使用locust 工具分布式压测(24 个worker)做服务端压测,发压工具 三台腾讯云服务器,8核16G
被压服务器(c++ 服务器) 腾讯云服务器 4核8g 单节点 在压测过程中发现tps 上不去,cpu 利用率低
压测结果记录:
350 用户并发:

400 并发:

500 并发
600 并发

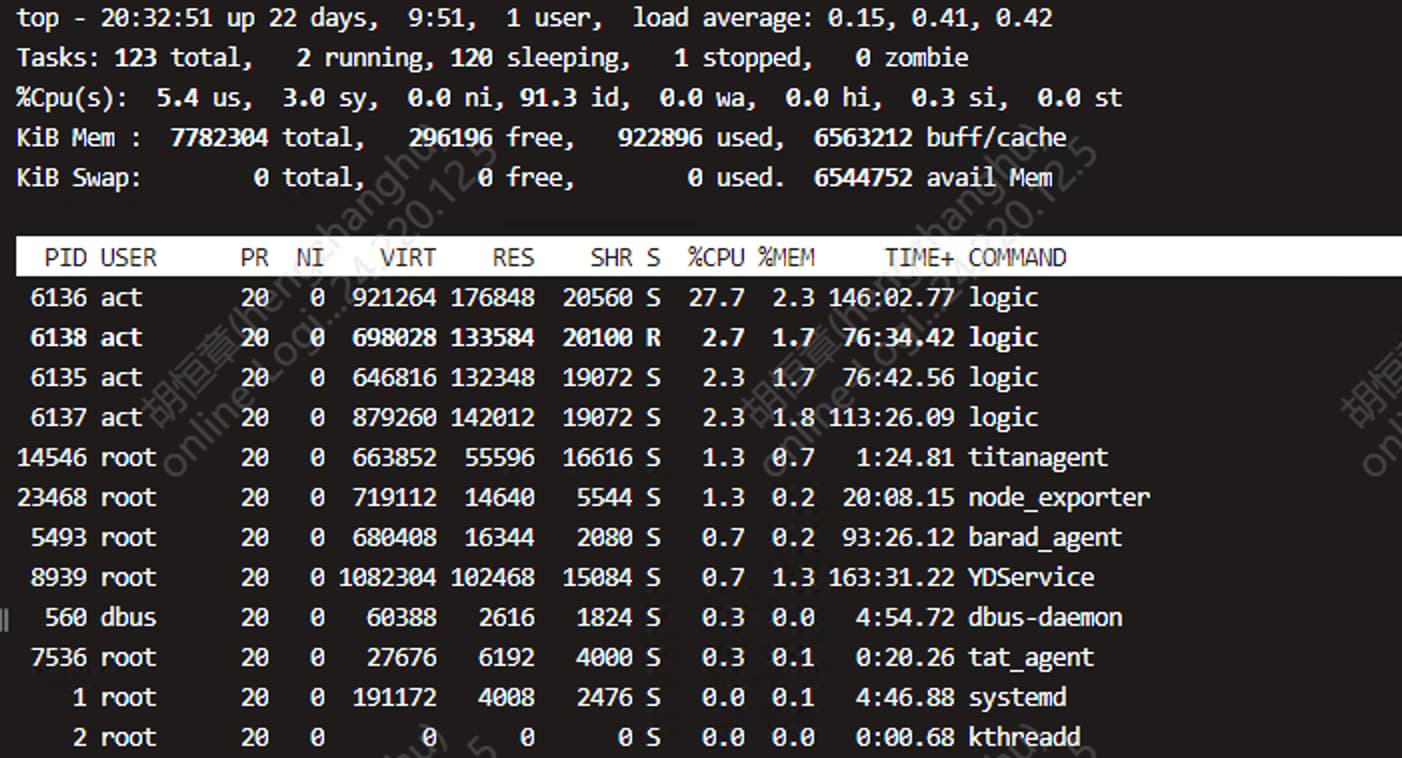
700 并发
