后台和服务端开发,一般会有很多服务需要监控和维护。有的时候,运维资源有限,再加上服务还没有达到一定的规模,服务前期都要靠开发自己运维维护。
一般情况,我会在每个服务中写个监控报警邮件,当服务挂了就发邮件提示。但这并不能解决问题,第一,每次新写一个服务,特别是分布式系统,一下几十台机器,都要加个监控报警,重复造轮子;第二,有些是需要借助第3方服务的,改源码也很浪费时间。基于上面的各种原因,我打算自己写个监控报警的模块服务,一劳永逸,但平时业务太忙,一直没有时间,而且我的代码功力还不太成熟,架构也是一知半解,做出来好不好用也未可知。最近接触到zabbix这个运维工具,发现非常好用,分分钟解决了上述我的问题,也不用我写代码重复造轮子了。这个工具不仅能监控服务,还能监控主机的各项指标,比如进程是否存活,主机硬盘,性能等等各项指标,所以这个工具是万能的运维工具。此外,我不是专业运维,只是找合适的工具协助排查问题,据说现在专业运维已经不使用这个工具了,他们用的是google的prometheus工具。
zabbix工具简介
言归正传,今天给大家介绍的是zabbix这款工具。
安装zabbix的服务器,主要是3个关键部分,前端界面(前端运维操作),服务器和数据库,一般用docker创建一个环境,安装非常方便。安装完成后,服务器和数据库启动后,前端界面打开如下图所示。

从上图可以看出,这个系统有2级菜单,主要是5大功能模块,每个模块下还有很多二级功能菜单。由于该工具功能太强大,本次将介绍其中的一部分使用功能。
zabbix监控模式
Zabbix监控分为多个模式,常见的有2种。
一种是zabbix服务器主动发起监控,比如查看某个主机的端口是否存活,这种模式比较局限,使用范围比较窄,只能监控一部分数据,比如某个主机的进程是否存活,这个模式监控不了,但这个模式非常简单。
另外一种是zabbix客户端(agent)模式,这个模式非常强大,能监控到主机的任何信息,比如内存,硬盘,cpu,进程,服务等,能监控这么多数据也是有前提的,需要在被监控的目标服务器上安装zabbix agent客户端工具,这个工具可以主动或被动的上报收集的数据。
本文目的是为了简单监控服务,不需要监控那么多数据,所以采用第一种模式。
监控服务端口步骤
1
创建主机
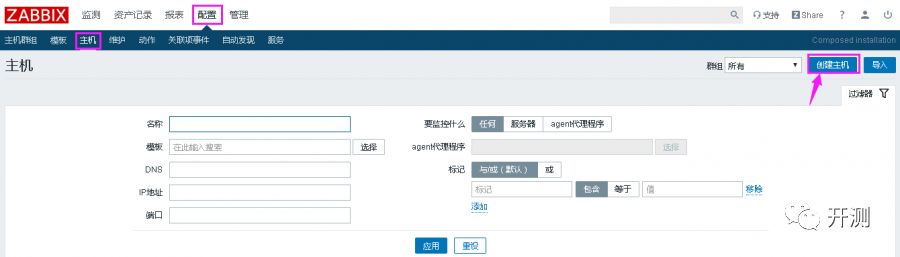

2
建监控项
创建完成之后,点击进入该主机,创建监控项,主要监控该主机的9998端口。


注意,这里选的类型是简单检查,而不是zabbix agent模式。几个重要的参数已圈出来,比如键值,是为了监控该主机的9998端口。其他的参数按照实际业务填写吧,比如更新间隔,这里默认是30s,可以适当修改。
3
根据以上监控项新建触发器

