点击上方蓝字关注我们!
Tornado 是一个Python web框架和异步网络库,起初由 FriendFeed 开发。通过使用非阻塞网络I/O,Tornado可以支撑上万级的连接,处理长连接, WebSockets , 和其他需要与每个用户保持长久连接的应用。
本文介绍如何正确的使用 Tornado 异步特性以及对其进行压力测试, 查看Tornado的性能到底有多强悍。
本文使用Tornado 5.0.2版本
最简单的脚手架
# -*- coding: utf-8 -*-
import tornado.ioloop
import tornado.web
class Index(tornado.web.RequestHandler):
def get(self):
self.write("hello world")
def make_app():
return tornado.web.Application([
(r"/", Index)
])
if __name__ == '__main__':
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
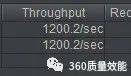
我使用jmeter 进行压测,可以达到 1200,可以说是非常不错
同步的困扰
但是在开发过程中并不是所有的接口都什么都不做就返回个简单的字符串或者json, 更多的时候是进行一些数据库的操作或者本地的IO操作之后再返回相应的数据。
class Index(tornado.web.RequestHandler):
def get(self):
name = self.get_argument('name', 'get')
time.sleep(0.5)
self.write("hello {}".format(name))
我们在 get 请求的时候加入了 time.sleep(0.5) 来模拟接口处理数据的耗时操作。
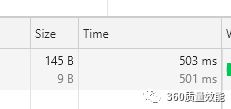
我们在chrome的开发者工具中看到这个请求耗时503ms,

为什么同步的性能会这么差?
在python中 time.sleep() 函数是个阻塞函数, 会阻塞python的运行, 使用tornado做web项目,你不可能只为一个用户服务,当有多个用户访问同一个接口时,python在处理sleep操作时会阻塞运行,这时后来的请求也要等待前的请求,只有当前面的请求结束以后再处理,这也就是为什么上面的压测最短是503ms,最长却需要50240ms的原因.因为大家是阻塞进行的。不光time.sleep是这样的阻塞函数, python中绝大多数函数都是这样的阻塞函数,包括文件IO操作, 网络请求操作等都是阻塞函数,所以我们需要异步的处理网络请求。
异步的解决方案
01
使用多线程
class Index(tornado.web.RequestHandler):
def get(self):
name = self.get_argument('name', 'get')
