不久前,我帮助同事 Vadim 在一个意外的位置调试了 TensorFlow 的性能问题。我觉得这有点有趣,所以我一直想分享它;这是详细信息的粗略帖子。
1.专家的眼睛
Vadim 在这张 CPU 火焰图中发现了一些不寻常的东西(已编辑);你看到了吗?:
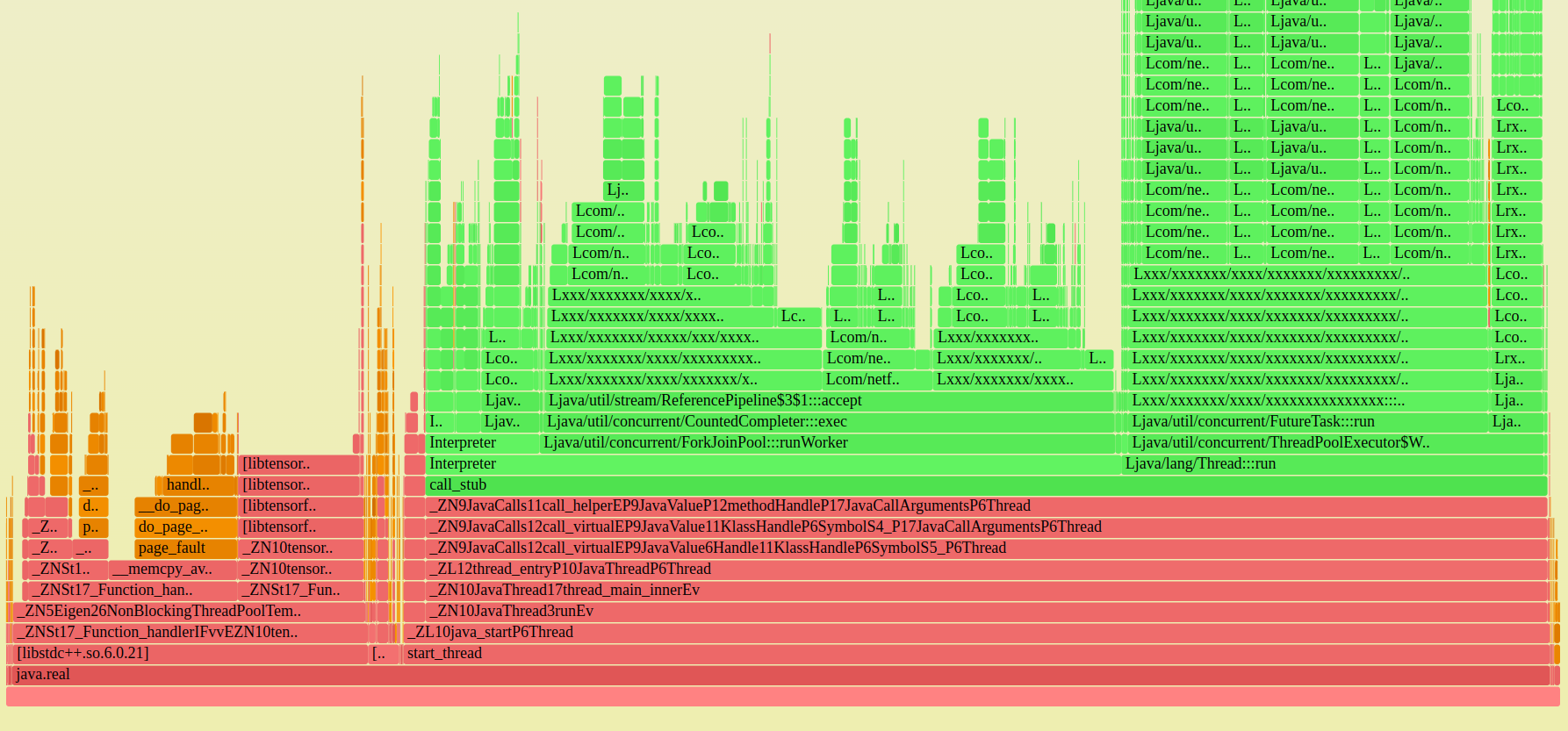
我对他这么快就找到了它印象深刻,但是如果你看足够多的火焰图,更小的不寻常的图案就会开始跳出来。在这种情况下,有一个不寻常的橙色塔(内核代码)。我在这里强调的原因。页面错误占总 CPU 时间的 10%。
在 Netflix,10% 的 CPU 时间在意想不到的地方可能是数千个服务器实例中代价高昂的一个大问题。我们将使用火焰图来追踪 1%s。
- 为什么还是有故障?
浏览堆栈跟踪显示这些来自 __memcpy_avx_unaligned()。好吧,至少这是有道理的:memcpy 会在数据段映射中出错。但是这个进程已经启动并运行了几个小时,而且它的 RSS 页面错误增长不应仍然如此之多。当段和堆是新的并且还没有映射时,您会在早期看到这一点,但是在几个小时之后,它们大多出现故障(映射到物理内存)并且您看到故障减少了。
有时处理页面错误很多,因为它们调用 mmap()/munmap() 来添加/删除内存。我使用我的 eBPF 工具来跟踪它们(mmapsnoop.py)但没有任何活动。那么它仍然是页面错误吗?
