一、背景
上半年公司的网关系统进行了重构,需要把零售业务已有的网关接口迁移到新网关上。这些接口每天都有成千上万次请求,为商家提供各种服务,稍有不慎就容易出现较大故障,所以如何迁移是个比较慎重的问题。
这个迁移项目主要的验证重点是:确保新网关对于接口的请求和返回的处理和老网关一致;而主要的验证难点在于,仅从功能层面进行手工验证很难覆盖各种场景,尤其是如何构造各种请求参数以及检查各种返回的内容。若要人肉进行细致的接口级别的验证,那么花费的时间就会很长、效率很低。
经过统计和梳理,涉及的接口超过了 1000 个,在这个数量级上,总花费的时间成本很高,研发团队难以承受。这不得不让我们停下来思考一下,是否有另一种高效的方式来解决这个问题。这时就想到了采用录制回放对比的方式。
随着业务的快速发展,回归时需要考虑的场景越来越多,测试的耗时越来越长,越来越多的公司提出并采用录制回放的方式来提高效率,比如阿里开源的 jvm-sandbox-repeater,基于已有的流量进行录制,无需人肉准备脚本和数据,通过将录制的流量进行回放,还原真实的场景,最后提供回放结果判断是否符合预期,提高业务回归效率。
从场景上来说,网关迁移验证做的也是回归测试,这个思路也是通用的,所以设计了一个类似的系统进行回放对比验证。
二、系统设计
如果需要采用录制回放对比的方式,首先第一步就是录制,在录制前需要确认下数据和流量的来源。数据越丰富、多样性越强,回放能够发现的问题越多,一些实时的流量采集方式通过拦截转发的方式获取数据,所以需要一定的配置和改造成本。幸运的是网关的日志对于接口的请求参数会进行记录,实际上已经完成了录制这个过程,可以采用成本最小的方式:通过拉取测试环境老网关的日志来获取请求数据,然后进行解析再进行回放和对比。
基本流程如下,下面会对各步骤的逻辑进行说明
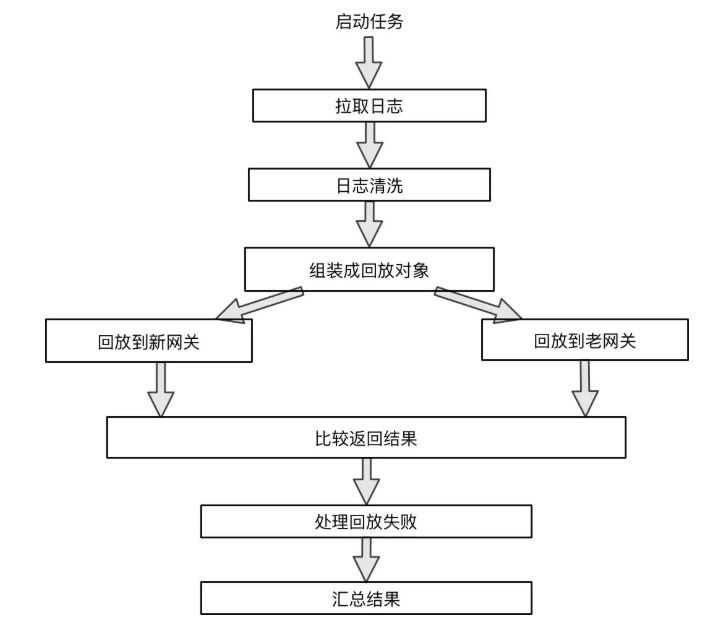
2.1 日志拉取和清洗
作为整个流程的第一步:通过拉取日志获得需要回放的流量。
回放对实时性要求不高,但是当初请求的时刻和回放的时刻之间的时间差也不能太长:比如早上创建一个商品并进行了查询操作,下午可能进行了删除,如果选择晚上再进行回放的话,查询结果就会为空,数据的质量就会下降,造成数据损耗。需要考虑设置一个较短的时间间隔进行回放,目前通过定时任务每隔一小时启动一次进行拉取和回放,根据当前启动时间自动生成对应的时间范围,去日志平台获取日志:比如任务启动时间是 11:10 分,那么自动转换成 10:00-11:00 的时间范围去拉取日志进行回放。
获得日志后,第二步就是日志清洗。
日志清洗的作用有两个:
- 过滤。有一些接口是不需要迁移到新网关的,进行过滤,减少对最后统计结果的干扰。另外,录制回放运行时也会请求网关,需要过滤掉这部分人工流量。
- 采样。虽然是测试环境,一天的数据量也有 10W+ ,全部处理时耗较长;同时,初期会有大量重复问题爆出,增大排查成本。根据二八定律以及实际的观察,小部分接口贡献了大部分流量,考虑每个接口雨露均沾和数据的多样性,选择接口+场景作为采样纬度,返回结果中的不同 code 认为是不同的场景,这样除了正常请求,也考虑到异常请求的回放。
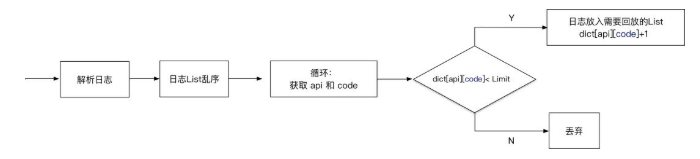
初期可以设置一个较小的采样阈值 Limit 来收集问题,减少人工排查问题的成本。等问题修复稳定运行一段时间后,再考虑逐步增大阈值。
2.2 进行回放
考虑到数据是不断变化的,同时对于登陆态生命周期是否正常也需要进行观察,所以回放并不是拿新网关请求的返回和日志中记录的老网关进行对比,而是同时请求两个网关,再对各自的返回进行比较。在请求过程中,可能遇到接口超时等情况,遵循尽可能成功的原则,做对应的处理,比如超时进行重试等。
另一个影响比对效率的因素就是性能,每一个请求都可以独立处理,就意味着可以并发执行,如 python 的 multiprocessing 多进程的方法:
p = multiprocessing.Pool(8)
while line:
p.apply_async(process_line,
args=(...))