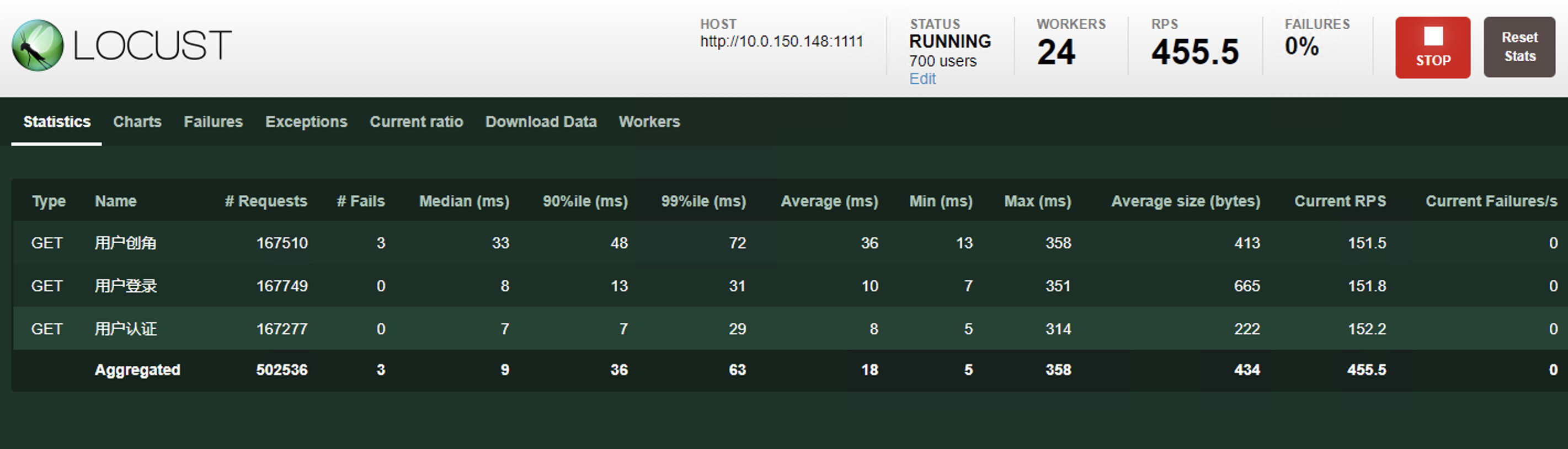
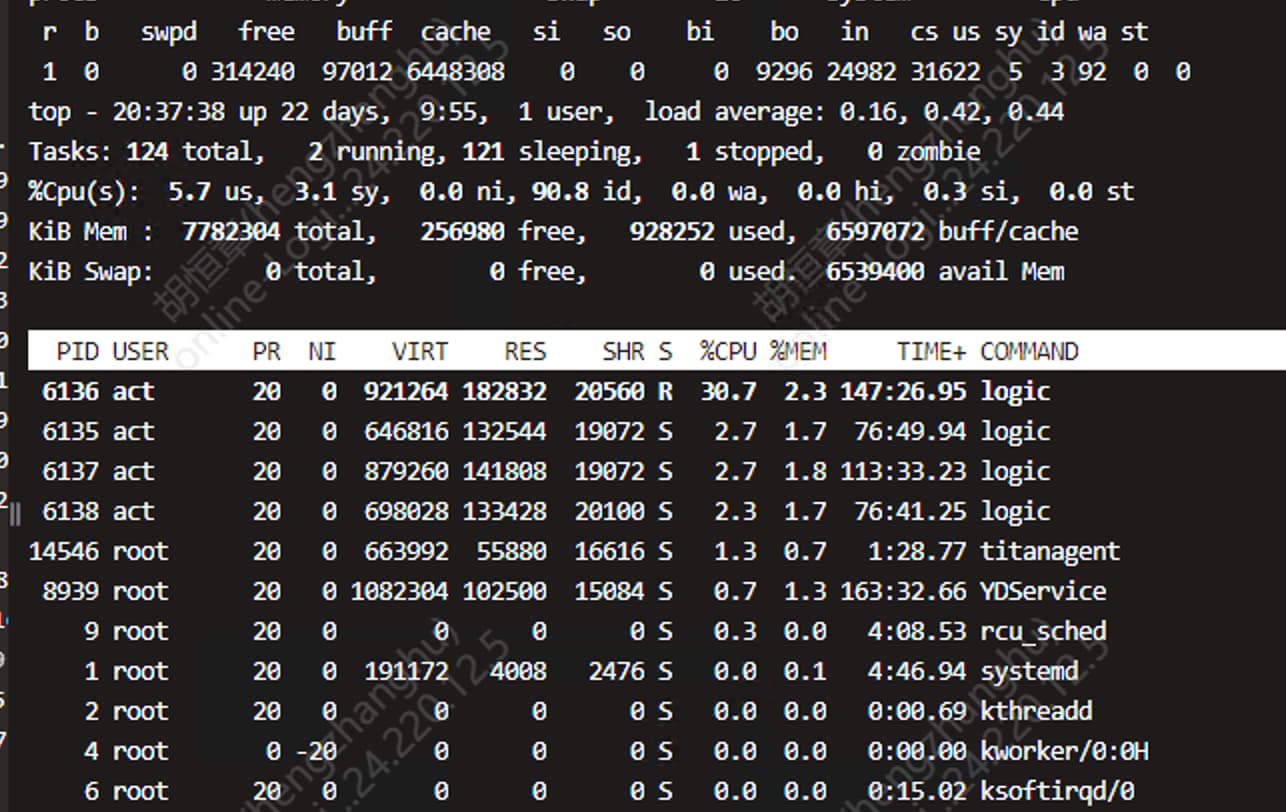
800 并发
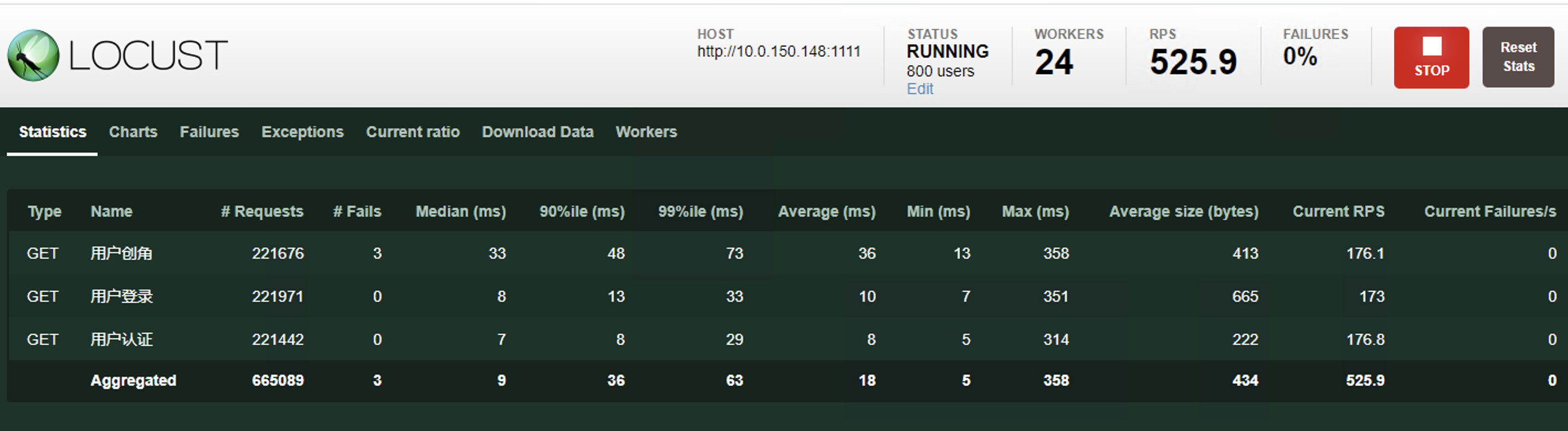
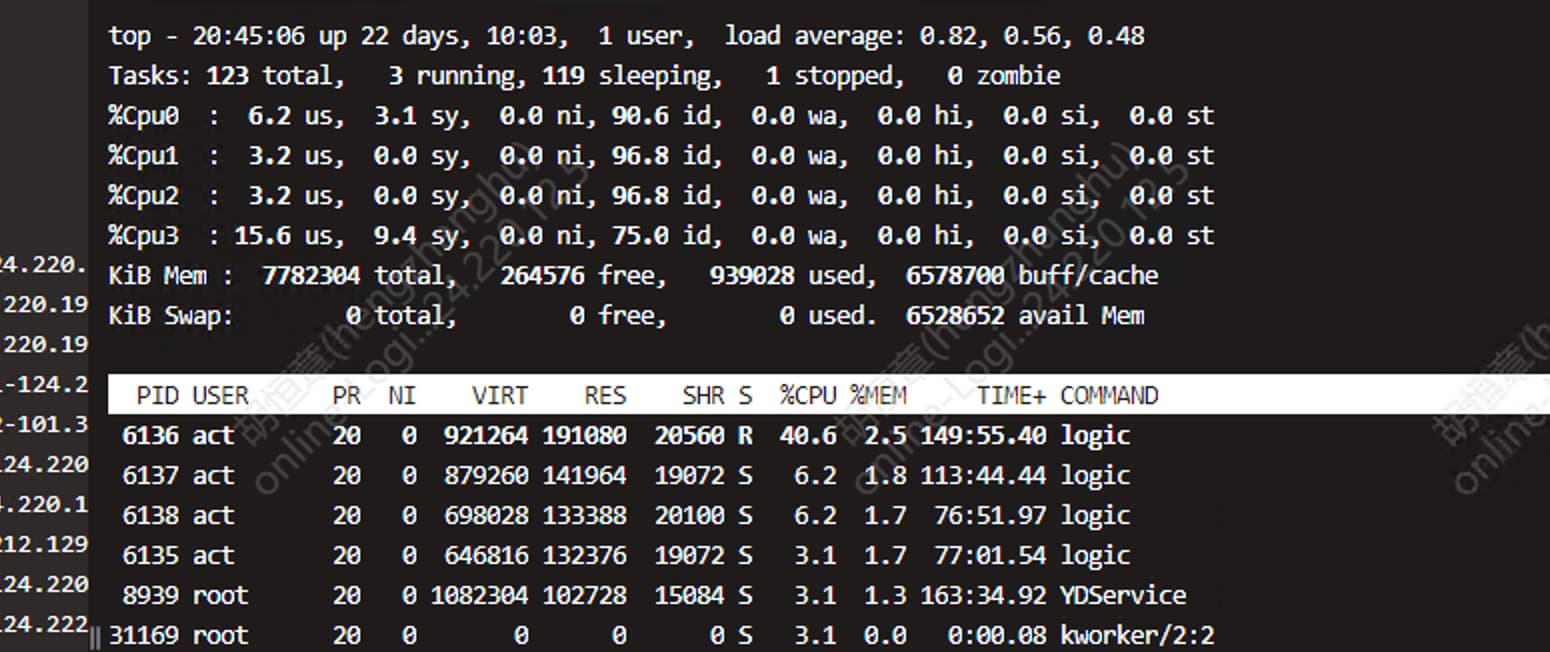
1000 并发

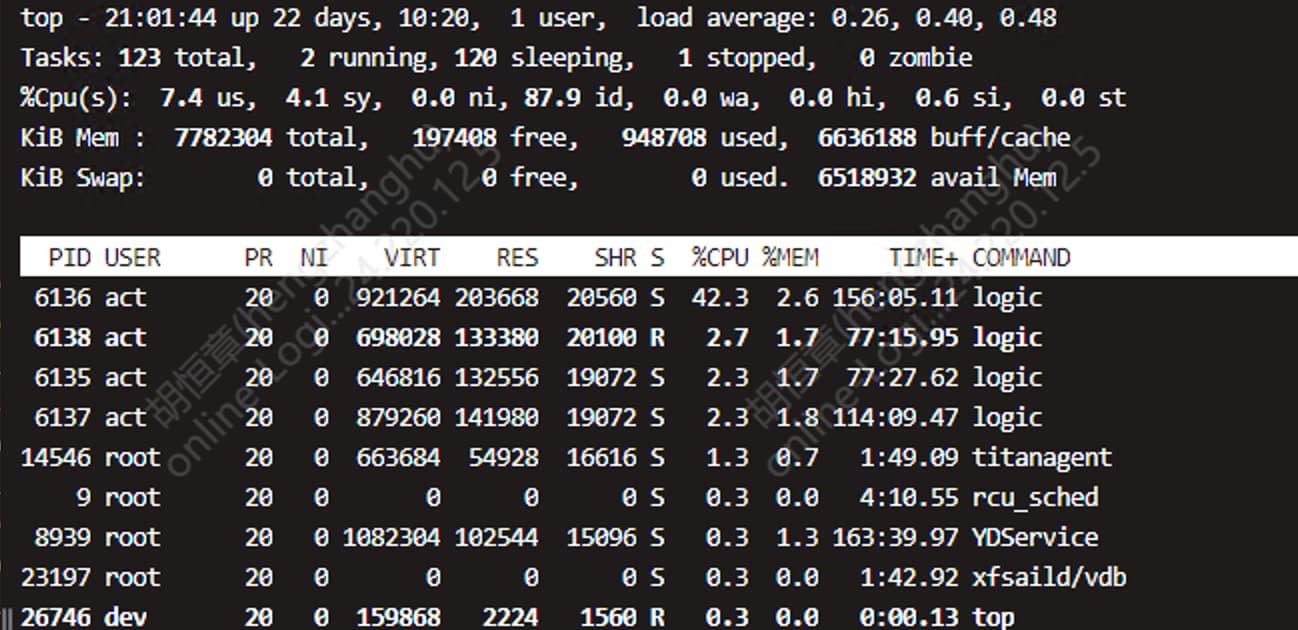