t = threading.Thread(target=time.sleep, args=(0.5,))
t.start()
self.write("hello {}".format(name))
02
使用线程池来执行耗时操作
from tornado.concurrent import run_on_executor
class Index(tornado.web.RequestHandler):
executor = ThreadPoolExecutor(1)
@tornado.web.asynchronous
@tornado.gen.coroutine
def get(self):
name = self.get_argument('name', 'get')
rst = yield self.work(name)
self.write("hello {}".format(rst))
self.finish()
def post(self):
name = self.get_argument('name', 'post')
self.write("hello {}".format(name))
@run_on_executor
def work(self, name):
time.sleep(0.5)
return "{} world".format(name)
这里在Index类中初始化了一个线程池, executor, 这有一个线程, 将耗时的操作放到work函数中, 并且使用 @run_on_executor 装饰器进行装饰, 这时我们就可以获取到耗时操作的返回值。
压测为500个用户在5秒内请求
但是我们看下压测结果
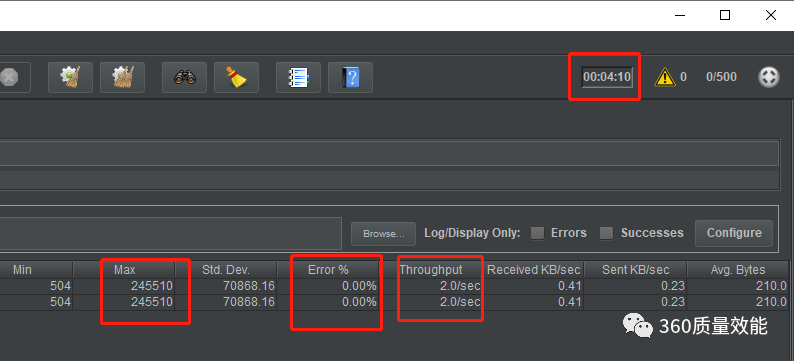
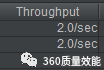
依然很糟糕, 每秒也就能处理2个请求。而且最长的请求需要7万多ms, 这也是无法忍受的。
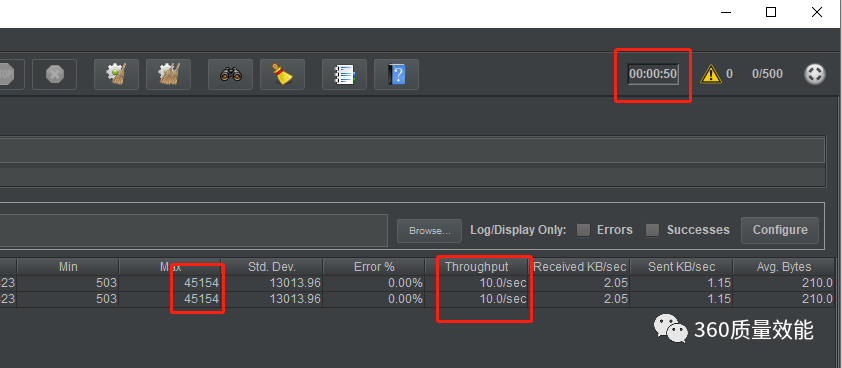
每个请求需要耗时0.5秒,现在有一个线程池,它里面有一个线程,也就是说,同时最多也就处理一个请求,我们可以加大线程线中的数量, executor = ThreadPoolExecutor(5) 改为5个再进行压测,这时看到是有所增长,可以到达10, 也依然不是很理想, 最大影响有4万多ms。
意义在于, 一个web项目, 不太可能只提供一个接口, 假设你有3个接口, /user, /info, /case , 其中两个接口( /user, /case )都使用异步处理,放到了线程池中操作, 只有一个接口( /info )没有,而是直接使用
很显然, 即使用到的线程池,并且将线程池中的线程设置为5, 每秒也只能处理10个请求,这样的QPS也是令人相当着急,一个成熟的系统访问人数成千上万都很正常,接下来我们使用asyncio库来异步处理请求。
使用异步处理库asyncio
import asyncio