line = file.readline()
p.close()
p.join()
在 6C 的机器上对 2000 条日志进行回放,通过不同的并发数观察结果如下:
pool(1) 耗时:1292s
pool(6) 耗时:212s
pool(8) 耗时:155s
pool(12) :耗时:102s
发现性能提升还是很明显的,根据实际运行机器的CPU性能配置适合的并发数即可。
2.3 结果比较
整个系统中最核心的逻辑就是结果对比逻辑了。从新网关获取到的返回 response1 和老网关获取到的返回 response2 ,理论上是要一致的。初步的比较逻辑就是采用递归比较,将返回对象中的每个元素进行比较,判断内容是否一致。
实际的运行过程中,往往会出现各种正常情况下返回结果不一致的情况:
- 接口请求返回含有时间字段,而时间字段是根据当前处理时间生成的。
- 一些写接口返回的是新生成的对象 id ,每次请求返回都不同。比如创建一个商品,下了一笔订单,返回的都是新生成的商品 id 或者订单号。
- 返回数据列表时,有些场景返回的数据是不保证顺序的,导致偶尔的比对失败。
针对上述情况,设计了兼容模式进行特殊处理。首先定义一个 dict 存储接口名以及需要忽略的字段
ignore_dict = {
'youzan.retail.stock.receiving.order.export.1.0.0': ['response'],
'youzan.retail.trademanager.refundorder.export.1.0.0': ['response'],
'youzan.retail.trade.api.service.pay.qrcode.1.0.1': ['url'],
'youzan.retail.product.spu.queryone.1.0.0': ['list']
}
其中定义两个特殊字段 response 和 list:
- 对于 response 字段,只检查字段长度和类型,不检查内容是否一致,主要针对返回序列号、订单号的场景
- 对于 list 字段,对于其中的list类型做无序比较处理
核心对比方法如下,对于需要忽略的字段和类型进行特殊处理,减小误报:
def compare_data(data_1, data_2, COMP_SWITCH, ignore_list):
if isinstance(data_1, dict) and isinstance(data_2, dict):
diff_data = {}
only_data_1_has = {}
only_data_2_has = {}
d2_keys = list(data_2.keys())
for d1k in data_1.keys():
# 忽略某些字段
if COMP_SWITCH and __doignore(d1k, ignore_list):
continue
if d1k in d2_keys:
d2_keys.remove(d1k)
temp_only_data_1_has, temp_only_data_2_has, temp_diff_data = compare_data(data_1.get(d1k),
data_2.get(d1k), COMP_SWITCH,
ignore_list)
if temp_only_data_1_has:
only_data_1_has[d1k] = temp_only_data_1_has
if temp_only_data_2_has:
only_data_2_has[d1k] = temp_only_data_2_has
if temp_diff_data:
diff_data[d1k] = temp_diff_data
else:
only_data_1_has[d1k] = data_1.get(d1k)
for d2k in d2_keys:
if COMP_SWITCH and __doignore(d2k, ignore_list):
continue
