背景
开发过程经常会遇到接口响应慢的问题,用户也会反馈页面卡顿,响应太慢,导致用户体验差,这个时候作为开发就要赶紧排查了,可能是程序处理的问题、也可能是并发量大导致排队问题、也可能是sql查询性能导致等;大多数时候sql查询缓慢是主要原因,下面我们聊下排查sql慢的思路。
技术简介
说到sql就要先了解下sql的架构图:
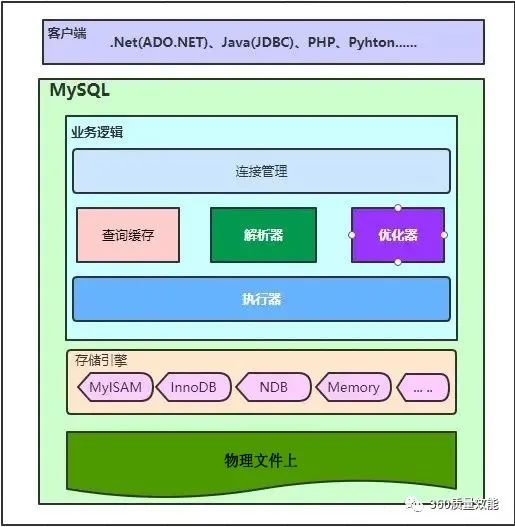
**客户端:**这里指连接MySQL各种形式,如.Net中使用的ADO连接、Java使用JDBC连接等,MySQL是客户端和服务器模式,前提先建立连接,才能传输数据,处理相关逻辑。
**业务逻辑:**在MySQL内部有很多模块组成,分别处理相关业务逻辑。
**连接管理:**负责连接认证、连接数判断、连接池处理等业务逻辑处理。
**查询缓存:**当一个SQL进来时,如果开启查询缓存功能,MySQL会优先去查询缓存,平时我们开发都会选择不开启。
**解析器:**对于一个sql语句,MySql根据语法规则需要对其进行解析,并生成一个内部能识别的解析树。
**优化器:**负责对解析器得到的解析树进行优化,MySQL会根据内部算法找到一个MySQL认为最优的执行计划,后续就按照这个执行计划执行。
**执行器:**得到执行计划之后,就会找到对应的存储引擎,根据执行计划给出的指令依次执行。
**存储引擎:**数据的存储和提取最后是靠存储引擎,平时我们使用最多的就是支持事务的InnoDb。
**物理文件:**数据存储的最终位置,即磁盘上,协同存储引擎对数据进行读写操作。
实现与效果
通过上面的逻辑我们知道一个sql发送到服务端时候要经过优化器,而使用explain关键字可以模拟优化器执行sql查询语句,从而知道MySQL是如何处理sql的即sql的执行计划。
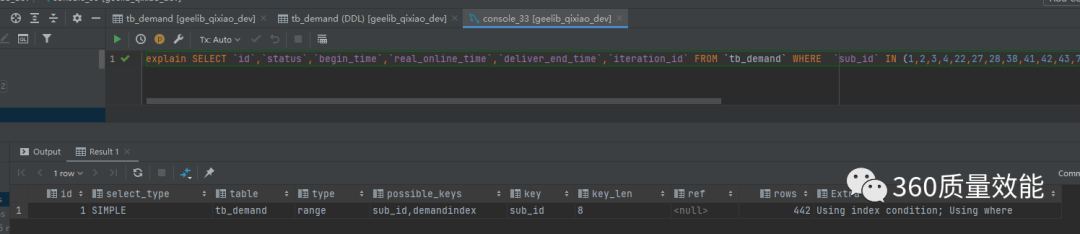
概要描述:
**id: **选择标识符
select_type: 表示查询的类型
table: 输出结果集的表
**partitions: **匹配的分区
type: 表示表的连接类型
**possible_keys: **表示查询时,可能使用的索引
key: 表示实际使用的索引
key_len: 索引字段的长度
**ref: **列与索引的比较
**rows: **扫描出的行数(估算的行数)
filtered: 按表条件过滤的行百分比
**Extra: **执行情况的描述和说明
这里面重点需要关注 type, key, Extra
Type
开发中比较常见的几个值,性能从好到坏
const->eq_ref->ref->range->index->all
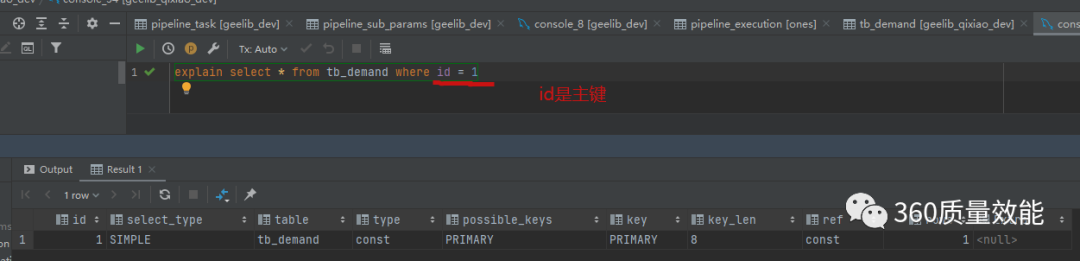
const:表示通过索引一次就找到数据,用于primary key或者unique索引,很快就能找到对应的数据,如图:
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常用于主键或唯一索引扫描。
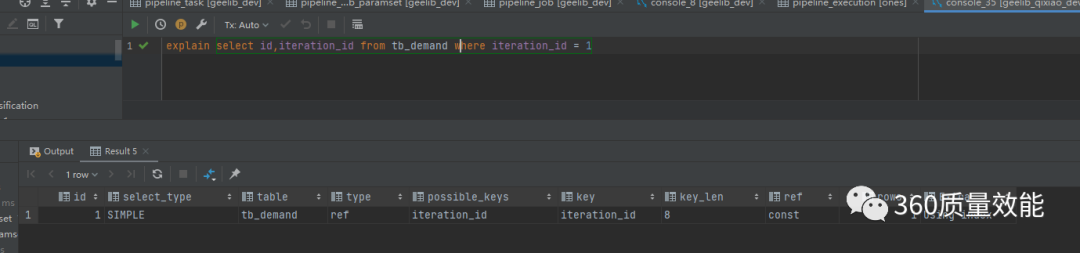
Ref:非唯一索引扫描,返回匹配的所有行。
两者区别匹配出多条结果时候用到的是否是唯一索引,如图:
range:使用一个索引检索指定范围的行,一般在where语句中会出现between、<、>、in等范围查询,如图:

index:全索引扫描,只遍历索引树,如图:
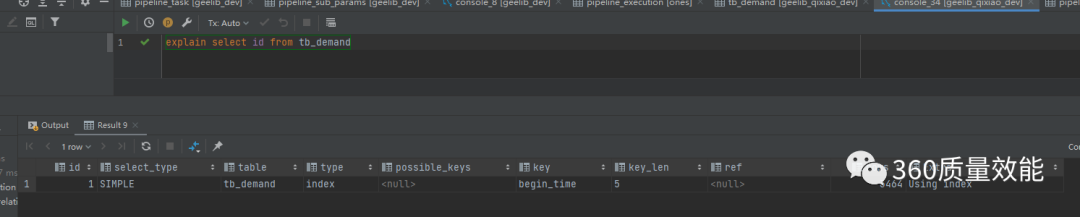
ALL:全表扫描,找到匹配行。与index比较,ALL需要扫描磁盘数据,index值需要遍历索引树,如图:

Key
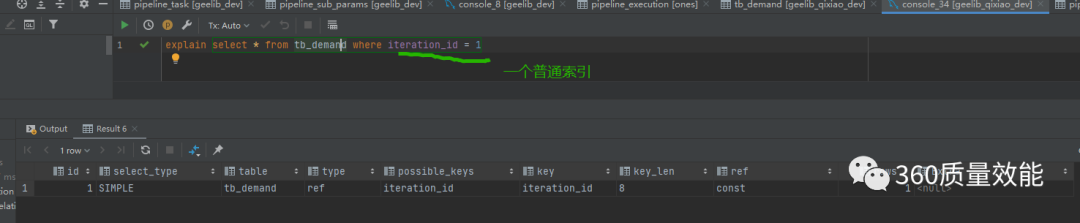
实际使用到的索引,如果为NULL代表没有使用到索引;这也是平时小伙伴判断是否用上索引的关键
Extra
一般常见会出现下面的信息:
Using index:表示查询语句中用到了覆盖索引,不访问表的数据行,查询效率比较好,如图:
如果用SELECT *进行查询,就不会有Using index。
Using filesort:代表MySQL会使用一个外部索引对数据进行排序(文件排序),而不是使用表内索引。这种情况在SQL查询需要避免,最好不要在Extra中出现此类型,如图:
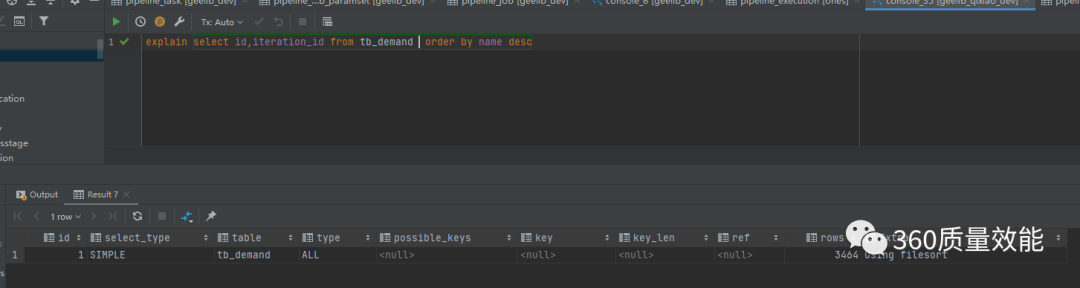
通常会是使用ORDER BY语句导致,上图中使用无索引的字段进行排序会出现。
Using temporary:产生临时表保存中间结果,这种SQL是不允许的,遇见数据量大的场景,就会特别慢,如图:

这种类型常常因为ORDER BY 和 GROUP BY导致,所以在进行数据排序和分组查询时,要注意是否加了索引以及索引是否生效。
《总结》
上面只是列出了一些重要的点,大家可以通过重要信息看出sql是否需要优化,从而定位问题。另外大家如果不好定位哪条sql比较慢的话,可以打开mysql的慢查询来定位到。
