批处理任务编排
初学者容易误以为容器的任务只在于部署行为--将软件在容器中部署以提供持续的服务。但其实容器也同样大量的被应用于批处理程序的运行上。比如测试行为是典型的批处理任务范畴, 它不提供持续稳定的服务, 它只是一段特定的程序,而一但这段测试程序结束后就应该销毁一切,包括执行环境和所占用的资源,容器对比于传统的虚拟机的优势也在于除了容器更加的轻量级外, 容器的创建和销毁都很方便,通过 K8S 的能力可以很方便的在需要时创建,结束时销毁回收资源以达到更好的资源利用率(就如上篇文章中介绍的 Jenkins 与 K8S 打通后的运作模式)。而现在准备的测试案例会更加特殊, 它需要重复运行 N 次,因为本次执行的是稳定性测试(也有人叫它浸泡测试或者长期高压测试),这种测试类型的特殊之处就在于它的目的是验证被测系统在长期的高压下是否仍能够提供稳定的服务。所以它的测试方式是长期的(1 天,1 周甚至更长时间)不间断的运行自动化测试。而自动化测试的数量是有限的,它不可能持续的运行那么长时间,所以才需要重复运行。在不改造测试框架的前提下 K8S 能通过什么样的方式来帮助完成这个测试需求。首先看一段 K8S 提交任务的配置文件。
yaml
apiVersion: batch/v1
kind: Job
metadata:
name: stable-test
spec:
template:
spec:
containers:
- name: stable
image: registry.gaofei.com/stable_test
imagePullPolicy: Always
volumeMounts:
- name: stableconfig
mountPath: '/home/work/configs'
readOnly: false
restartPolicy: Never
volumes:
- name: 'stableconfig'
configMap:
name: stableconfig
backoffLimit: 4
parallelism: 1
completions: 1000
上面定义的是向 K8S 提交一个 job 类型的也即是批处理程序请求的配置文件, 将这个配置文件保存为 yaml 文件后就可以通过 kubectl 命令行将任务提交到 K8S 集群中运行了, job 会帮助创建相应的 POD 来完成任务。虽然我已经对这段配置做了一定程度的删减,但仍然有不少的字段类型容易让新手眼花缭乱。不过本次案例只需关注几个重点的地方,第一个是在文件中的 template 字段, 它代表了 POD 的模板, job 通过此模板来动态的创建 POD,它定义了本次执行测试的运行环境, 也就是测试是在 POD 中的容器中执行的。K8S 会根据用户填写的内容来启动 POD。第二个需要注意的地方是配置中最下面的 3 个字段:
-
backoffLimit:可容忍的失败次数。稳定性测试是要长期执行的,而任何长期执行的任务都无法保证在运行过程中 100% 的不出问题,有些时候网络卡顿或者公司内的一些基础设施的临时中断都可能造成测试的失败。所以 K8S 会在任务失败时尝试进行重试(当整个节点出现异常时,K8S 可以将容器调度到其他节点上重试执行,拥有更好的容错能力),而这个字段可以理解为重试的次数
-
parallelism:并行的数量。如果你的批处理任务需要并发能力,那么 K8S 会按照这个字段的数字同时启动多个容器来并发的执行。由于大部分的测试并发能力来源于测试框架而不是外部软件, 所以本次测试在这里填写为 1 就可以。
-
completions:任务成功执行 N 次后结束任务。即便是像稳定性测试这种需要长期运行的测试类型,它也有结束测试的时候。所以把这个参数设定为 1000 代表当测试重复运行了 1000 次后就结束本次的批处理任务。