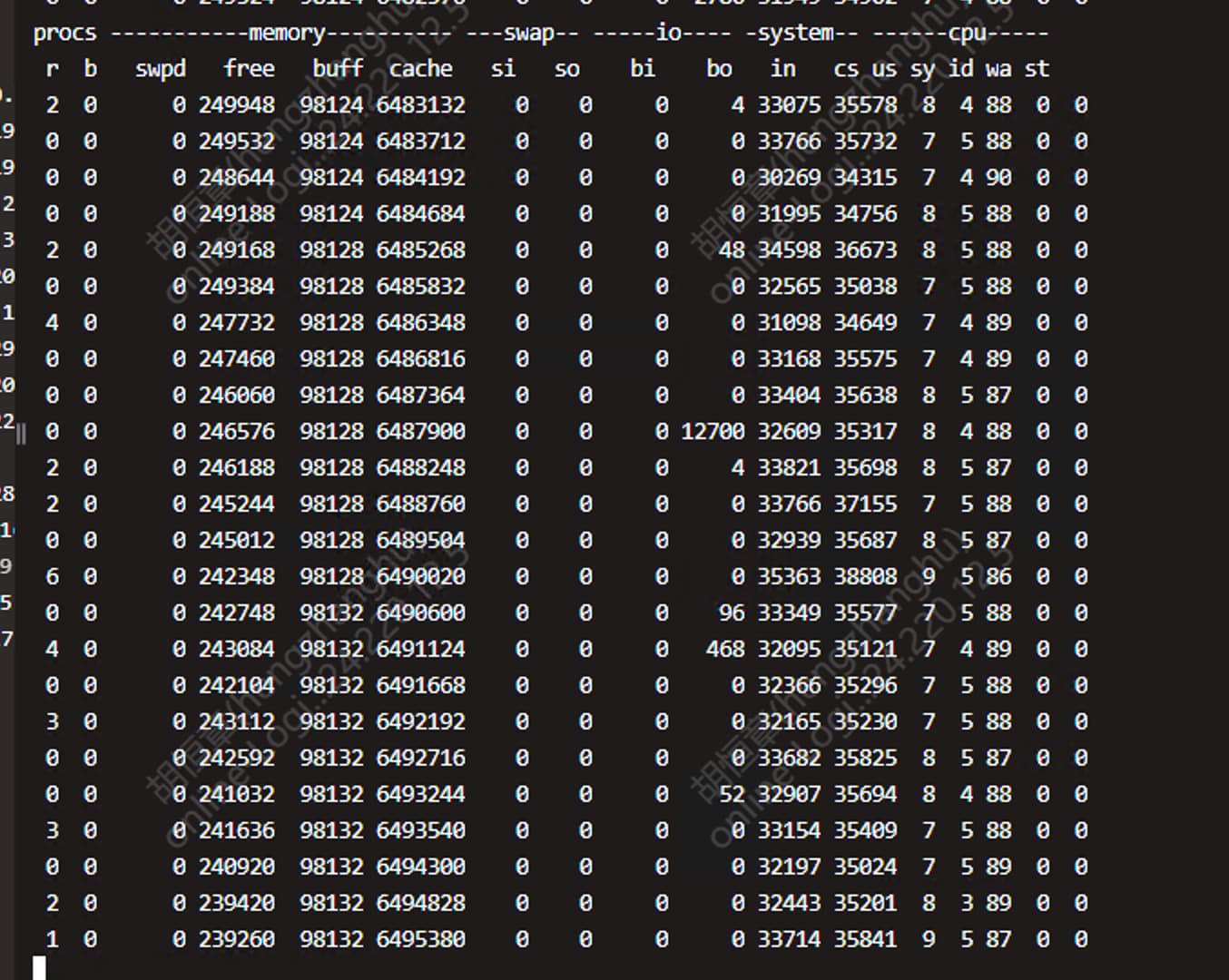
1000 并发下vmstat 中r 、b感觉也还行
使用locust 工具分布式压测(24 个worker)做服务端压测,发压工具 三台腾讯云服务器,8核16G
被压服务器(c++ 服务器) 腾讯云服务器 4核8g 单节点 在压测过程中发现tps 上不去,cpu 利用率低
压测结果记录:
350 用户并发:
400 并发:
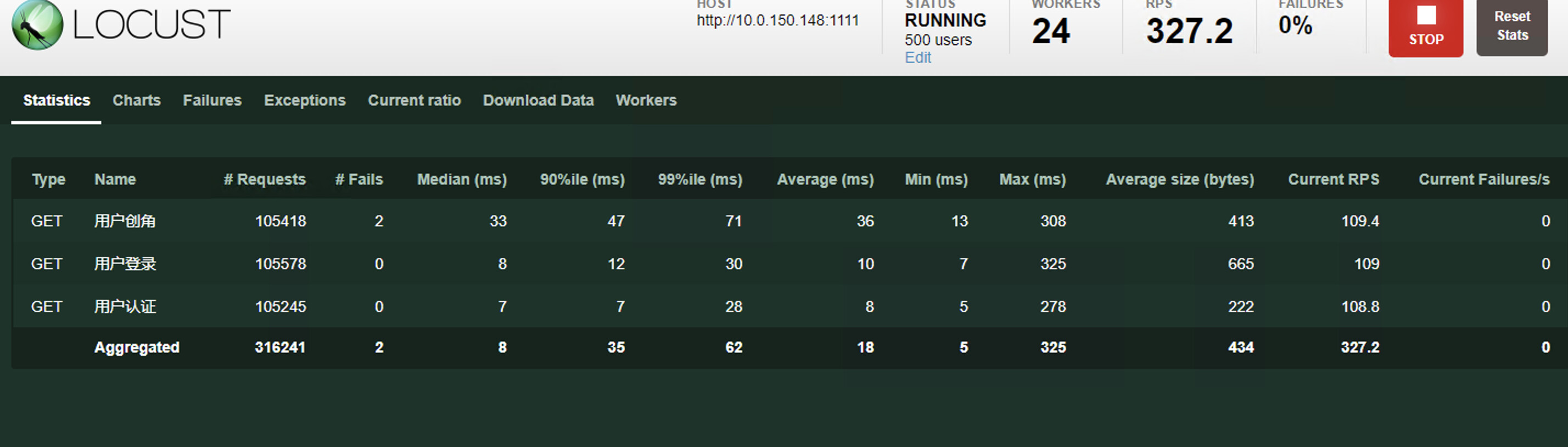
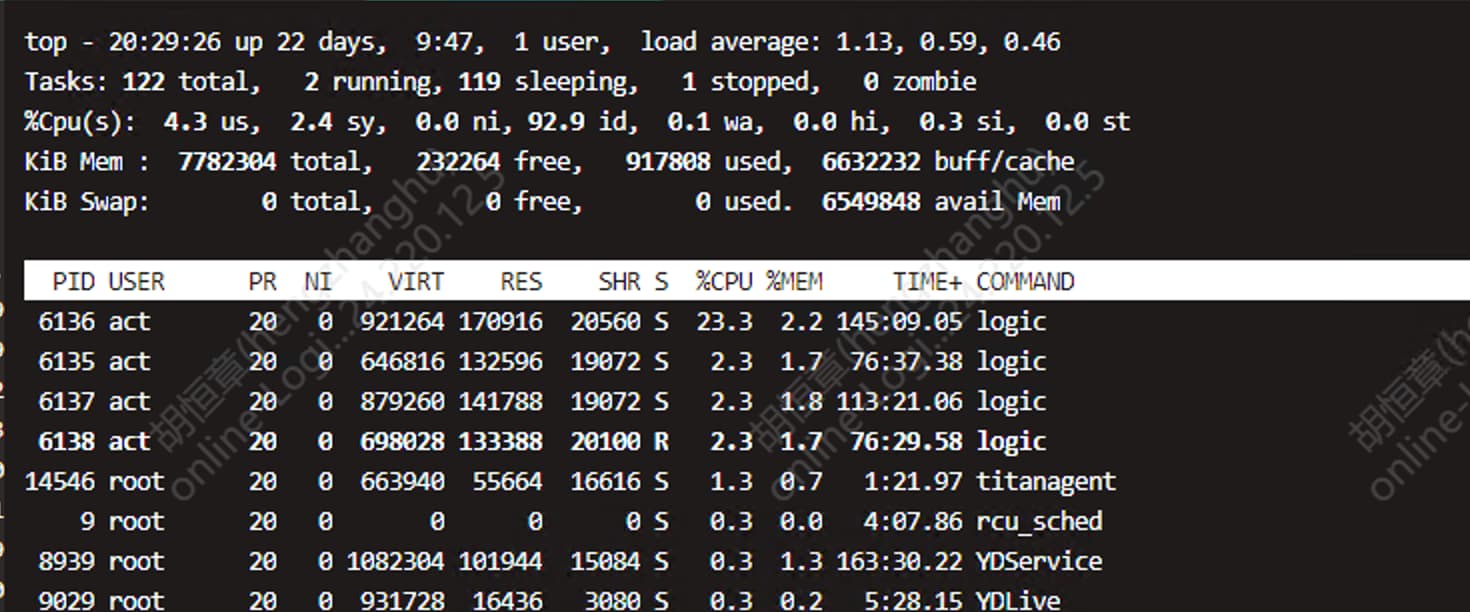
500 并发
600 并发
700 并发
800 并发
1000 并发
1000 并发下vmstat 中r 、b感觉也还行
好歹把并发数和对应的各个资源指标放到一个图里观察下呀。你需要搭建一个监控,一般云服务商应该也有监控的
平均响应时间变化都不大,cpu占用率也是跟随并发逐步增加,没啥问题。为什么不继续增加并发的数量呢?
