行切片和切块
我想出了另一个简单的工具range-perf.pl ,它可以从perf 脚本输出中过滤时间范围。我已经建立了一个这样的命令行:
$ cat ums.stacks01 | ./range-perf.pl 0 10 | ./stackcollapse-perf.pl | grep -v cpu_idle | ./flamegraph.pl --hash --color=java > ums.first10.svg
然后我循环执行此操作,并为每十秒范围制作单独的火焰图,希望一个看起来不同并解释问题。它看起来很有希望,因为它开始显示出一些变化。然后我尝试了一秒的时间范围,生成了 180 个火焰图,在浏览了其中的许多之后,我们最终发现了问题:周期性的应用程序缓存刷新。但整个过程似乎很耗时,而且粒度为一秒。如果我需要 100 毫秒的火焰图来真正关注扰动怎么办?有太多的火焰图无法浏览(1,800)。
5. 可视化 CPU 利用率低至 20 毫秒
我们知道这与 CPU 利用率有轻微的相关性,并且以某种方式在 perf 配置文件中捕获信息(通过过滤掉空闲样本)。如果我们可以随时间可视化配置文件中的 CPU 利用率,那么我们可以为火焰图选择最有趣的范围。我首先尝试了折线图,但最终发现我的亚秒级偏移热图可视化是最有用的,因为它揭示了更多模式并且很容易可视化到 20 毫秒的范围内。它看起来像这样(svg):
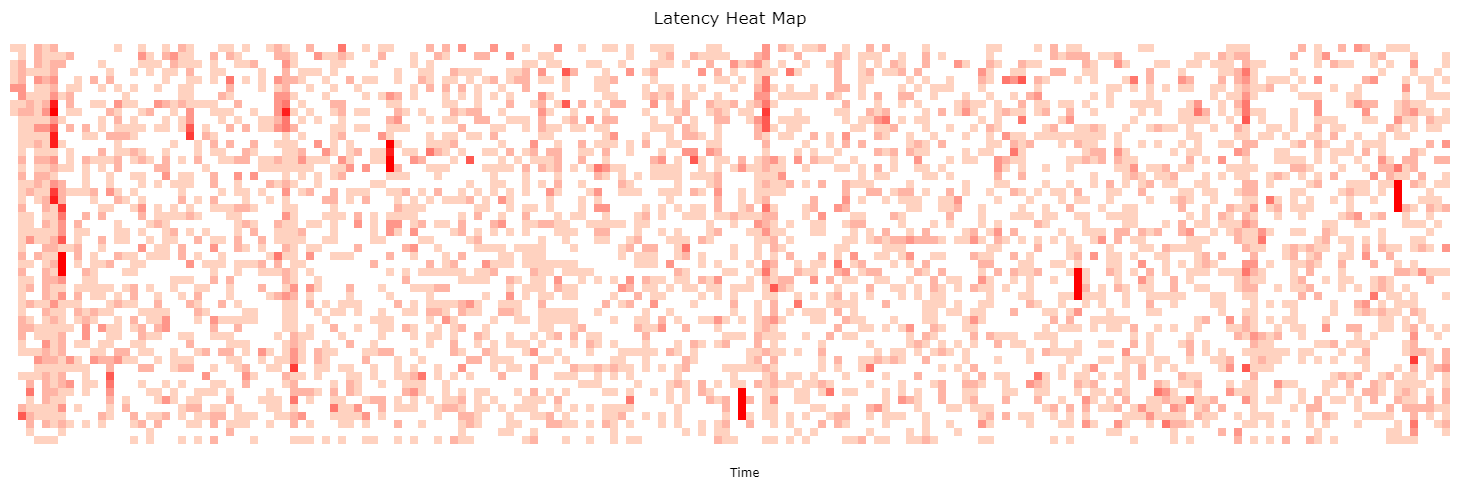
如果单击此 svg,您应该与此可视化有一些交互性,您可以将鼠标悬停在像素上并查看时间和样本计数。它将秒显示为完整的列,从下到上绘制,以及几分之一秒作为行。颜色深度显示有多少 CPU 样本落入每个范围。这些块中的每一个代表大约 20 毫秒的时间。(有关更多解释,请参见亚秒级偏移热图。)
上述可视化中有三种模式:
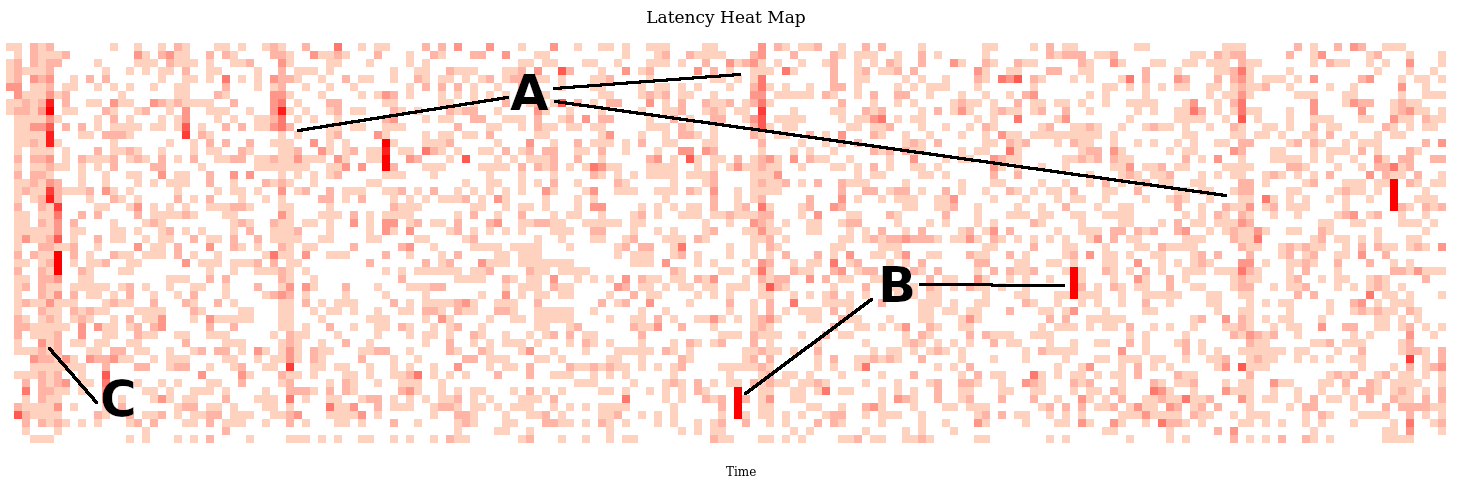
A) 三个间隔 60 秒的较高 CPU 使用率的垂直带
B) 大约 60 毫秒的高 CPU 使用率的各种短脉冲,显示为红色短条纹。
C) 配置文件开始时 CPU 使用率爆发(perf进行一些初始化?当然不是)。
6. 火焰镜
我增强了这种可视化,以便我们可以单击时间范围,它会为该范围生成一个火焰图。我们称这个工具为“FlameScope”(我的原型)。这样,我们很快就确定了所有这些是什么:
A) 伺服(Atlas 监控)
B) 垃圾收集
C) 应用程序缓存刷新
这是 (C) 我们之前通过对 perf 配置文件进行切片和切块发现的艰难方法。在热图中“看到”并选择该范围要容易得多。我在许多其他关于火焰范围的谈话和博客文章中使用了相同的配置文件。
Martin Spier 和我自己(主要是 Martin)随后将其重写为Netflix FlameScope,发布在github 上。
转载翻译自: https://www.brendangregg.com

{kind=link}