点击上方蓝字关注我们!
什么是kafka
Apache Kafka是Apache软件基金会的开源的流处理平台,该平台提供了消息的订阅与发布的消息队列,一般用作系统间解耦、异步通信、削峰填谷等作用。同时Kafka又提供了Kafka streaming插件包实现了实时在线流处理。相比较一些专业的流处理框架不同,Kafka Streaming计算是运行在应用端,具有简单、入门要求低、部署方便等优点。
kafka的架构
Kafka集群以Topic形式负责分类集群中的Record,每一个Record属于一个Topic。每个Topic底层都会对应一组分区的日志用于持久化Topic中的Record。同时在Kafka集群中,Topic的每一个日志的分区都一定会有1个Borker担当该分区的Leader,其他的Broker担当该分区的follower,Leader负责分区数据的读写操作,follower负责同步改分区的数据。这样如果分区的Leader宕机,该分区的其他follower会选取出新的leader继续负责该分区数据的读写。其中集群的中Leader的监控和Topic的部分元数据是存储在Zookeeper中。
kafka的API
- topic的创建
[root@node01 bin]# kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--create
--topic test
--partitions 3
--replication-factor 3
- 查看topic的列表
[root@node01 bin]# kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--list
- 查看一个topic的详细信息
[root@node01 bin]# ./bin/kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--describe
--topic test
- 修改topic
[root@node01 kafka_2.11-2.2.0]# ./bin/kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--alter
--topic test
--partitions 2
- 删除topic
[root@node01 bin]# kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--delete
--topic test
- producer往一个topic中生产消息
[root@node01 bin]# kafka-console-producer.sh
--broker-list node01:9092,node01:9092,node01:9092
--topic test
- consumer订阅一个topic消费消息
[root@node01 bin]# kafka-console-consumer.sh
--bootstrap-server node01:9092,node01:9092,node01:9092
--topic test
--group opentest
- 查看消费组信息
[root@node01 bin]# kafka-console-consumer.sh
--bootstrap-server node01:9092,node01:9092,node01:9092
--list
- 查看某一消费组的详细信息
[root@node01 bin]# kafka-console-consumer.sh
--bootstrap-server node01:9092,node01:9092,node01:9092
--describe
--group opentest
kafka在程序中的使用
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.1.0</version>