好的,是有监控平台的我忘了放图上来了 。
是有继续增加并发的, 并发量一直增加到2800 才把cpu 压到100% 峰值在530左右, 就是疑惑按照理论tps = 1/avg * 并发线程数 然后就感觉理论计算跟实际相差有点远。虽然cpu 利用率一直在上升,但是相比压力的提升幅度和使用率提升幅度来看有点差距。所以我疑惑是不是cpu 利用率低导致tps 上不去。另外也有可能跟locust 这个发压工具有关,虽然设置了2800 的用户,但是感觉每秒增加的请求大概在1000多左右
上图再说吧,数据会说明一切的。
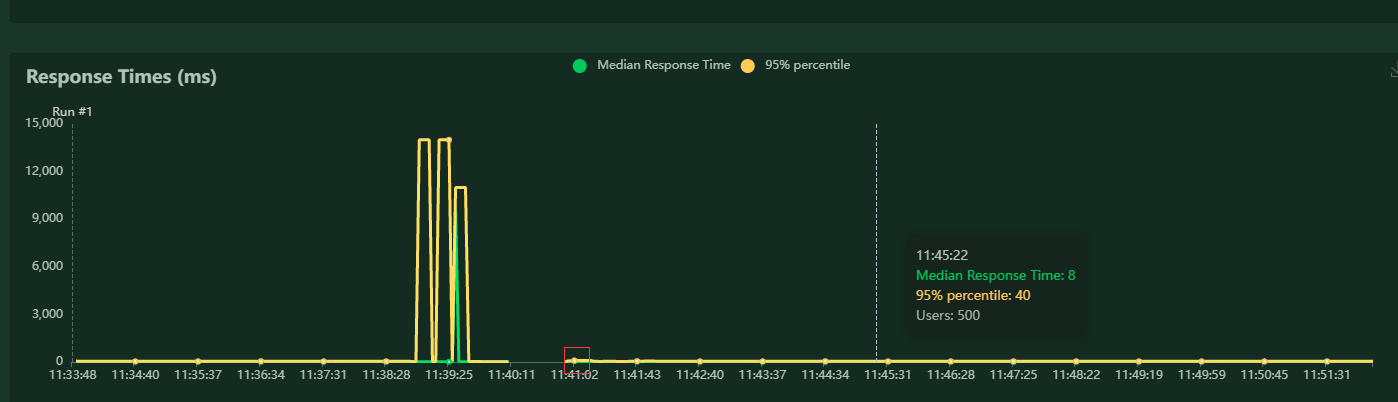
思寒校长,我下面贴了一些图你看下呢,我现在的困惑就是压力和tps 不对应 locust 设置500 并发 每秒增加20 用户 压测5分钟:
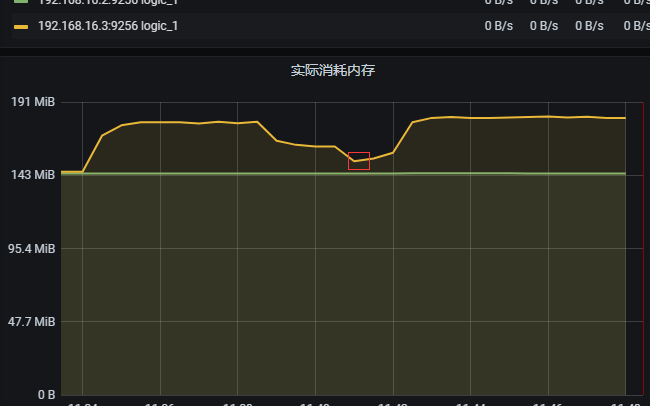
locust tps 和响应时间