它是在做 madvise() 并丢弃内存吗?在火焰图中搜索 madvise 显示它是 CPU 的 0.8%,所以它肯定是,并且 madvise() 正在调用调用故障的 zap_page_range()。(单击火焰图并尝试 Ctrl-F 搜索“madvise”并放大。)
- 过早的优化
我从 mm/advise.c 中阅读了与 madvise() 和 zap_page_range() 相关的内核代码。这表明它为 MADV_DONTNEED 标志调用了 zap_page_range()。(我也可以使用 kprobes/tracepoints 跟踪 sys_madvise() 标志)。
这似乎是一个过早的优化坏了:分配器在它确实需要的内存页面上调用 dontneed。不需要删除虚拟到物理的映射,这很快就会导致页面错误以恢复映射。
4.分配器问题
我建议查看分配器,Vadim 说它是 jemalloc,一个配置选项。他用glibc重建,问题就解决了!
这是固定的火焰图:
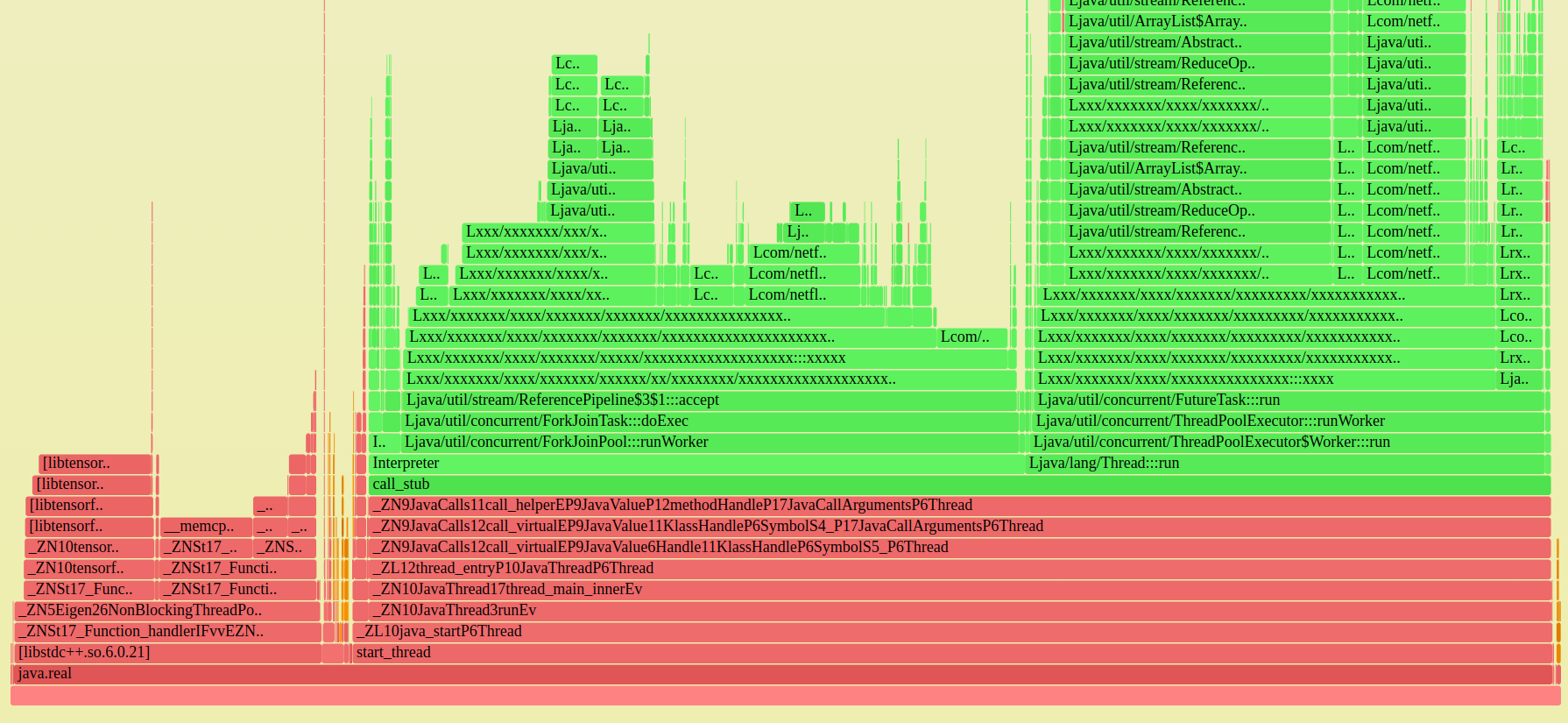
最初的测试显示只有 3% 的胜利(可以通过火焰图验证)。我们希望有 10%!