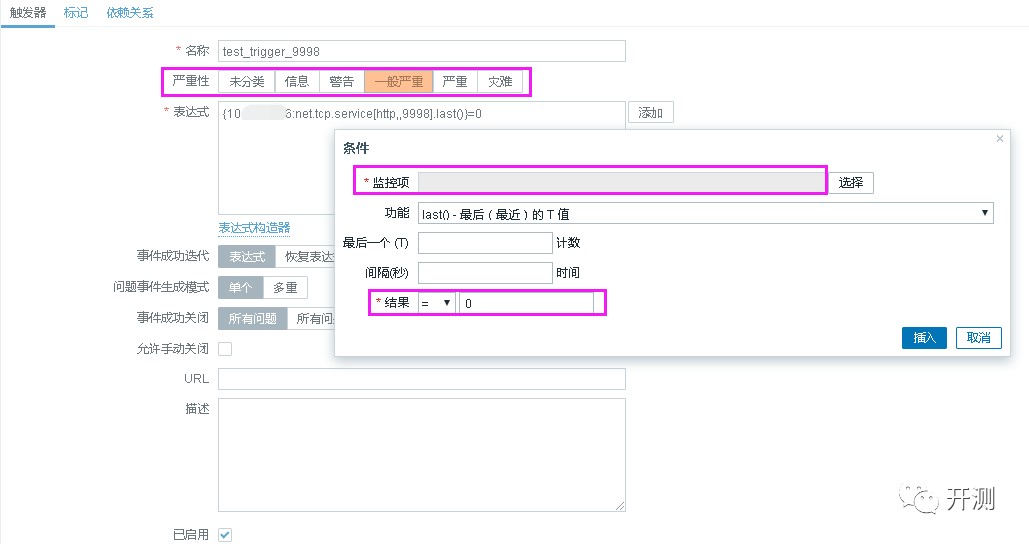
添加[表达式]时,会有如上弹窗,选择对应的监控项,一般监控服务返回为1,只有当返回为0时,触发警报。
4
触发问题展示
那触发的警报一般会显示在什么位置呢,警报展示在顶级菜单监控下面的问题菜单中。
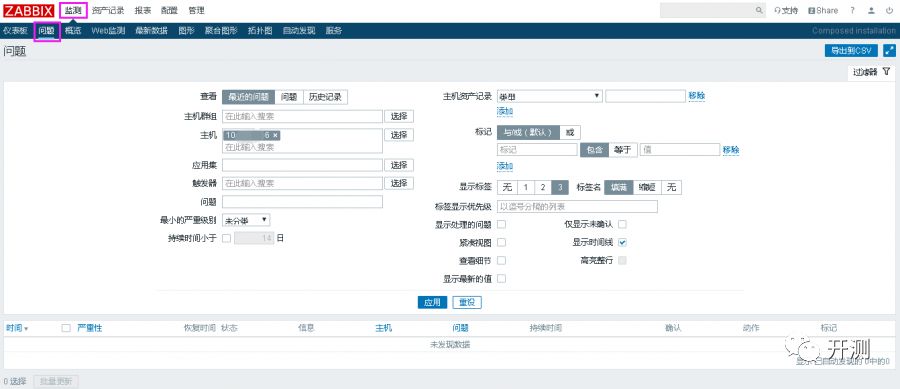
5
创建图形
接着,根据监控项创建图形。

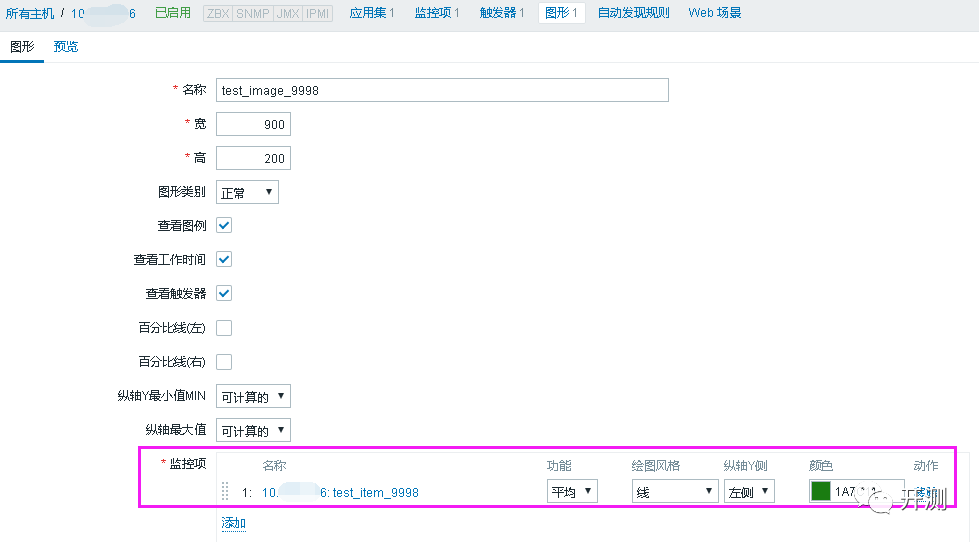
6
图形展示
创建图形,是为了更形象的观察结果。一般图像展示在顶级菜单监控项下面的图形菜单中。

此外,grafana支持zabbix的数据源,可以根据创建的图形,在grafana上进行展示汇总,关于grafana可以参考之前的介绍。
以上是监控服务端口的全部介绍,注意上述操纵均是Admin账号配置。配置完成后,可以通过顶级菜单监测项中的问题和图形(同时可以借助grafana)实时查看结果。但还是存在一个问题,服务也不知道什么时候挂掉,总不能老是盯着监测结果。
邮件通知配置
一旦出现问题,能够智能邮件通知的功能也是可以配置。
1
配置邮件服务
需要邮件通知,首先需要配置邮件服务。


上图是配置了邮件服务,这个前提是有邮件服务,如果没有,请先搭建一个邮件服务(具体搭建步骤不赘述了,网上很多资料)。
2
创建用户
创建接收邮件的用户。


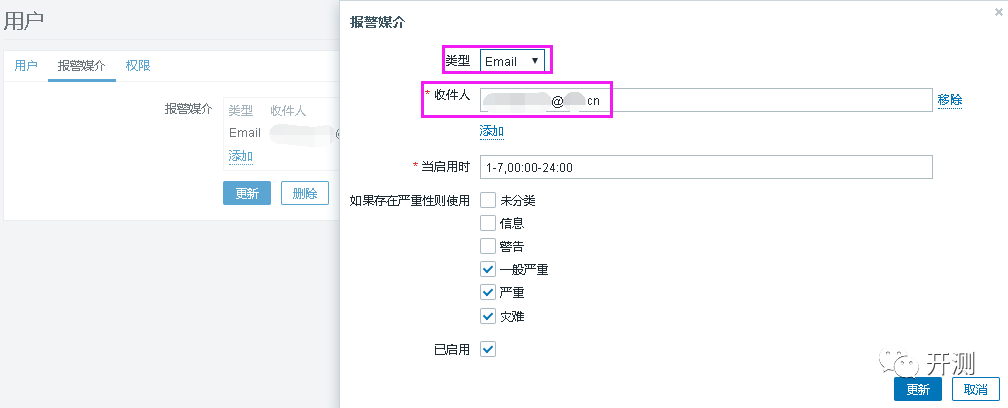
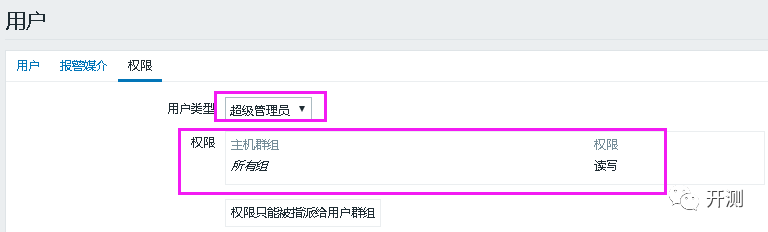
创建用户的时候,有一个地方需要特别注意,就是用户权限,如果没有主机的读权限,是接收不到任何邮件的(这是一个大坑)。有2种方法,第一是用户类型选择超级管理员,那么对所有主机群组都有读写权限。第二是创建一个用户群组,有该主机所在主机群组的读权限,然后将用户加入到这个群组,也能收到邮件。
3
创建动作
创建报警动作。

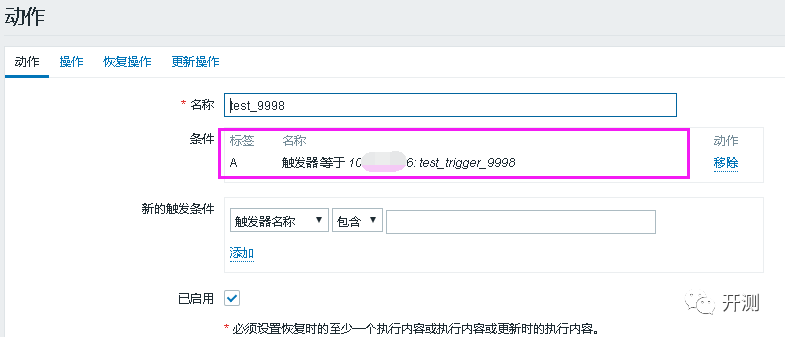

注意,这里也有个小坑,操作是和动作挂钩的,但后面的恢复操作和更新操作是对用户群组整个生效的,只要拥有群组的读权限,就能收到对应的邮件,如果开启,用户群组也没有设计好,会收到大量的无关邮件。反之,如果用户群组设计好了,后面2个操作报警也有很大的帮助。
总结
本文就介绍到这里,简单总结一下,主要是借助zabbix运维工具简单检查服务端口是否正常,达到预警和提示的目的。