class Index(tornado.web.RequestHandler):
async def get(self):
name = self.get_argument('name', 'get')
rst = await self.work(name)
self.write("hello {}".format(rst))
self.finish()
def post(self):
name = self.get_argument('name', 'post')
self.write("hello {}".format(name))
async def work(self, name):
await asyncio.sleep(0.5)
return "{} world".format(name)
if __name__ == '__main__':
try:
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
except:
print(traceback.format_exc())
tornado.ioloop.IOLoop.current().start()
这里我们将time.sleep函数换成了 asyncio.sleep 异步的函数, 并且在函数定义def 将加上async , 在获取work结果时使用了await 关键词。
此时的压测结果为
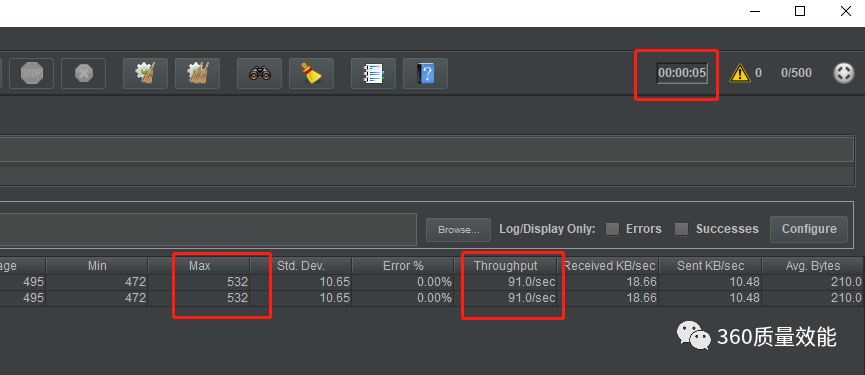
可以看到,在5秒内就全部执行结束,QPS可以达到91, 和之前的10或者2有着非常大的提高,由于只有500个用户, 我们可以模拟更多的用户来访问,使用1000个用户来进行压测看下效果。
依然是在5秒内完成了请求,并且QPS上升到了181, 继续加大请求用户量为2000。
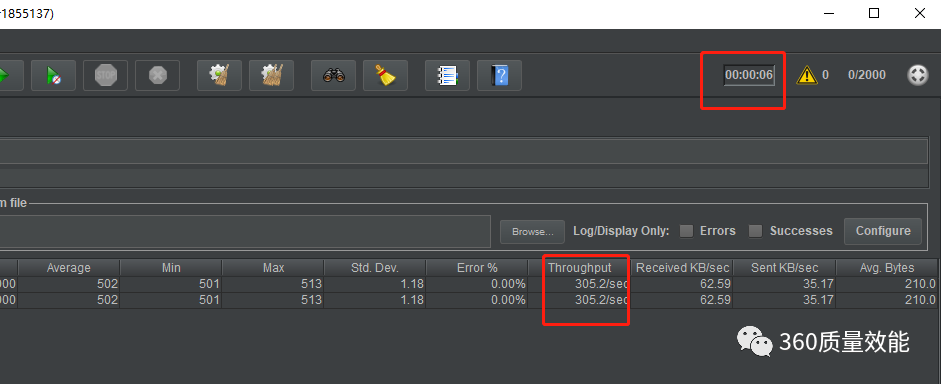
依然强悍, QPS继续上升到305,而且仅多用了1秒钟.如果再继续提高用户量,我们来看看它的极限在哪里?

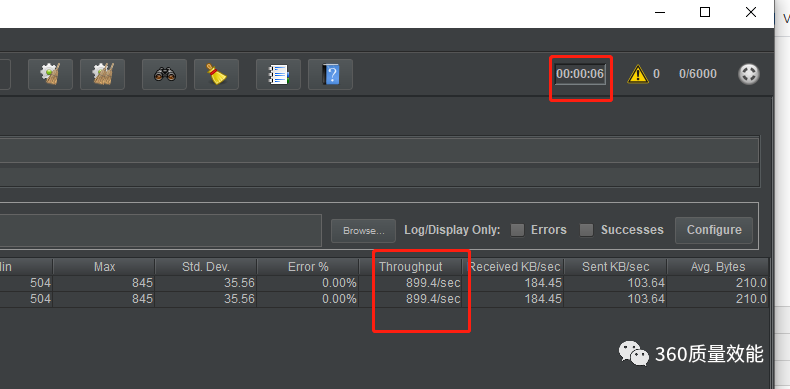
4000的时候,服务端会报 ValueError: too many file descriptors in select() 这个是由于在windows中IOloop使用的是selector, 它有1024个文件描述符的限制所导致的, 将其放到linux中我们看看可以达到多少。
6000的时候还没有问题,如果7000的话会出现异常,这时已经比在多线程中运行性能提高的非常多了,如果考虑用户的增加,就应该考虑水平扩展了,通过负载均衡来解决了。
总结
通过上文的对比,我们可以理解,不是因为你使用了tornado 你的网站性能就能提升多少,而是要正确的使用相应的异步库,只有正确的使用异步特性,才能发挥tornado的高性能。
功能同步库异步库|------github 上有个组织在维护一些常用的异步库,https://github.com/aio-libs 常用的库都实现的异步, 大家在使用时可以先搜索一下
