selenium
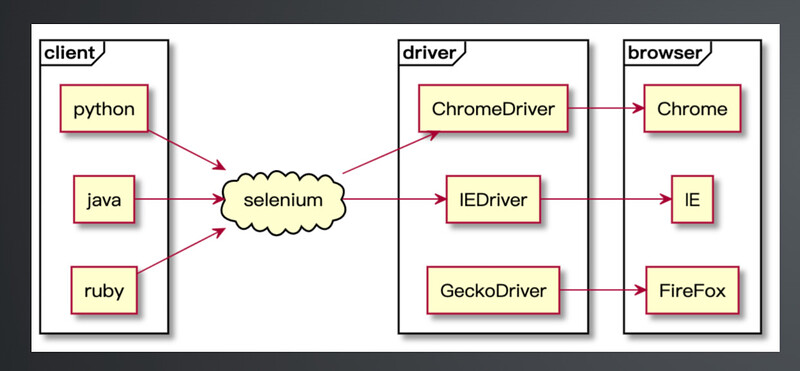
selenium的工作原理是什么?
selenium的三个工具是什么?
Webdriver,IDE,Grid
浏览器控制
get 打开浏览器
refresh 刷新页面
back 后退页面
maximize_window 最大化浏览器
minimize_window 最大化浏览器
元素定位常用方法
id,name,css,xpath
使用方法
from selenium.webdriver.common.by import By
find_element(By.id,‘idname’)
常用交互方法
点击 click()
输入 send_keys()
清空 clear()
获取元素属性信息
获取文本 element.text
获取元素属性(id,name,li,tb,class等等css属性)element.get_attribute(‘id’)
强制等待 time.sleep(‘1’)
隐式等待(轮询查找元素,driver实例化后使用,全局配置)driver.inplicitly_wait(3)
显示等待(findelement只是查找html元素,找到时,js和css还没加载好,会导致无法操作,此时可以使用显示等待)
WebDriverWait(driver实例,最长等待时间,轮询时间).until/until_not(expected_conditions.element_to_be_clickable(By,元素))
将element的文本内容小写 可以使用 element.text.lower()
显示等待高级使用
问题:WebDriverWait构造函数的poll_frequency=POLL_FREQUENCY是什么意思?
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
class TestWait:
def test_wait1(self):
self.driver = webdriver.Chrome()
self.driver.get("https://ceshiren.com/")
#确定返回值为webelement才可以进行元素操作(click(),send_keys()等)
#需要点到conditions的源码中查看返回值
#不是每个expected_conditions方法的返回值都是webelement
WebDriverWait(self.driver,10,0.5).until(
expected_conditions.element_to_be_clickable(
(By.ID,'username'))).click()
selenium expected_conditions官方说明书
element_to_be_clickable()元素是否可点击
visibility_of_element_located()元素是否可见
url url_contains()
title title_is()
frame frame_to_be_available_and_switch_to_it(locator)
alert alert_is_present()
#重新封装click,实现多次点击方法,直到下一个元素出现
def multiply_click(target_element,next_element):
def _inner(driver):
#driver是形参
driver.find_element(*target_element).click()
#*target_element,解元组
return driver.find_element(*next_element)
return _inner
问题:until里的driver是哪来的?
