导读
无论是网站的API开发、网络爬虫,还是分析抓包数据、前端代码调试,都毫无例外地使用http协议相关知识。深入了解http协议将会为排查问题,服务开发都会有所帮助。
HTTP与DNS、TCP、IP的关系
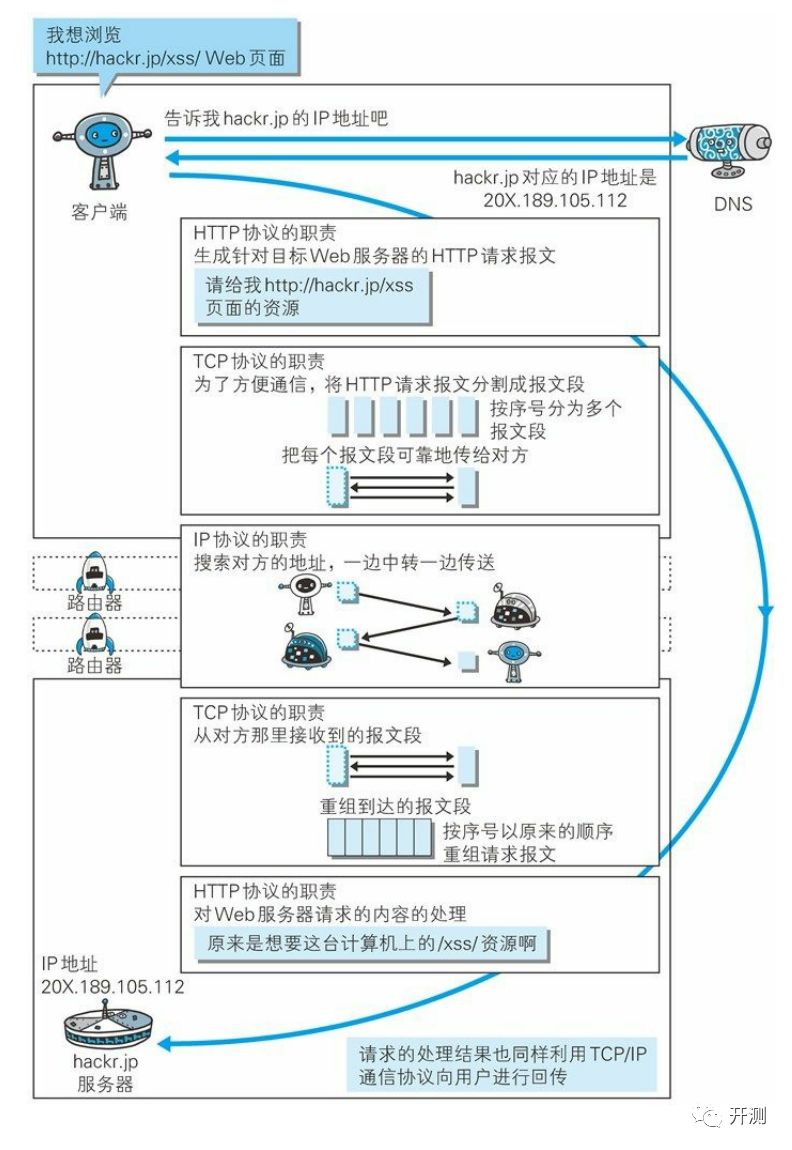
HTTP协议基本结构
一次http过程分为请求和响应,相应的HTTP协议也对应分成两部分,请求报文和响应报文。
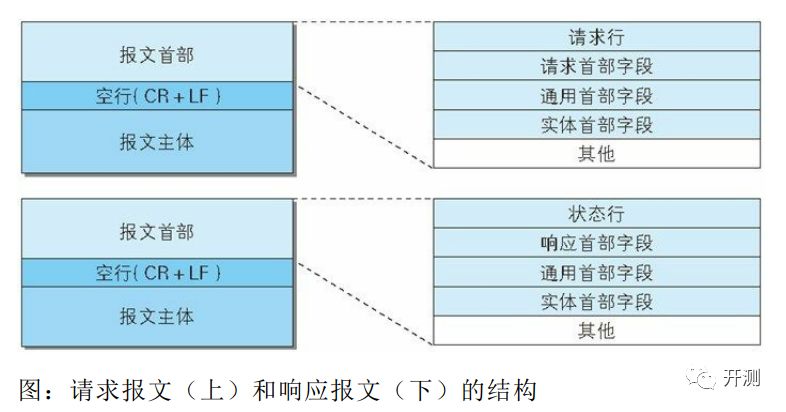
客户端通过请求报文告知服务器,它想要什么/它想做什么;服务端收到之后,根据客户端的要求做出响应。
http协议版本+host+uri标明客户端想要作用的对象和协议版本:
请求方法表明客户端的意图:
**GET :**获取资源;
**POST:**传输实体主体;
**PUT:**传输文件。由于HTTP/1.1的PUT方法自身不带验证机制,任何人都可以上传文件,存在安全问题,所以一般wen网站不使用。如果配合web应用程序的验证机制或者采用REST标准的web可能开放使用。
HEAD:获取报文首部;
DELET:删除文件。存在和PUT一样的安全问题。
**OPTIONS:**询问支持的方法。通过响应报文首部Allow字段返回支持方法列表,例如:Allow:GET,POST,HEAD,OPTIONS
**TRACE:**追踪路径。一个HTTP请求除了需要客户端和服务器参与以外,还会途径一次或多次代理中转,TRACE方法可以查询出请求到源服务器之间的一系列操作。因为不常用且可能会导致XST攻击(跨站追踪),所以更不会开放了。
**CONNECT:**要求使用隧道协议连接到代理。为使用SSL(Secure Sockets Layer)和TLS(Transport Layer Security)提供了条件。
请求首部包含请求的其他要求细节和协商。
HTTP协议设计原理
http协议具有以下特点:
无连接,无状态:前后两次http请求独立无关,互不知晓。
明文传输:协议本身不对传输内容做加密处理。
简单快捷,使用场景比较多。
正是因为它的无连接所以简单,但是也由于无连接也带来了两个问题:
1. 一次HTTP请求完成,就断开,如下图,造成无谓的TCP连接的建立和断开,增加通信的开销。
①、建立TCP连接
②、HTTP请求/响应
③、断开TCP连接
④、建立TCP连接
⑤、HTTP请求/响应
⑥、断开TCP连接
. . . . . .