only_data_2_has[d2k] = data_2.get(d2k)
return only_data_1_has, only_data_2_has, diff_data
else:
if data_1 == data_2:
return None, None, None
else:
if COMP_SWITCH and isinstance(data_1, list) and isinstance(data_2, list):
if __process_list(data_1, data_2, COMP_SWITCH, ignore_list):
return None, None, None
else:
return None, None, [data_1, data_2]
else:
return None, None, [data_1, data_2]
比对逻辑中加入了 COMP_SWITCH 开关,先按常规方式进行比较,当常规方式比较失败,再开启兼容模式进行比较,这样的做法是为了统计和观察哪些接口会使用兼容模式,使用兼容模式是否合理(还有兼容模式本身有没有bug~~)。
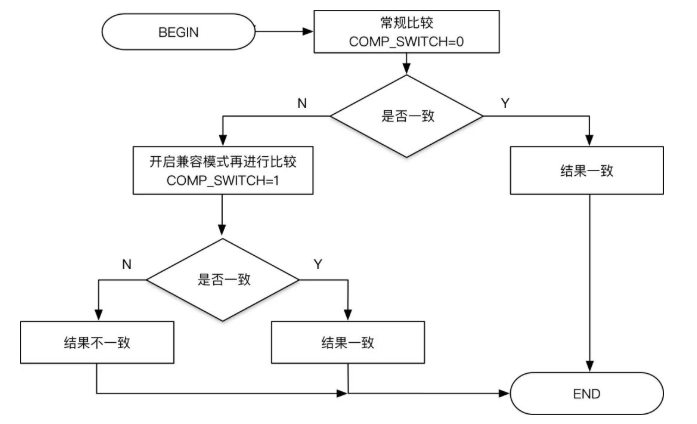
2.4 处理失败
每次执行任务会生成一个批次号,每个接口请求回放对比完成后,保存结果时也会带上批次号写入数据库。当任务执行完成后,会根据批次号将失败的结果再拉取出来进行重试。
失败重试时,回放的逻辑和正常运行时略有不同,两次回放间隔了 30s 依次进行,这是避免当多次请求操作同一个对象时,因为第一次请求执行比较慢导致第二次请求命中唯一性校验而失败。
当重试结果仍然失败,那么需要人工介入进行排查,判断是否是新网关逻辑的问题还是有字段需要特殊兼容的问题,进行处理。
2.5 结果判断和迁移策略
对于回放成功的接口,会记录当时回放成功返回的code等信息到结果表,同时记录对应code的次数加1,多次回放后会形成如下的统计结果:
{'200': 94, '234000001': 16, '234000002': 1}
当统计结果中存在正常的code和异常的code,同时没有回放失败记录的情况,就可以认为新网关对该接口的返回和老网关是一致的。回放通过的次数越多,可信性就越强。在这种情况下再将接口的流量切换到新网关,观察日常业务调用的情况,通过拉取新网关日志,记录返回的code和数目,当新网关返回的结果中也包含正常和异常的code时,认为在新网关也能正常请求,可以准备线上迁移了。
通过QA环境的对比回放,同时在预发环境全量迁移后观察业务功能是否正常,最后线上逐步灰度流量和监控,最后确保接口迁移到新网关是正常的。
三、面向普通测试场景的解决方案
因为属于回归类的工具,这套系统除了可以解决验证新老网关返回对比是否一致的问题外,还能够帮助验证分支环境和基础环境之间请求对比是否一致的问题(尤其是系统重构的情况),对业务场景进行回归。
为支持普通回归场景,只要在原来的系统上进行少量的改动:
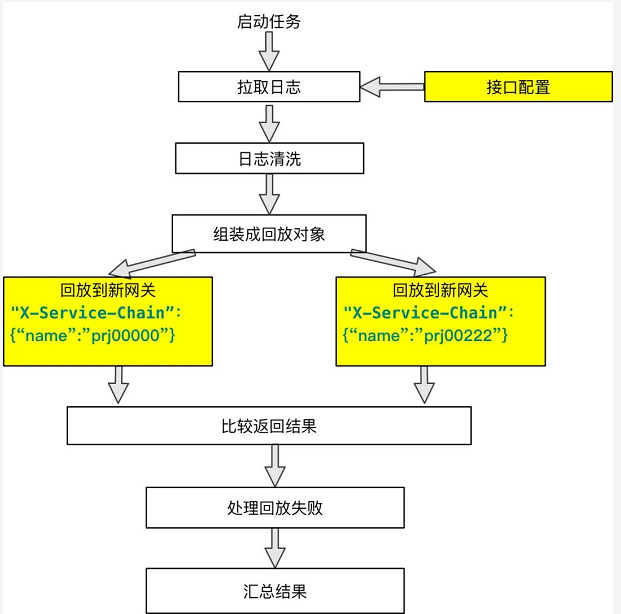
主要的改动就是配置需要回放的接口和需要回放到的环境。在回放阶段,之前是回放到新网关和老网关,现在都回放到同一网关,通过不同的 X-Service-Chain 请求头,控制请求到达不同的后端环境,然后获得返回值进行对比。
四、最后
本文提供了一种通过采集日志进行回放对比来解决接口对比一致性的思路,运用到了新老网关重构验证等回归场景。
在新老网关迁移验证过程中,该系统起到了非常大的作用。通过该系统校验了接口 1200+,产生回放记录数目 30w 条,发现问题 30+ ,最终保障了线上切换工作的平稳进行。
由于能够获取了接口和参数,可以进一步做一些权限、后端参数校验这样的检查,减少测试人员在这方面投入的测试时间,这套系统已经投入实际使用,后面有机会可以再介绍其实现原理和使用效果。
期待未来能够挖掘出更多的使用场景,解决更多的验证问题,提高测试的效率和准确性。
扩展阅读:
原文转自有赞Coder公众号