高级控件交互方法
ActionChains:执行pc端的鼠标双击,点击,右键,拖拽等事件
TouchAction:模拟pc端和移动端的点击,滑动,拖拽,多点触控等事件
import time
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
import pytest
class Test_ActionChains:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(3)
# def teardown_class(self):
# self.driver.quit()
@pytest.mark.skip
def test_clicks(self):
self.driver.get("https://sahitest.com/demo/clicks.htm")
click_element = self.driver.find_element(By.XPATH,'//input[@value="click me"]')
double_click_element = self.driver.find_element(By.XPATH,'//input[@value="dbl click me"]')
right_click_element = self.driver.find_element(By.XPATH,'//input[@value="right click me"]')
action = ActionChains(self.driver)
#声明一个action变量,可以调用多个方法,ActionChains需要传入driver
time.sleep(3)
action.click(click_element)
#点击元素
action.double_click(double_click_element)
#双击元素
action.context_click(right_click_element)
#右键元素
action.perform()
#需要调用preform方法,依次调用多个方法
@pytest.mark.skip(reason='别问')
def test_moveto(self):
self.driver.get("https://www.baidu.com/")
element1 = self.driver.find_element(By.XPATH,'//span[text()="设置"]')
action = ActionChains(self.driver)
action.move_to_element(element1)
#将光标移动到元素上
action.perform()
time.sleep(3)
def test_draganddrop(self):
self.driver.get("https://sahitest.com/demo/dragDropMooTools.htm")
element1 = self.driver.find_element(By.XPATH,'//div[text()="Drag me"]')
element2 = self.driver.find_element(By.XPATH,'//div[text()="Item 1"]')
action = ActionChains(self.driver)
action.drag_and_drop(element1,element2)
#将元素拖拽到另一元素上,然后松手
action.perform()
time.sleep(3)
def test_sendkeys(self):
self.driver.get("https://www.baidu.com/")
element1 = self.driver.find_element(By.ID,'kw')
element1.click()
action = ActionChains(self.driver)
action.send_keys('123456').pause(1)
action.send_keys(Keys.SPACE).pause(1)
action.send_keys('123').pause(1)
action.send_keys(Keys.BACKSPACE).pause(1)
#send_keys可以传入键盘上的按键
action.perform()
time.sleep(3)
def test_scroll(self):
self.driver.get("https://www.baidu.com/")
kw = self.driver.find_element(By.ID,'kw')
kw.send_keys("selenium")
su = self.driver.find_element(By.ID, 'su').click()
time.sleep(3)
ActionChains(self.driver).scroll(0,0,0,10000).perform()
#滑动页面
time.sleep(3)
多窗口处理
1,获取当前窗口 driver.current_window_handle
2,获取所有窗口driver.window_handles
3,跳转窗口 driver.switch_to_window
def test_clicks(self):
self.driver.get("https://mail.163.com/")
register = self.driver.find_element(By.XPATH,'//a[text()="注册网易邮箱"]')
register.click()
allwindows = self.driver.window_handles
currentwindow = self.driver.current_window_handle
self.driver.switch_to.window(allwindows[-1])
#切换到最后一个窗口,否则定位不到
self.driver.find_element(By.XPATH,'//input[@class="username"]').send_keys('saber1')
time.sleep(3)
frame窗口处理
1,frame是前端的框架,其中frame和iframe定位不到,需要切换到frame内
2,frame可以通过id定位,
driver.switch_to.frame('iframeResult')
3,frame如果没有id,可以通过index定位,就是该frame是页面内的第几个frame,index从0开始表示第一个
driver.switch_to.frame(0)
4,切换到当前frame的上级节点(可以是frame可以不是frame)
driver.switch_to.parent_frame()
5,切换到默认的frame(可以是frame可以不是frame),就是刚打开页面的节点
driver.switch_to.default_content()
class Test_switch_frame(Base):
def test_switch(self):
self.driver.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
self.driver.switch_to.frame('iframeResult')
#切换frame可以通过 frame的id定位
print(self.driver.find_element(By.ID, 'draggable').text)
self.driver.switch_to.parent_frame()
#切换到当前frame的上级节点(可以是frame可以不是frame)
self.driver.switch_to.default_content()
#切换到默认的frame(可以是frame可以不是frame),就是刚打开页面的节点
文件上传,页面弹窗
1,input标签可以直接使用send_keys(文件路径)上传文件
2,alert一般不能直接定位到,可以通过switch_to.alert来定位
3,alert有内置方法
alert.text获取文字信息
alert.accept()确认
alert.dismiss()关闭
alert.send_keys()输入文本
class TestAlert(Base):
def test_alert(self):
self.driver.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