针对这个问题,提出持久连接的方案:
在建立TCP连接后,保持连接,进行多次HTTP请求/响应串行,再断开连接,达到连接复用的的效果。
①、建立TCP连接
②、HTTP请求/响应
③、HTTP请求/响应
. . . . . .
④、断开TCP连接
为了实现这个效果,需要在首部字段中添加 Connection: keep-alive,表明是持久连接。在HTTP/1.0中默认使用的是keep-alive模式。
在这个解决方案的基础上上,有另一个解决方案:pipelinling(管线化技术)。
①、建立TCP连接
②、HTTP请求1
③、HTTP请求2
④、HTTP请求2
⑤、HTTP请求1
. . . . . .
⑥、断开TCP连接
与持久连接相比,pipelinling将HTTP请求的串行一定程度上改成并行。不需要等待一个HTTP完整处理后,再进行下一个,可以同时发送多个请求出去。(但各大浏览器有些不支持/默认关闭)
2.网站用户登录状态无法保持。
为了解决这个问题,引入了Cookie技术。涉及Set-Cookie和Cookie两个头。
在用户登录的时候,服务端生成一个session存储在服务端,将session的id作为Cookie的value,通过Set-Cookie返回。
避免浏览器收到后,会将Cookie存储起来。发送请求时,会在请求首部中,将请求相同域下的cookie都传回服务端。服务端通过登录Cookie的name拿到对应的值(Session id),去找session,如果能拿到,则说明用户已经登录过。
Cookie:name=value; name2=value2;…;
01.首先,它对报文主体支持压缩
请求时,通过Accept-Encoding表明客户端自己支持什么样的压缩方式,通常是一个列表;
通过Content-Encoding字段表明报文中主体的压缩方式,收到主体一方通过改压缩方式进行解压;
Accept-Encoding:gzip,deflate
Content-Encoding:gzip/compress/deflate/identity/br 中之一
02分块传输
正常请求会将响应一次性返回,使用Content-Length标识整体长度。
如果响应过大或结果是逐步生成的,不能立刻获取到最终的整体长度时,就可以使用分块传输。例如文件传输等。
涉及响应首部Transfer-Encoding: chunked/identity,标识是分块传输,在接收端需要再组装。
03缓存的支持
通过支持缓存机制,减少请求或减少需要传输的内容,达到客户端获取数据速度的提升。
主要通过Cache-Control首部来控制缓存行为,主要配置指令如下
缓存请求指令(常见):
使用例子:浏览器的强缓存和协商缓存的使用。
浏览器在请求某一资源时,会先获取该资源缓存的header信息,判断是否命中强缓存(cache-control和expires信息),若命中直接从缓存中获取资源信息,包括缓存header信息,不会发送网络请求。
如果没有命中强缓存,浏览器会发送请求到服务器,请求会携带第一次请求返回的有关缓存的header字段信息(Last-Modified/If-Modified-Since和Etag/If-None-Match),由服务器根据请求中的相关header信息来比对结果是否协商缓存命中;若命中,则服务器返回新的响应header信息更新缓存中的对应header信息,但是并不返回资源内容,它会告知浏览器可以直接从缓存获取;否则返回最新的资源内容。
协商缓存有两套请求header的原因:
Last-Modified/If-Modified-Since:这套是通过最近修改时间来判定的,当客户端和服务端时间相差较大时,就会导致缓存失效。因此提出另一套,If-Modified-Since和Etag/If-None-Match,通过一个校验码来判断资源是否有效,一旦资源修改,这个校验码也会变化。
使用浏览器时,可以通过Ctrl+f5或者chrome 开发者模式勾选Network下的Disable cache,强制请求不命中本地强缓存。命中强缓存,返回200(from Cache)。使用f5,可以清除协商缓存。命中协商,返回304(not modified)。
HTTP协议除了考虑到上述传输速度方面以外,还对丰富的数据类型也做了一些工作:
01.对multipart对象集合的支持
随着web发展,通常一个页面上同时充斥着文本、文件等多种类型的数据,需要同时提交。
为了支持这类multipart对象集合的传输,HTTP提供了Content-Type的multipart/form(web表单)、multipart/byteranges (包含多个范围内容时,使用)
02.部分内容的范围请求支持
应用场景:对于大的响应返回,例如文件下载等,如果在下载中途,由于网络等原因,导致失败时,重试请求就只能从头开始下载。针对这样的情况,HTTP协议提供一个Range请求首部字段,可以进行自己想要部分的请求,以实现断点续传的功能。
Range :start-end 客户端通过start和end两个数值表明要请求的内容范围;除了请求中要加上Range之外,服务端需要对其进行支持,如果服务端不支持范围请求的话,则会将整个结果都一起返回。如果服务端支持,则会返回206,且响应首部也会通过Content-Range: bytes start-end/size 标明返回主体的范围。
03内容协商,返回最适合的内容
由于本地化等要求,需要在不同区域有一些个性化的设置。例如页面的展示语言,英文还是中文等。
在HTTP协议中有一组请求header来进行客户端和服务端的内容协商。
Accept: 告诉服务端,自己能够处理的媒体类型和相对优先级,例如:text/html,text/plain…
Accept-Charset: 客户端支持的字符集和字符集优先级,例如:iso-8859-5,unicode-1-1;q=0.8
Accept-Encoding: 客户端支持的内容压缩编码和优先级,例如:gzip,deflate
Accept-Language: 客户端支持的自然语言集和优先级,例如:zh-cn,zh;
与之对应的的响应header有:
Content-Type: 响应主体的媒体类型;
Content-Encoding: 响应主体的压缩编码;
Content-Language: 响应主体的自然语言集;
响应状态码主要分为以下五大类
① 接收请求正在处理中
② 请求正常处理完毕
③ 重定向,需要附加操作已完成请求
④ 客户端错误,无法处理的请求
⑤ 服务端错误,处理出错了
响应状态码主要分为以下五大类
① 204 : no Content 响应无主体,这类请求不会导致浏览器页面更新
② 206:Partial Content,Range请求使用
③ 304 : Not Modified 命中协商缓存
④ 400 : Bad Request 请求报文语法错误
⑤ 403 : Forbidden 服务器拒绝访问,未获取到访问权限等导致
⑥ 404 : Not Found 资源找不到
⑦ 500 : 服务器错误
⑧ 503 : Service Unavailable 服务端超负载或者正停机维护无法处理请求。
HTTP拓展协议与HTTP/2
以上是在HTTP/1.1的基础上的一些内容,HTTP/1.1仍然存在很多不足,最显著的就是数据变化展示实时性带来的性能瓶颈。
在facebook和Twitter这类SNS网站上,在短暂的时间内,就会产生大量新的数据。为了尽可能将这些更新的数据展示出来,需要在服务端一有数据更新,就直接把更新的数据展示到用户页面。
对于HTTP协议来说,为了及时知道服务端的更新,就需要频繁地请求询问,造成徒劳的通信。
以下就是这个问题处理时HTTP的瓶颈
① 一条连接上只可发一个请求;
② 请求只能从客户端开始,客户端只能接收响应指令;
③ 请求/压缩首部不压缩发送;
④ 每次互相发送相同的首部造成浪费较多;
⑤ 非强制压缩发送;
除了上述的解决方案以外,HTTP协议本身,在HTTP/2.0版本也从这个角度,改善Web的速度体验。
HTTP/2.0的特点
1. 二进制分帧层
在应用层(HTTP2.0)和传输层(TCP or UDP)之间增加一个二进制分帧层,将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码 ,其中HTTP1.x的首部信息会被封装到Headers帧,而我们的request body则封装到Data帧里面。
使得在不改动HTTP 的语义的条件下,实现了可以承载任意数量的双向数据流连接,突破上一代标准的性能限制,改进传输性能,实现低延迟和高吞吐量。
2.首部压缩
在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送;通信期间几乎不会改变的通用键-值对(用户代理、可接受的媒体类型,等等)只需发送一次。如果首部发生变化了,那么只需要发送变化了数据在Headers帧里面,新增或修改的首部帧会被追加到“首部表”。
3.所有的HTTP2.0的请求都在一个TCP链接上
通过让所有数据流共用同一个连接,可以更有效地使用TCP 连接,让高带宽也能真正的服务于HTTP的性能提升。
4.请求优先级
5.服务端推送
- 《图解HTTP》
2.博客《HTTP2.0的奇妙日常》

转载自 360质量效能