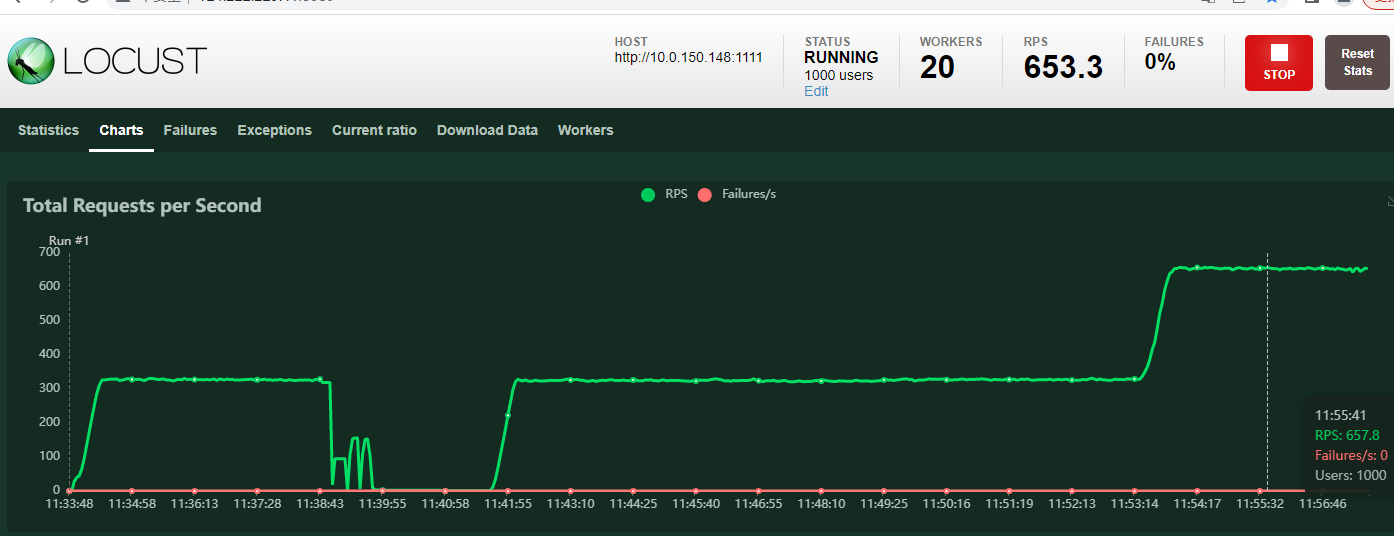
设置1000 用户并发
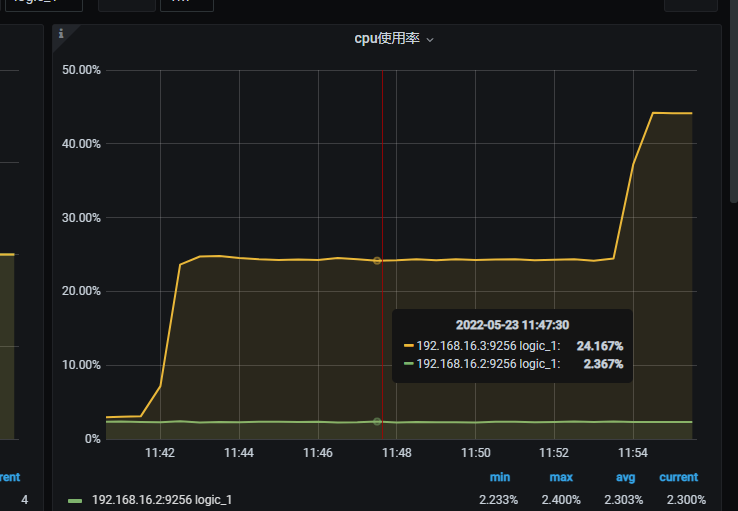
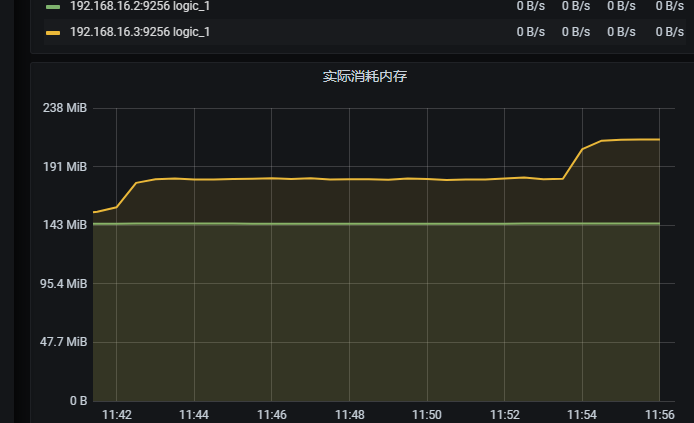
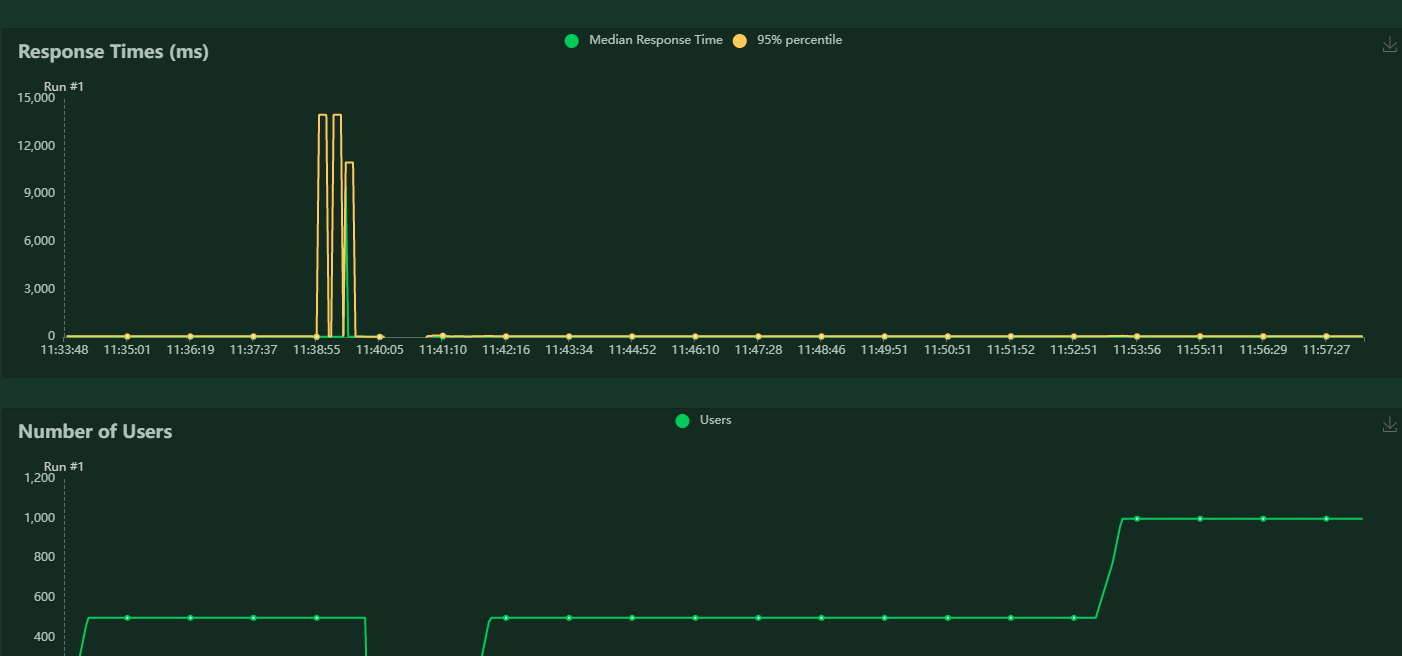
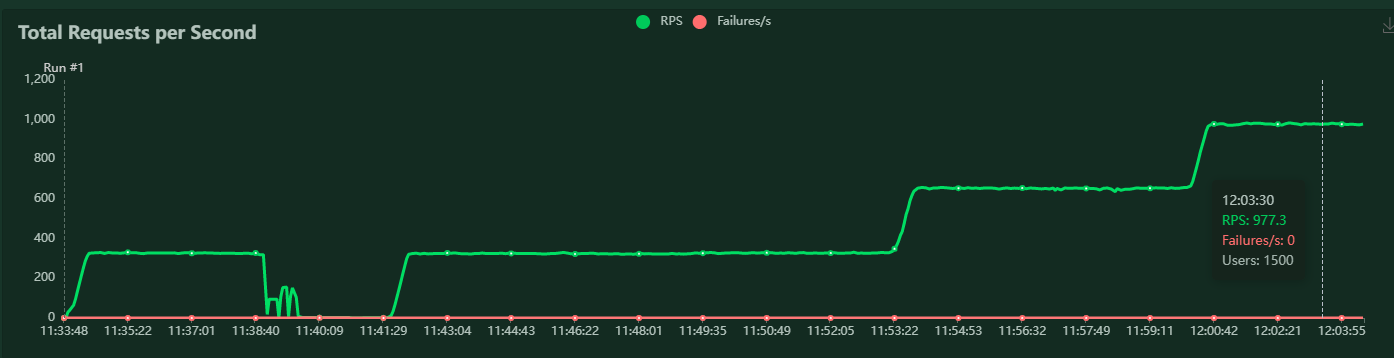