self.driver.switch_to.frame('iframeResult')
#切换到frame里
drag = self.driver.find_element(By.ID,'draggable')
drop = self.driver.find_element(By.ID,'droppable')
actions = ActionChains(self.driver)
#实例化actionchains
actions.drag_and_drop(drag,drop)
#调用拖动松开方法
actions.perform()
#执行action
alert = self.driver.switch_to.alert
#定位到alert
alert.accept()
# alert点击确认
self.driver.switch_to.default_content()
#切换到默认位置
self.driver.find_element(By.ID,'submitBTN').click()
time.sleep(4)
自动化关键数据处理
python内置logging库的日志级别
1,DEBUG 细节信息,仅当诊断问题时适用(debug)
2,INFO 确认程序按预期运行
3,WARNING 表明有意境或即将发生的意外(例如:磁盘空间不足)。程序仍按预期进行
4,ERROE 由于严重的问题,程序的某些功能已经不能正常执行
5,CRITICAL 严重的错误,表明程序已不能继续执行
打印当前级别及以上的日志
logging.basicConfig(filename='logdemo.log',
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s (%(filename)s:%(lineno)s)',
datefmt='%Y-%m-%d %H:%M:%S')
logging官方文档
https://docs.python.org/zh-cn/3/howto/logging.html
常用logging配置
https://ceshiren.com/t/topic/13564
使用logging.conf方法
import logging.config
logging.config.fileConfig("logging.conf")
#获取logging.conf配置
logger = logging.getLogger("main")
#传入记录器,main是logging.conf中配置的logger
logger.debug("这是debug日志")
获取截图的方法
driver.save_screenshot(filename)
获取页面源码
driver.page_source
使用方法,可以保存到文件中,用于验证
web自动化高级
自动获取异常截图
好处:增加自动化测试的可测性,丰富报告
实现原理:
装饰器
自动化关键数据记录:日志(logger.info()),截图(driver.save_screenshot(filename)),页面源码(driver.page_source)
使用try catch获取异常,保存截图和源码,并附在allure报告中
import time
import allure
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestBaidu:
def test_baidu(self):
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://www.baidu.com/")
try:
driver.find_element(By.ID, "su1")
except Exception:
# time1 = time.strftime("%Y-%m-%d %H:%M:%S") 文件名不能有空格,不能使用格式化后的时间
# int是因为time.time()获取的时间戳有小数部分,int处理只取整数
time1 = (int(time.time()))
image_path = "./data/images/{}.PNG".format(time1)
page_source_path = "./data/page_source/{}.html".format(time1)
# 保存截图
driver.save_screenshot(image_path)
# 保存页面源码
with open(page_source_path, "w", encoding="utf-8") as f:
f.write(driver.page_source)
# 在allure报告中贴上文件,attachment_type参数可以在allure报告中自动转换为所选格式
allure.attach.file(image_path, name="picture",
attachment_type=allure.attachment_type.JPG)
allure.attach.file(page_source_path, name="page_source",
attachment_type=allure.attachment_type.TEXT)
问题1:影响了测试的结果,本来是报错的,但是被try catch之后,pytest记录为pass
解决:raise Exceptions 抛出异常
问题2:不能每次校验都写一边代码,降低耦合
解决:使用装饰器
带参数装饰器的典型写法
def ui_error(fun):
def inner(*args,**kwargs):
"""写入装饰代码
"""
return fun(*args,**kwargs)
将上面的try catch代码封装成装饰器
import time
import allure
from selenium import webdriver
from selenium.webdriver.common.by import By
def expected_ui_error(fun):
def inner(*args, **kwargs):
# 上面是带参数装饰器的典型写法
try:
#装饰器return是典型写法
return fun(*args, **kwargs)
except Exception:
driver = args[0].driver
# time1 = time.strftime("%Y-%m-%d %H:%M:%S") 文件名不能有空格,不能使用格式化后的时间
# int是因为time.time()获取的时间戳有小数部分,int处理只取整数
time1 = (int(time.time()))
image_path = "./data/images/{}.PNG".format(time1)
page_source_path = "./data/page_source/{}.html".format(time1)
# 保存截图
driver.save_screenshot(image_path)
# 保存页面源码
with open(page_source_path, "w", encoding="utf-8") as f:
f.write(driver.page_source)
# 在allure报告中贴上文件,attachment_type参数可以在allure报告中自动转换为所选格式
allure.attach.file(image_path, name="picture",
attachment_type=allure.attachment_type.JPG)
allure.attach.file(page_source_path, name="page_source",
attachment_type=allure.attachment_type.TEXT)
raise Exception
return inner
class TestBaidu:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
@expected_ui_error
def find(self,by,element):
return self.driver.find_element(by,element)
def test_baidu(self):
self.driver.get("https://www.baidu.com/")
self.find(By.ID,"su1")
self.driver.quit()
