有同事报他的机器上nginx存在内存泄露,都吃了4G内存没法忍了,于是赶紧查一查。
问题定位
1、先top -u work 查看进程内存占用情况,确认确实是占了4G没法忍了(下图只是整理文档时补的示例)。

2、ps -ef | grep nginx | grep -v grep | grep work
查看nginx进程确认是业务的nginx的某个worker子进程疑似存在内存泄露占了大量内存。
3、发现只有部分worker进程占用内容很大,并不是全部。cat error.log定位为什么不是worker进程都内存增大,只是个别worker进程内存占用很大?

4、发现并不是那个子进程没有内存泄露,而是那个子进程频繁被kill,然后master又重启新的子进程。
通过:dmesg | grep pid ,查看系统日志。确认那些内存占用低的worker进程是被oom kill了,然后被master又重启新的子进程。

5、确定是指定进程内存泄露后,查看该进程的内存分配,定位泄露信息。
①.通过 pmap -x pid dump出该进程的内存分配,确认确实存在超大块内存分配。
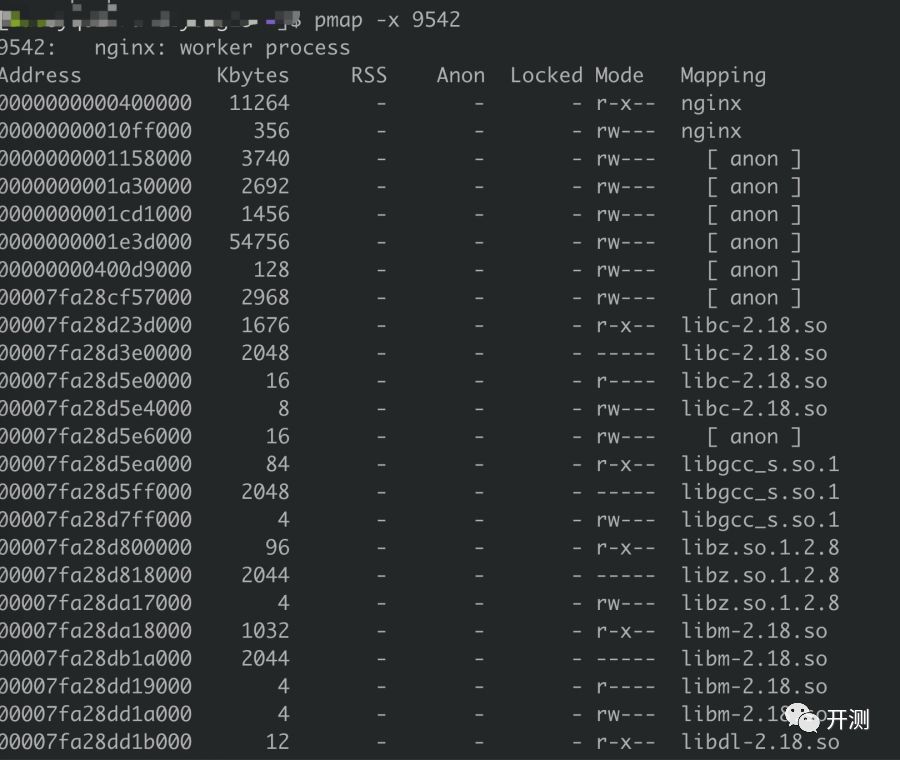
②.通过 cat /proc/pid/smaps查看内存段的具体起始位置。

③.通过gdb dump出那段内存存储内容。
gdb -p 42102
dump binary memory ./memory2.log 0x7fa1d0b57000 0x7FA1D0B70000

④.查看dump出的内容,发现是一个业务研发的nginx扩展存储的内容,确认是该扩展错在内容泄露。
- 问题明确后,具体修复问题就简单了,对应扩展修复问题后重新上线完成修复。
Linux进程内存分析常用工具命令
**top:**查看机器整体内存使用情况和各进程内存使用情况
**RES:**常驻内存,一般比较关心这个
**SHR:**共享内存
**VIRT:**虚拟内存
**DATA:**数据占用内存
**pmap:**pmap -x pid dump 进程的内存分配情况
**mtrace:**可以跟踪记录进程的内存分配
**gdb -p pid:**连接到进程
**cat /proc/pid/smaps:**查看内存块具体开始结束位置
**dump binary memory ./out.log 0x7fa1d0b57000 0x7FA1D0B70000:**dump出指定位置存储的内容
参考文献