</dependency>
- 生产者的代码
@Test
public void producer() throws ExecutionException, InterruptedException {
String topic = "items";
Properties p = new Properties();
p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node02:9092,node03:9092,node01:9092");
p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.ACKS_CONFIG, "-1");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(p);
while(true){
for (int i = 0; i < 3; i++) {
for (int j = 0; j <3; j++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "item"+j,"val" + i);
Future<RecordMetadata> send = producer
.send(record);
RecordMetadata rm = send.get();
int partition = rm.partition();
long offset = rm.offset();
System.out.println("key: "+ record.key()+" val: "+record.value()+" partition: "+partition + " offset: "+offset);
}
}
}
}
- 消费者代码
@Test
public void consumer(){
Properties p = new Properties();
p.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node02:9092,node03:9092,node01:9092");
p.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
p.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
p.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"opentest");
p.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");//
p.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");//自动提交
// p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");//默认5秒
// p.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,""); //拉取数据的配置
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(p);
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(0));//
if(!records.isEmpty()){
Iterator<ConsumerRecord<String, String>> iter = records.iterator();
while(iter.hasNext()){
ConsumerRecord<String, String> record = iter.next();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
System.out.println("key: "+ record.key()+" val: "+ record.value()+ " partition: "+partition + " offset: "+ offset);
}
}
}
}
kafka的原理深入
1. kafka的AKF
2. kafka数据如何保证顺序消费
3. kafka中consumer的分组
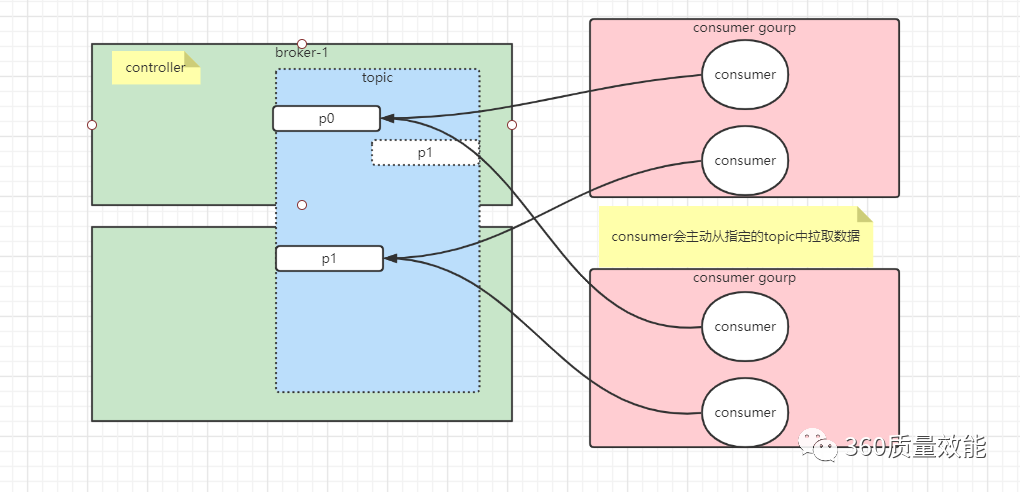
4.消息队列,常见保证消息顺序性消费的两种方案
①. 生产时保证消息的有序性,单线程消费
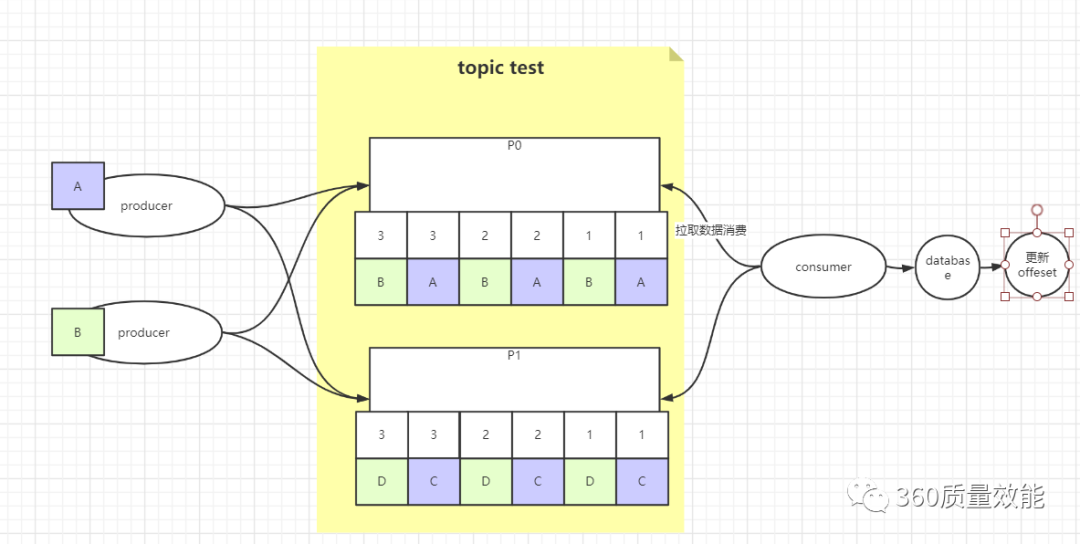
多线程生产消息,后面单线程消费数据,可以消费一条数据,就更新kafka偏移量offset的值,这种方式可以保证消息消费的进度,以及准确地更细offset的值,但是单线程的消费会对数据库以及offset进行频繁的更新,成本有点高,并且存在cpu以及网卡的资源浪费。
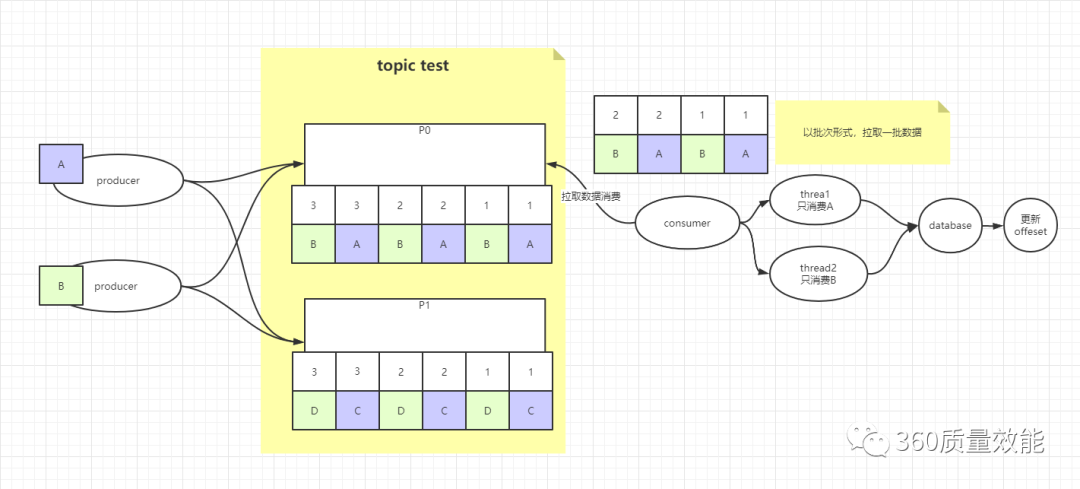
②. 多线程消费
5.kafka的消息生产的确认机制-- ack确认机制
Kafka生产者在发送完一个的消息之后,要求Broker在规定的时间内Ack应答,如果没有在规定时间内应答,Kafka生产者会尝试重新发送消息。默认acks=1。
①. acks=1 - Leader会将Record写到其本地日志中,但会在不等待所有Follower的完全确认的情况下做出响应。在这种情况下,如果Leader在确认记录后立即失败,但在Follower复制记录之前失败,则记录将丢失。
②. acks=0 - 生产者根本不会等待服务器的任何确认。该记录将立即添加到套接字缓冲区中并视为已发送。在这种情况下,不能保证服务器已收到记录。
③. acks=all /-1 - 这意味着Leader将等待全套同步副本确认记录。这保证了只要至少一个同步副本仍处于活动状态,记录就不会丢失。这是最有力的保证。这等效于acks = -1设置。
6.kafka的ISR、OSR以及AR
**ISR:**in-sync-replica set 同步副本设置。为了解决数据同步高延迟问题以及leader重新选举时不会影响数据同步。
7.kafka中的索引
kafka中索引文件有两个,分别是offset的索引文件以及timeindex的索引文件,文件初始化时,都是10M大小。offset索引文件中会记录offset的值,以及文件中的position。以position取读取log文件中的一批数据。timeindex索引会记录一个时间戳,以及对应的offset,所以需要重新去offset的索引文件中找到offset对应的log文件的position,再去读取数据。
kafka中常见的优化参数
1. broker的配置
2. producer的配置

3. consumer的配置

总结
kafka作为主流的消息中间件,主要原因是其有如下优势:
解耦
Kafka具备消息系统的优点,只要生产者和消费者数据两端遵循接口约束,就可以自行扩展或修改数据处理的业务过程。
高吞吐量、低延迟
即使在非常廉价的机器上,Kafka也能做到每秒处理几十万条消息,而它的延迟最低只有几毫秒。
持久性
Kafka可以将消息直接持久化在普通磁盘上,且磁盘读写性能优异。
扩展性
Kafka集群支持热扩展,Kaka集群启动运行后,用户可以直接向集群添加。
容错性
Kafka会将数据备份到多台服务器节点中,即使Kafka集群中的某一台Kafka服务节点宕机,也不会影响整个系统的功能。
支持多种客户端语言
Kafka支持Java、.NET、PHP、Python等多种语言。
参考文献
kafka英文官方网站:
http://kafka.apache.org/documentation/
kafka中文官方网站:
