点击蓝字关注我们
背景
随着数字技术的发展,我们的生活越来越离不开音频,对音频使用和呈现方式也越来越多样化,人们也从去单纯的听录制好的音频转向录制属于自己的音频,例如录歌、会议录音、录制短视频等。我们这些音频是高质量,清晰可听的,而这依赖于设备的性能。因此,对于一个音频设备,其音频质量的好坏成为衡量该设备性能的一个重要指标。然而,在现实生活中,录制的音频中不仅会有设备本身的电流噪声,还会夹杂着周围环境中的噪声。而环境噪声并不与设备性能直接相关,一旦所录制的音频中有环境噪声的干扰就会使得音频质量变差,使得我们不能正确的对该音频设备的性能进行评估。所以,如何有效的消除环境噪声是一个值得被关注的问题。环境中噪声往往是复杂多变难以处理的,利用传统降噪方法也很难取得理想的效果。为了解决这一问题,本文将介绍一种基于模型来自动消除音频中的环境噪声的方法。该方法不仅可以用于提高音频质量检测的准确性,还适用于各种需要提高音频质量的场景中。
核心技术与架构图
将音频设备录制的音频信号经过短时傅里叶变换(STFT)得到频谱和相位,将频谱直接发送至可训练好的可预测出噪声频谱的噪声预测模型中,提取出音频中的噪声,然后将音频频谱减去预测出的噪声频谱,通过傅里叶逆变换就能得到降噪后的语音了,最后将降噪后的音频用于音频设备的音频质量检测。
整体方案主要分为五个部分
1
收集纯净的人声作为干净的音频信号,收集环境噪声和设备噪声作为噪声信号;
2
对数据集进行预处理,具体做法是将纯净信号和噪声信号按照一定的频率进行采样形成多个等长的新的纯净信号和噪声信号。将纯净信号和噪声信号随机缩放后进行混合,保证混合音频的多样性。对各种音频信号进行傅里叶变换得到最终的输入频谱;
3
训练噪声预测模型,通过网络训练出可以预测出噪声的噪声预测模型;
4
音频降噪,将带有噪声的音频输入噪声预测模型,预测出该音频中的噪声,用带噪音频的频谱减去预测出的噪声频谱,再与带噪音频的相位结合进行傅里叶逆变换,从而得到了降噪后的音频;
5
将去除噪声后的音频用于音频质量检测。
技术优势
01
通过模型的方式提取出噪声,可以有针对性的消除固定类型的噪声。针对那些传统的音频降噪的方式不能解决的噪声,该方法也能取得不错的降噪效果;
02
该方法操作简单,降噪速度相对较快,效果较好;
03
以频谱图作为输入,可通过图像特征提取的方式就能实现音频特征的提取。
核心技术实现
01
网络模型
这里的特征提取网络可以使用ResNet,U-Net, LSTM等做为基础的特征提取网络,这些网络都可以达到不错的效果,可根据自己的数据特性选取适合的网络作为噪声预测模型的基础网络。训练过程中,得到一个特征图谱(掩码)f(S;θ),输入为频谱图S,目标为噪声频谱N,其损失函数的定义为:
L(S,N;θ) = 1/2||f(S;θ)⨀S-N ||²
02
数据预处理
收集一定时长的纯净音频,环境噪声音频,将收集到的纯净音频和噪声音频进行混合,形成混合音频。大多数时候收集到的音频的时长并不一致,可通过对音频信号进行采样,对时长进行统一。将等时长的纯净音频和噪声音频叠加混合后,得到带有噪声的音频用来作为训练数据。
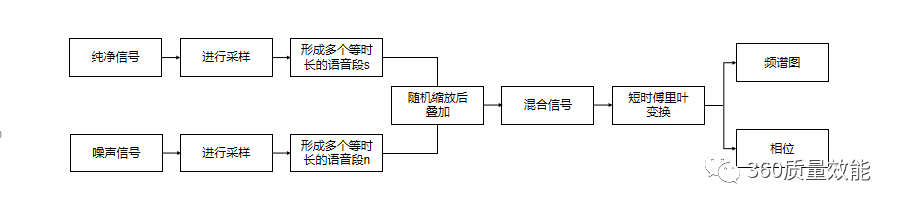
数据的切分
其中采样后得到的新的音频的时长t与采样频率f、采样点数n之间的关系为:
path = long_voice_path
files = os.listdir(path)
for file in files:
name = file.split('.')[0]
long_voice, sample_rate = librosa.load(path + files, sr=16000)
n = int(len(long_voice) / 80000)
for i in range(1, n):
short_voice = long_voice[(i-1)*80000: i*80000]
save_path = short_voice_path + name + '_' + str(i) + '.wav'
sf.write(save_path, short_voice, sample_rate)
音频的混合
files = os.listdir(clean_voice_path)
for i in range(0, 5):
clean_voice, clean_sr = librosa.load(clean_voice_path + files[i], sr=16000)
for j in range(1, 5):
path = noise_voice_path
noises = os.listdir(path)
noise = path + noises[j]
noise_voice, noise_sr = librosa.load(noise, sr=16000)
sum_s = np.sum( clean_voice ** 2)
sum_n = np.sum(noise_voice ** 2)
x = np.random.uniform(0.5, 3)
y = np.random.uniform(0.5, 3)
noise_voice = x * noise_voice
clean_voice = y * clean_voice
mixed_voice = clean_voice + noise_voice
sf.write(mixed_voice_path + files[i].split('.')[0] + '.wav', target, 16000)
时域到频域的变换
dim_square_spec = int(n_fft / 2) + 1
m_amp_db_voice, m_pha_voice = numpy_audio_to_matrix_spectrogram(
clean_voice, dim_square_spec, n_fft, hop_length_fft)
m_amp_db_noise, m_pha_noise = numpy_audio_to_matrix_spectrogram(
noise_voice, dim_square_spec, n_fft, hop_length_fft)
m_amp_db_mixed_voice, m_pha_mixed_voice = numpy_audio_to_matrix_spectrogram(
mixed_voice, dim_square_spec, n_fft, hop_length_fft)
03
训练噪声模型
def training(weights_path, training_from_scratch, epochs, batch_size):
voice_in = np.load(mixed_voice_spectrogram_path)
voice_ou = np.load(clean_voice_spectrogram_path)
voice_ou = voice_in - voice_ou
voice_in = scaled_in(voice_in)
voice_ou = scaled_ou(voice_ou)
voice_in = voice_in[:,:,:]
voice_in = voice_in.reshape(voice_in.shape[0],voice_in.shape[1],voice_in.shape[2],1)
voice_ou =voice_ou[:,:,:]
voice_ou = voice_ou.reshape(voice_ou.shape[0],voice_ou.shape[1],voice_ou.shape[2],1)
voice_train, voice_test, label_train, label_test = train_test_split(voice_in, voice_ou, test_size=0.20, random_state=42)
if training_from_scratch:
model = model()
else:
model = model(pretrained_weights=None)
checkpoint = ModelCheckpoint(weights_path+'/model_best.h5', verbose=1, monitor='val_loss', save_best_only=True, mode='auto')
generator_nn.summary()
history = model.fit(voice_train, label_train, epochs=epochs, batch_size=batch_size, shuffle=True, callbacks=[checkpoint], verbose=1, validation_data=(voice_test, label_test))
04
音频去噪
def prediction(weights_path, name_model, audio_dir_prediction, dir_save_prediction, audio_input_prediction,
audio_output_prediction, sample_rate, min_duration, frame_length, hop_length_frame, n_fft, hop_length_fft):
json_file = open(weights_path+'/'+name_model+'.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
loaded_model.load_weights(weights_path+'/'+name_model+'.h5')
audio = audio_files_to_numpy(audio_dir_prediction, audio_input_prediction, sample_rate,frame_length, hop_length_frame, min_duration)
dim_square_spec = int(n_fft / 2) + 1
m_amp_db_audio, m_pha_audio = numpy_audio_to_matrix_spectrogram(
audio, dim_square_spec, n_fft, hop_length_fft)
X_in = scaled_in(m_amp_db_audio)
X_in = X_in.reshape(X_in.shape[0],X_in.shape[1],X_in.shape[2],1)
X_pred = loaded_model.predict(X_in)
inv_sca_X_pred = inv_scaled_ou(X_pred)
X_denoise = m_amp_db_audio - inv_sca_X_pred[:,:,:,0]
audio_denoise_recons = matrix_spectrogram_to_numpy_audio(X_denoise, m_pha_audio, frame_length, hop_length_fft)
nb_samples = audio_denoise_recons.shape[0]
denoise_long = audio_denoise_recons.reshape(1, nb_samples * frame_length)*10
sf.write(dir_save_prediction + audio_output_prediction, denoise_long[0, :], sample_rate)
效果展示
下图展示了一段在复杂环境中录制的音频信号和经过降噪后该音频的时域波形与频谱图,其中,第一行为原始音频的时域和频域表现,第二行和第三行分别为基于U-Net和LSTM作为基础网络的降噪模型降噪后的音频的时域与频域表现。
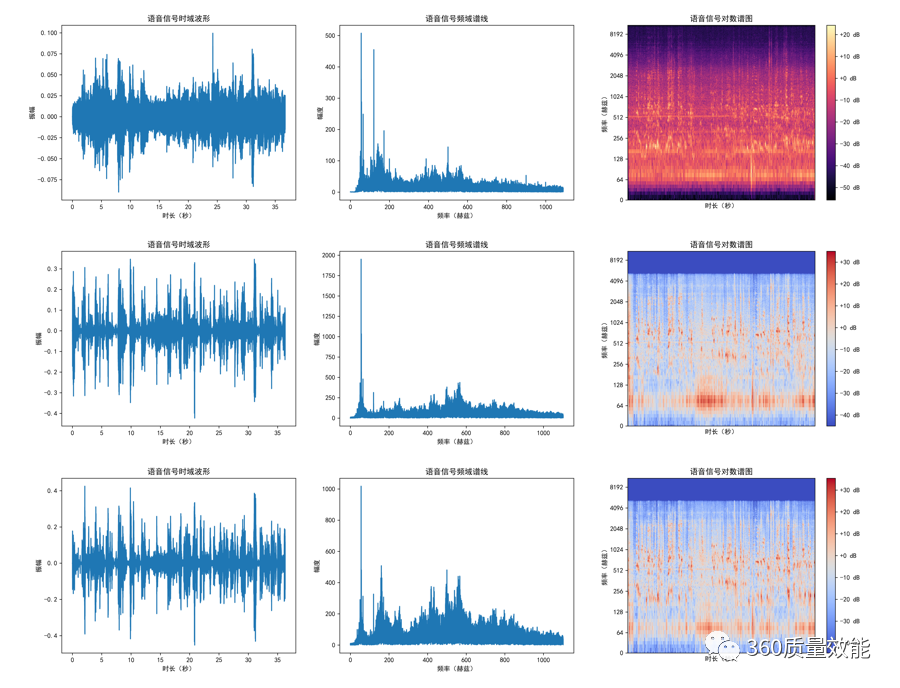
同时,用音频打分模型(分数越高越好)分别对它们进行打分,原始音频的分数为1.2分,经过基于U-Net的降噪模型降噪后的音频分数为4.1分,经过基于LSTM降噪模型降噪后的音频分数为3.8分。可以看出基于模型的方法能够有效的缓解环境噪声的干扰,提升音频的质量。如果大家在项目中遇到某种不可避免或难以去除的噪声时,不妨考虑使用这种方法!
