点击上方蓝字关注我们!
背景
图片类任务经常使用卷积神经网络,网络结构中经常是使用全链接作为输出层,来实现分类或者回归。
全链接层的好处:由于其参数量级大,模型的拟合能力更强
坏处
① 对于数据的尺寸要求是固定的,因此我们有时需要resize图片,导致变形或者剪切损失图片信息
② 模型的参数基本都集中于全链接层,因此预测时间主要被全链接占用,实时性要求高的模型会有影响
③ 显存占用高
因此当我们关注实时性,可以适当牺牲准确性(卷积层复杂可以弥补准确性),并且输入数据尺寸是变化的时候,我们应该怎么做呢?
![]()
方法
1.去掉全链接层,使用全卷积神经网络,1*1卷积层控制输出尺寸
2.靠近输出层的卷积层整体maxpooling,1*1卷积层控制输出尺寸
代码
我们以mnist作为例子:
**全链接模型:**通过d2控制输出的tensor是1*10
class DENSE_MNIST_MODEL(tf.keras.Model):
def __init__(self):
super(DENSE_MNIST_MODEL, self).__init__()
self.conv1 = Conv2D(32, 3, activation='relu')
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
模型参数:
Model: "dense_mnist_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 320
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dense (Dense) multiple 2769024
_________________________________________________________________
dense_1 (Dense) multiple 1290
=================================================================
Total params: 2,770,634
Trainable params: 2,770,634
Non-trainable params: 0
输入图片是2828,经过两个maxpooling,步长是2,变成了77大小,经过77卷积,padding=valid,则只保留了channel上的特征。再经过11卷积,控制channel为10
class FCN_MNIST_MODEL(tf.keras.Model):
def __init__(self):
super(FCN_MNIST_MODEL, self).__init__()
self.conv1 = Conv2D(16, 3, 1, padding="same")
self.conv2 = Conv2D(32, 3, 1, padding="same")
self.conv3 = Conv2D(32, 7, 1, padding="valid")
self.conv4 = Conv2D(10, 1, 1, padding="same")
self.maxpool2d = MaxPool2D(2, 2, padding="valid")
def call(self, inputs=(None, 28, 28, 1)):
__output = self.conv1(inputs)
__output = self.maxpool2d(__output)
__output = self.conv2(__output)
__output = self.maxpool2d(__output)
__output = self.conv3(__output)
__output = self.conv4(__output)
shape = __output.shape
__output = tf.squeeze(__output, axis=[1,2])
return tf.nn.softmax(__output)
模型参数:
Model: "fcn_mnist_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 160
_________________________________________________________________
conv2d_1 (Conv2D) multiple 4640
_________________________________________________________________
conv2d_2 (Conv2D) multiple 50208
_________________________________________________________________
conv2d_3 (Conv2D) multiple 330
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
=================================================================
Total params: 55,338
Trainable params: 55,338
Non-trainable params: 0
通过卷积、maxpooling、avgpooling将过程中的tensor变成11channel尺寸,再通过1*1卷积,控制channel为10。
注意同一个batch里的数据需要是同样的尺寸,我们都会进行pad,所以常用做法是将尺度相近的图片放到同一个batch里,padding后变成同一个尺寸。
class ARBITRARY_MNIST_MODEL(tf.keras.Model):
def __init__(self):
super(ARBITRARY_MNIST_MODEL, self).__init__()
self.conv1 = Conv2D(16, 3, 1, padding="same")
self.conv2 = Conv2D(32, 3, 1, padding="same")
self.conv3 = Conv2D(10, 1, 1, padding="same")
def call(self, inputs):
__output = self.conv1(inputs)
__output = self.conv2(__output)
__output = tf.nn.max_pool2d(__output, __output.shape[1:3], 1, padding="VALID") # 这里也可以使用GlobalMaxPooling2D,再经过expand_dims变成四维
__output = self.conv3(__output)
__output = tf.squeeze(__output, axis=[1,2])
return tf.nn.softmax(__output)
模型参数:
Model: "arbitrary_mnist_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 160
_________________________________________________________________
conv2d_1 (Conv2D) multiple 4640
_________________________________________________________________
conv2d_2 (Conv2D) multiple 330
=================================================================
Total params: 5,130
Trainable params: 5,130
Non-trainable params: 0
数据对比
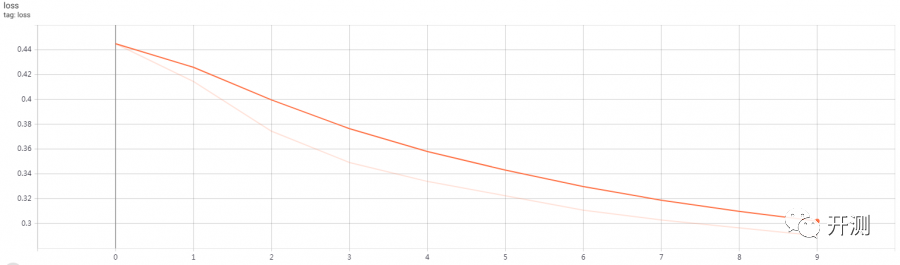
全链接模型(浅色的线是原始数据,深色的是平滑后的数据,周期只有10)
损失值尾部上扬,与周期短和没有添加正则化方法有关,正则化不在本文讨论范围内。
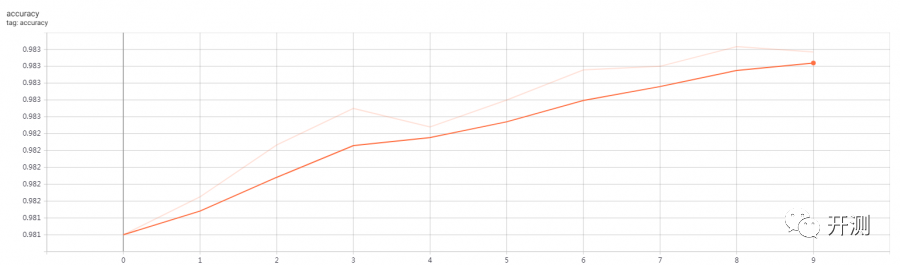
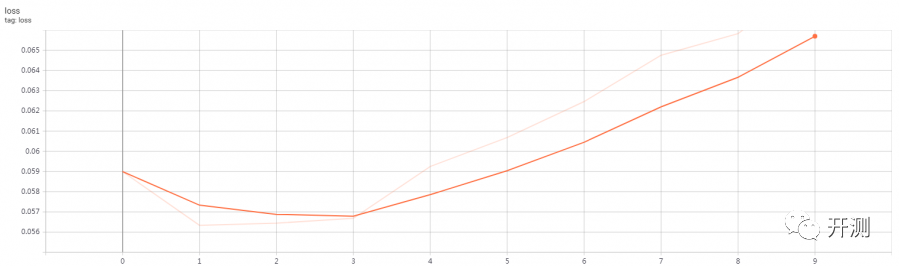
全卷积模型:
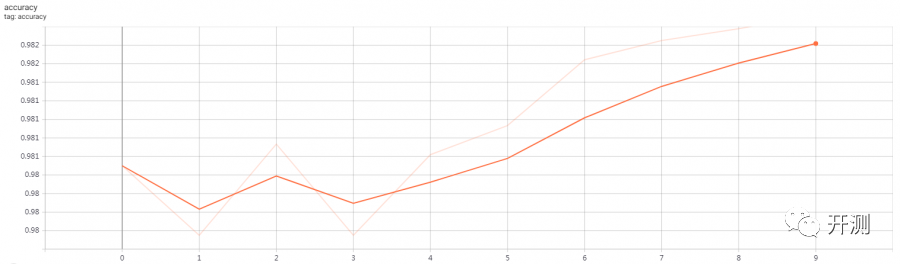
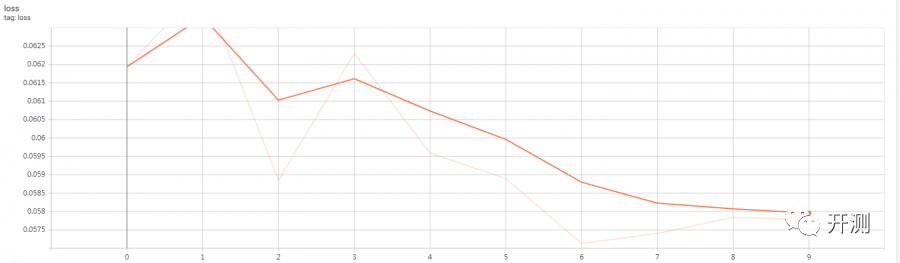
可变尺寸模型:
10个周期不够,准确度和损失还没有收敛,但是能大致看出趋势。
模型参数量AccuracyLoss|------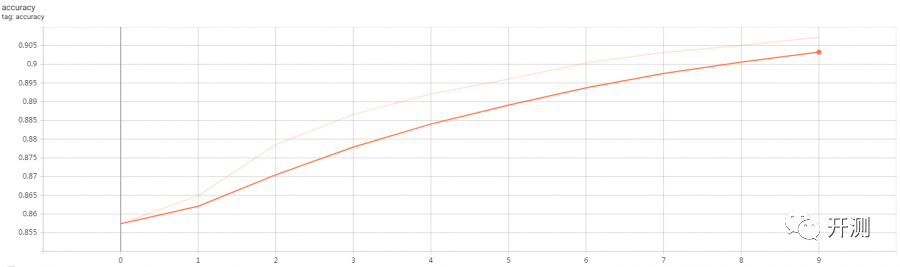

总结
落地部署中,我们不仅关注准确度,可能更关心响应时间,因此模型不能太复杂,全卷积是一个很好的思路。
如果我们的数据,包括图片、文本、音频等,如果尺寸变化幅度比较大,是否可以考虑将样本尺寸相近的数据放到同一个batch,网络中不使用全链接,实现动态尺度模型。


来呀!来呀!关注我吧!!