注意:每次测试运行结束后,K8S 会销毁当前的容器,并启动一个一模一样的新容器来执行新的任务。也就是在的案例里如果不出意外的话,前后会启动 1000 个容器来完成本次的稳定性测试。通过这样一个案例的讲解可以体会一下相比于原生的 Docker 容器,K8S 带来了多少额外的能力。在 K8S 中容器只不过是程序的运行时环境而已,除了程序能运行起来,K8S 更关注的是程序怎样更好的运行。通过上面针对配置文件最后 3 个字段的讲解可以看出来 K8S 在尝试帮助用户解决更复杂的程序运行问题。在本案例中如果不使用 K8S,用户需要编写自己的模块来控制测试用例的重复执行,并发,容错和重试机制,也就是说用户需要自己编写代码来对测试用例进行"编排"。在传统的容器场景中,很多人都会把容器当做一个小型的虚拟机来使用–只要程序能在容器里跑起来就可以了。这种模式并不具备"编排"的思维能力,真实的企业场景下要求的不仅仅是把程序跑起来就可以了,还关心容器调度到什么节点,什么时候触发和结束任务,当任务出现异常时要如何处理,容器和容器之前如何配合以便完成更大的任务等等。这便是 K8S 提供的"容器编排"了。希望读者可以用心体会"容器编排"这 4 个字的含义。
接下来再看一下,如果希望任务能够定时触发该怎么办呢?K8S 中同样提供了 CronJob 类型的任务,可以看到在 schedule 字段中可以填写 cron 表达式来定时启动容器完成的批处理任务。
yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: k8scleaner
spec:
schedule: '0 * */1 * *'
jobTemplate:
spec:
template:
spec:
containers:
- name: k8scleaner
image: reg.gaofei.com/qa/k8s-cleaner:v2
imagePullPolicy: Always
restartPolicy: Never
实际上,目前看到的编排能力仍然是 K8S 的冰山一角,K8S 目前已经成为了分布式计算平台,支持很多大数据和机器学习的计算框架比如 Spark 和 Flink。下面是将 Spark 任务调度到 K8S 中执行的 Demo。
bash
./bin/spark-submit \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--master k8s://https://172.27.130.144:6443 \
--kubernetes-namespace spark-cluster \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.executor.instances=5 \
--conf spark.app.name=spark-pi \
--conf spark.kubernetes.driver.docker.image=kubespark/spark-driver:v2.2.0-kubernetes-0.5.0 \
--conf spark.kubernetes.executor.docker.image=kubespark/spark-executor:v2.2.0-kubernetes-0.5.0 \
local:///opt/spark/examples/jars/spark-examples_2.11-2.2.0-k8s-0.5.0.jar
熟悉大数据领域的人都知道 Hadoop 是分布式计算领域中最流行的调度平台。提交的 Spark 任务都会被调度到 Hadoop 集群中进行调度,运行。但是 K8S 也同样具备这样的能力,通过下载支持 K8S 的 Spark 安装包就可以使用 spark-submit 命令将任务提交到 K8S 上以容器的形态执行,在参数中可以指定使用多少个 executor,每个 executor 申请多少资源等等。这便是 K8S 的魅力,如果你深入了解 K8S 会发现更多有趣又好用的功能。
总结
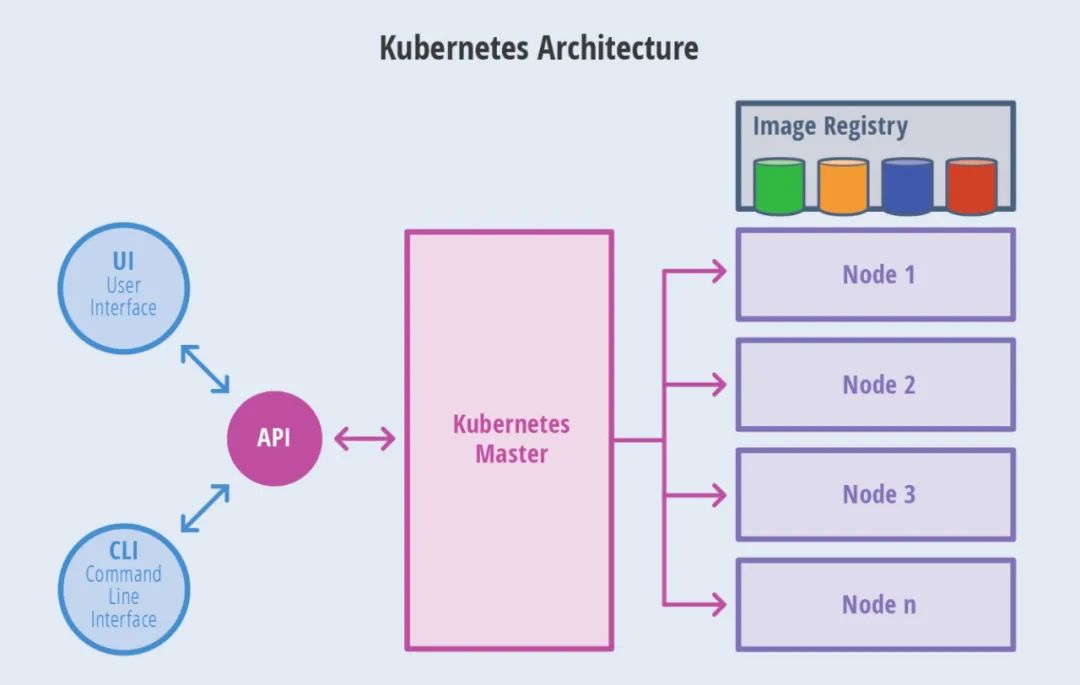
实际上除了上面讲的能力外,K8S 还包含了非常多的容器编排能力,尤其对于在线服务的编排能力上尤为强大, 但这部分内容留待后续讲解。最后附上一个最简单的 K8S 流程图帮助大家理解。毕竟 K8S 还是一个集群管理软件,上述说明的所有案例在提交给 K8S 后, K8S 都会按照自己的调度策略将 POD 调度到一个合适的节点上执行。