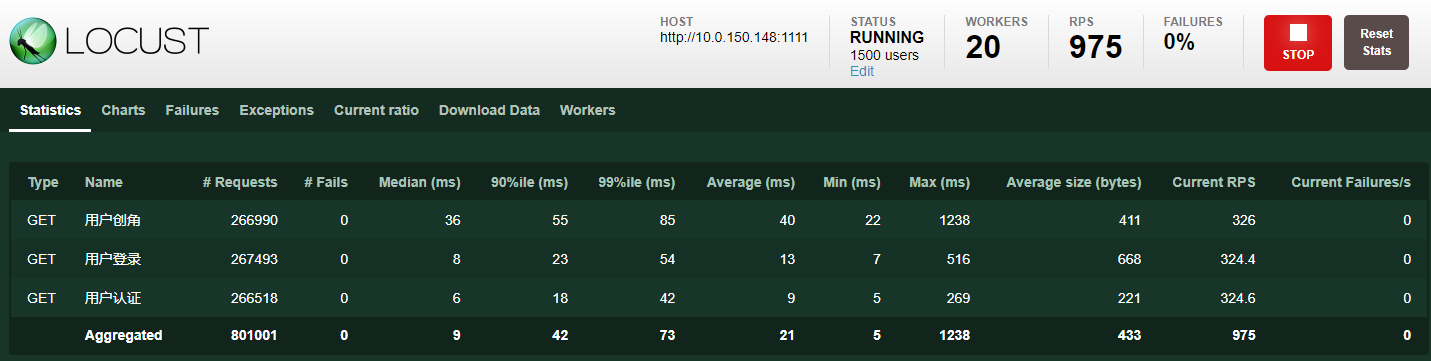
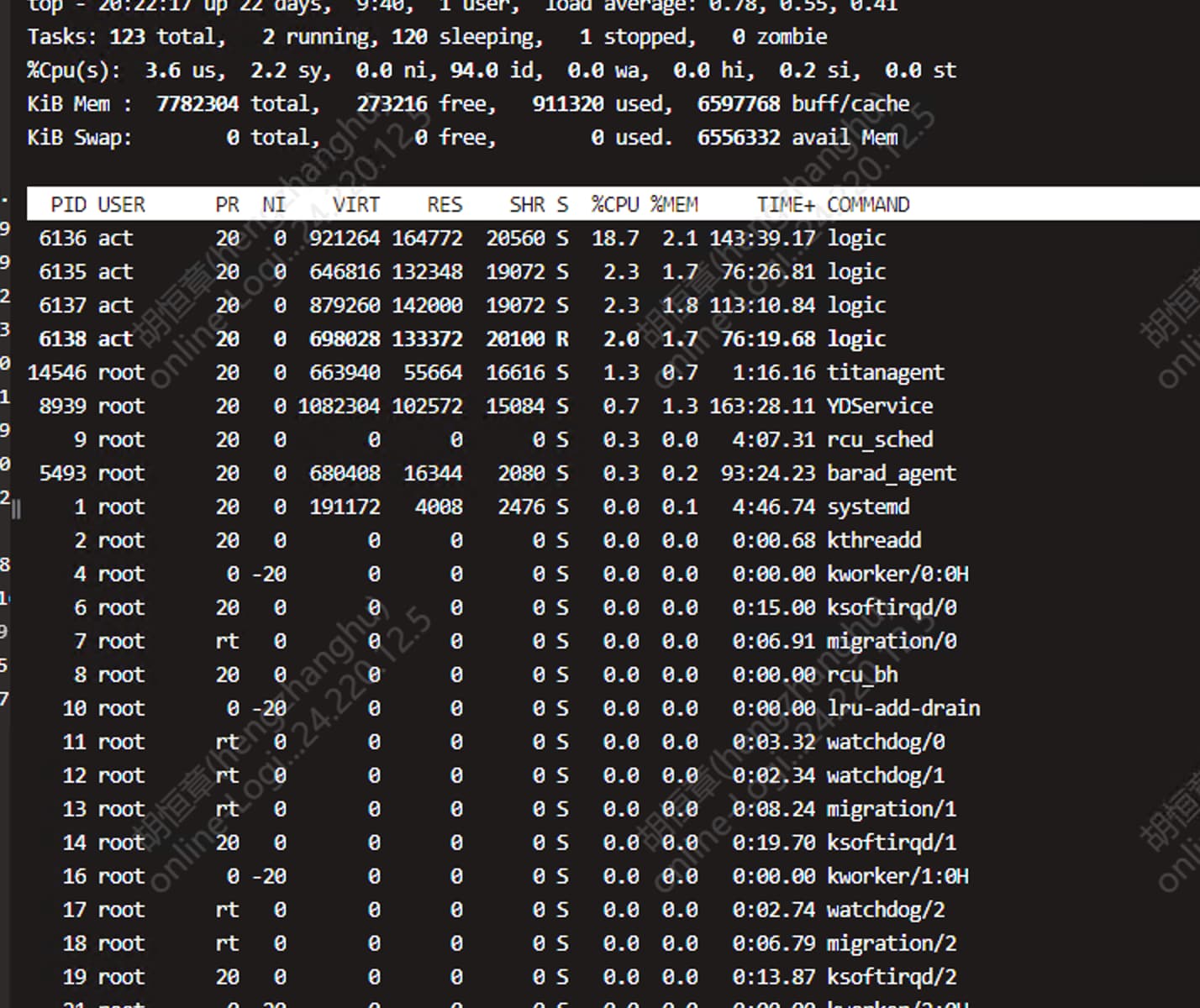
1500 并发
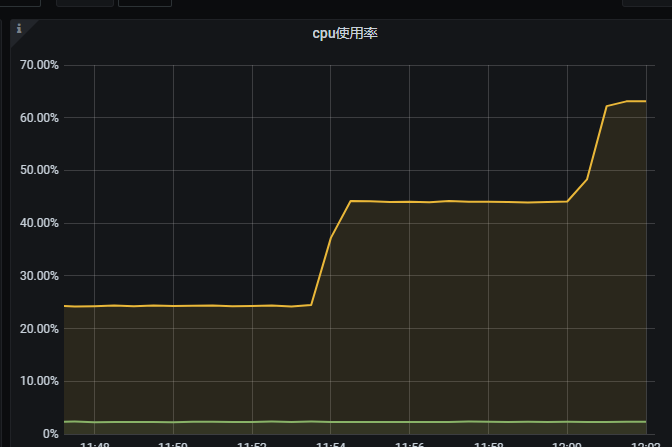
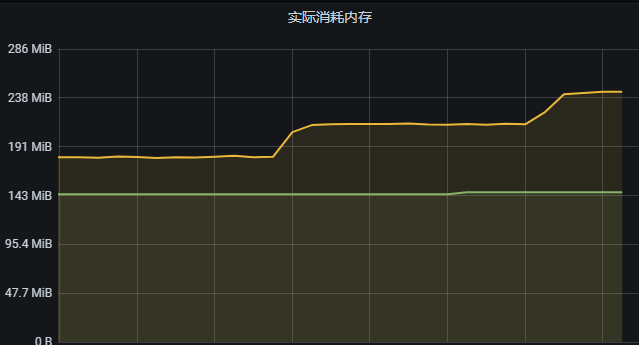
有没有接入日志,看下在数据量到达一定程度后是否有报错
日志之前让开发协助看了一下没有报错日志