这些是粗略的笔记。
一个服务团队正在调试一个性能问题,并注意到它与高分页率相吻合。我被要求提供帮助,并使用了各种 Linux 性能工具来解决这个问题,包括使用 eBPF 和 Ftrace 的工具。这是一篇粗略的帖子,用于分享使用这些工具的这个古老但很好的案例研究,并帮助证明它们的进一步发展。没有编辑、拼写检查或评论。大部分是截图。
- 问题陈述
微服务管理和处理大文件,包括对它们进行加密,然后将它们存储在 S3 上。问题是大文件(例如 100 GB)似乎需要很长时间才能上传。小时。较小的文件(如 40 GB)相对较快,只需几分钟。
云范围的监控工具 Atlas 显示了较大文件上传的高分页率:
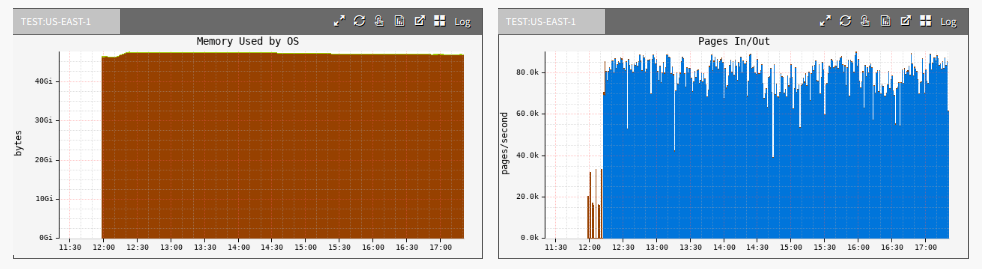
蓝色是pageins(page ins)。Pageins 是一种磁盘 I/O,其中从磁盘读取一页内存,对于许多工作负载来说是正常的。
您也许可以仅从问题陈述中猜出问题所在。
# iostat -xz 1
Linux 4.4.0-1072-aws (xxx) 12/18/2018 _x86_64_ (16 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
5.03 0.00 0.83 1.94 0.02 92.18
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.29 0.21 0.17 6.29 3.09 49.32 0.00 12.74 6.96 19.87 3.96 0.15
xvdb 0.00 0.08 44.39 9.98 5507.39 1110.55 243.43 2.28 41.96 41.75 42.88 1.52 8.25
avg-cpu: %user %nice %system %iowait %steal %idle
14.81 0.00 1.08 29.94 0.06 54.11
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvdb 0.00 0.00 745.00 0.00 91656.00 0.00 246.06 25.32 33.84 33.84 0.00 1.35 100.40
avg-cpu: %user %nice %system %iowait %steal %idle
14.86 0.00 0.89 24.76 0.06 59.43
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvdb 0.00 0.00 739.00 0.00 92152.00 0.00 249.40 24.75 33.49 33.49 0.00 1.35 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
14.95 0.00 0.89 28.75 0.06 55.35
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvdb 0.00 0.00 734.00 0.00 91704.00 0.00 249.87 24.93 34.04 34.04 0.00 1.36 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
14.54 0.00 1.14 29.40 0.06 54.86
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvdb 0.00 0.00 750.00 0.00 92104.00 0.00 245.61 25.14 33.37 33.37 0.00 1.33 100.00
^C
我特别关注 r_await 列:读取的平均等待时间(以毫秒为单位)。阅读通常有应用程序在等待它们;写入可能不会(回写缓存)。33 ms 的 r_wait 有点高,可能是由于排队 (avgqu-sz)。它们是较大的 I/O,大约 128 KB(将 rkB/s 除以 r/s)。
- biolatency
从bcc,这个 eBPF 工具显示了磁盘 I/O 的延迟直方图。我正在运行它以防平均值隐藏异常值,这可能是设备问题:
# /usr/share/bcc/tools/biolatency -m
Tracing block device I/O... Hit Ctrl-C to end.
^C
msecs : count distribution
0 -> 1 : 83 | |
2 -> 3 : 20 | |
4 -> 7 : 0 | |
8 -> 15 : 41 | |
16 -> 31 : 1620 |******* |
32 -> 63 : 8139 |****************************************|
64 -> 127 : 176 | |
128 -> 255 : 95 | |
256 -> 511 : 61 | |
512 -> 1023 : 93 | |
这看起来还不错。大多数 I/O 在 16 到 127 毫秒之间。一些异常值达到 0.5 到 1.0 秒的范围,但同样,在早期的 iostat(1) 输出中可以看到这里有相当多的排队。我不认为这是设备问题。我认为这是工作量。
- bitesize
因为我认为这是一个工作负载问题,所以我想更好地了解 I/O 大小,以防出现一些奇怪的情况:
# /usr/share/bcc/tools/bitesize
Tracing... Hit Ctrl-C to end.
^C
Process Name = java
Kbytes : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 31 | |
16 -> 31 : 15 | |
32 -> 63 : 15 | |
64 -> 127 : 15 | |
128 -> 255 : 1682 |****************************************|
正如 iostat(1) 输出所预期的那样,I/O 主要位于 128 到 255 KB 的存储桶中。这里没有什么奇怪的。
- free
同样来自 60 秒清单:
# free -m
total used free shared buff/cache available
Mem: 64414 15421 349 5 48643 48409
Swap: 0 0 0
剩下的内存不多了,349 MB,但更有趣的是缓冲区/页面缓存中的数量:48,643 MB(48 GB)。这是一个 64 GB 的内存系统,48 GB 位于页面缓存(文件系统缓存)中。
连同问题陈述中的数字,这给了我一个理论:100-Gbyte 文件是否破坏了页面缓存,而 40-Gbyte 文件适合?
- 缓存数据
cachestat是我开发的一个实验性工具,它使用 Ftrace 并已被移植到 bcc/eBPF。它显示页面缓存的统计信息:
# /apps/perf-tools/bin/cachestat
Counting cache functions... Output every 1 seconds.
HITS MISSES DIRTIES RATIO BUFFERS_MB CACHE_MB
1811 632 2 74.1% 17 48009
1630 15132 92 9.7% 17 48033
1634 23341 63 6.5% 17 48029
1851 13599 17 12.0% 17 48019
1941 3689 33 34.5% 17 48007
1733 23007 154 7.0% 17 48034
1195 9566 31 11.1% 17 48011
[...]
这显示了许多缓存未命中,命中率在 6.5% 到 74% 之间变化。我通常喜欢在上世纪 90 年代看到这一点。这就是“缓存破坏”。100 GB 的文件不适合 48 GB 的页面缓存,所以我们有很多页面缓存未命中,会导致磁盘 I/O 和相对较差的性能。
最快的解决方法是迁移到一个能够容纳 100 GB 文件的更大内存实例。开发人员还可以在考虑内存限制的情况下重新编写代码以提高性能(例如,处理文件的部分内容,而不是对整个文件进行多次遍历)。
最快的解决方法是迁移到一个能够容纳 100 GB 文件的更大内存实例。开发人员还可以在考虑内存限制的情况下重新编写代码以提高性能(例如,处理文件的部分内容,而不是对整个文件进行多次遍历)。
- 小文件测试
为了进一步确认,我为 32 GB 的文件上传收集了相同的输出。
cachestat 显示了 ~100% 的缓存命中率:
# /apps/perf-tools/bin/cachestat
Counting cache functions... Output every 1 seconds.
HITS MISSES DIRTIES RATIO BUFFERS_MB CACHE_MB
61831 0 126 100.0% 41 33680
53408 0 78 100.0% 41 33680
65056 0 173 100.0% 41 33680
65158 0 79 100.0% 41 33680
55052 0 107 100.0% 41 33680
61227 0 149 100.0% 41 33681
58669 0 71 100.0% 41 33681
33424 0 73 100.0% 41 33681
^C
这种较小的大小允许服务完全从内存中处理文件(不管它需要多少遍),而无需从磁盘重新读取它。
free(1) 显示它适合页面缓存:
# free -m
total used free shared buff/cache available
Mem: 64414 18421 11218 5 34773 45407
Swap: 0 0 0
正如预期的那样,iostat(1) 显示的磁盘 I/O 很少:
# iostat -xz 1
Linux 4.4.0-1072-aws (xxx) 12/19/2018 _x86_64_ (16 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
12.25 0.00 1.24 0.19 0.03 86.29
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.32 0.31 0.19 7.09 4.85 47.59 0.01 12.58 5.44 23.90 3.09 0.15
xvdb 0.00 0.07 0.01 11.13 0.10 1264.35 227.09 0.91 82.16 3.49 82.20 2.80 3.11
avg-cpu: %user %nice %system %iowait %steal %idle
57.43 0.00 2.95 0.00 0.00 39.62
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
avg-cpu: %user %nice %system %iowait %steal %idle
53.50 0.00 2.32 0.00 0.00 44.18
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvdb 0.00 0.00 0.00 2.00 0.00 19.50 19.50 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
39.02 0.00 2.14 0.00 0.00 58.84
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
[...]
]
- 最后的笔记
cachestat 是这里的杀手级工具,但我应该强调它仍然是实验性的。我为 Ftrace 编写了它,其约束条件是它必须是低开销的并且仅使用 Ftrace 函数分析器。正如我在波多黎各的LSFMMBPF 2019 主题演讲中提到的那样,Linux mm 内核工程师在场,我认为 cachestat 统计数据是如此普遍,以至于它们应该在 /proc 中而不需要我的实验工具。他们指出了正确提供它们的挑战,我认为任何强大的解决方案都需要他们的帮助和专业知识。我希望这个案例研究有助于说明为什么它是有用的并且值得付出努力。
直到内核确实支持页面缓存统计信息(可能永远不会:它们是热路径,所以添加计数器不是免费的)我们可以使用我的 cachestat 工具,即使它确实需要经常维护才能继续工作。
转载翻译自: https://www.brendangregg.com
