
提起正则表达式,可能大家的第一印象是:既强大好用但也晦涩难懂。正则表达式在文本处理中相当重要,各大编程语言中均有支持(跟 Linux 三剑客结合更是神兵利器)。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。(来自百度百科)
个人理解如下:某个大佬为了从字符串中匹配或找出符合特定规律(如手机号、身份证号)的子字符串,先定义了一些通用符号来表示字符串中各个类型的元素(如数字用 \d 表示),再将它们组合起来得到了一个模板(如:\d\d模板就是指代两个数字),拿这个模板去字符串中比对,找出符合该模板的子字符串。
由几个例子去进一步理解,比如现在有一个字符串为:
1.test是一个正则表达式,它的匹配情况:I am a tester, and My job is to test some software. 它既可以匹配tester中的test,又可以匹配第二个test。正则表达式中的test就代表test这个单词本身。
2.\btest\b是一个正则表达式,它的匹配情况:I am a tester, and My job is to test some software. 它只能匹配第二个test。因为\b具有特殊意义,指代的是单词的开头或结尾。故tester中的test就不符合该模式。
3.test\w*是一个正则表达式,它的匹配情况:I am a tester, and My job is to test some software. 它匹配出了tester,也匹配出了第二个test。其中\w的意思是匹配字母数字下划线,表示的是数量,指有0个或多个\w。所以这个正则表达是的意思就是匹配开头为test,后续跟着0个及以上字母数字下划线的子字符串
4.test\w+是一个正则表达式,它的匹配情况:I am a tester, and My job is to test some software. 它只匹配了tester。因为+与不同,+的意思是1个或多个,所以该正则表达式匹配的是开头为test,后续跟着1个及以上字母数字下划线的字符串。
通过上述几个例子,应该可以看出正则表达式的工作方式,正则表达式由一般字符和元字符组成,一般字符就是例子中的‘test’,其指代的意思就是字符本身,t匹配的就是字母t;元字符就是例子中有特殊含义的字符,如\w, \b, *, +等。后续介绍一些基础的元字符。
元字符有很多,不同元字符有不同的作用,大致可以分为如下几类。
有些元字符专门用来指代字符串中的元素类型,常用的如下:

通过上述表格中的数据可以发现,\w,\d,\s都有一个与之相反的元字符(将对应字母大写后就是了)。\w匹配所有字母数字下划线,那么\W就是匹配所有不是字母数字下划线的字符。只要记住其中3个,另外3个就很好记了。
乍一看这几个元字符挺简单的,但是经常不用的话保不准会忘记,此处分享一下我的记忆方法。我把这几个元字符都当作是某一个单词的缩写(虽然可能就是某个单词的缩写,但是没有找到准确的资料去印证):
- \s是space(空间)的缩写
- \d是digit(数字)的缩写
- \w是word(可以理解成不是传统意义上的单词而是代码中的变量名,变量名可包含的元素就是字母数字下划线)的缩写
好了,看到此处你应该已经熟记了6个元字符了。
接下来,\n和\t平时会经常用到,这个肯定比较熟了,最后一个元字符‘.’可以理解它匹配一行中的所有元素,因为遇到换行符后就不再进行匹配了(万事万物源于一点)。
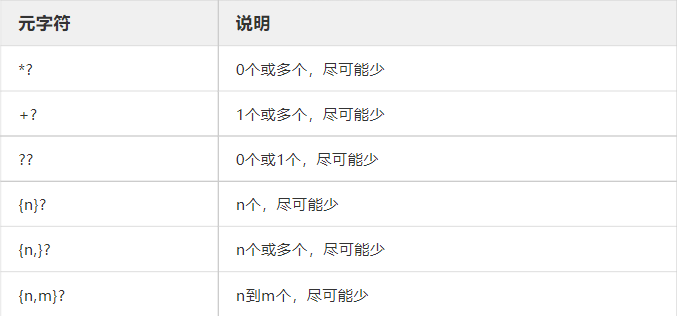
有些元字符用于表示某种元素的数量,如\d表示一个数字,当你想表示6位数字怎么办?当然可以\d\d\d\d\d\d ,但确实太麻烦了,为了简便就需要一些表示数量的元字符,上述可以写成\d{6},元字符详情如下:

这几个元字符还算比较好记。
表示0个或多个
+表示1个或多个(这个可能会混淆,或许你可以这么记, 表示10=0或多个,+表示1+0=1或多个)
?表示0或1个,可以理解成某个人在问你这个类型的元素有还是没有呀?你回答可能有(1)也可能没有(0)。
剩下的三个只要记住大括号是用来表示数量,后续我们还会看到除了{}外,还有[]和()。它们各有各的作用。
有些元字符没有具体的的匹配项,它只是一个抽象的位置概念,它用来表示字符串中的各个位置。一个字符串的位置可以分成:字符串的开头或结尾、单词的开头或结尾。
如字符串‘I am a tester_.’,I前面是字符串的开头位置,英文句号后面为字符串的结尾位置,每一个word(注意此处指的不是传统意义上的单词)前后的位置即为单词的开头或结尾,对于‘tester_’来说t前面是单词开头,下划线是单词结尾。

其中\b在前面的例子中有说过,此处可以以这种方式记忆:\b是block(块)的缩写,即一个单词是一块内容,\b是这一块的边界。至于另外两个元字符,暂时没找到很好的记忆方法(^一个尖角,小荷才露尖尖角?),但应该也不难记。
此处有个地方要提及一下,所有表示位置的不会实际占用字符。为了理解可以继续看最上面的第二个例子,\btest\b最终匹配出来了子字符串“test”,而不是“ test ”。
大家依据目前了解的元字符概念,可以思考一下这个正则表达式^\d{6,10}$,和\d{6,10}的区别。针对字符串‘12345678‘,第一个和第二个都可以匹配出’12345678‘。
但是针对字符串’W12345678‘,只有第二个可以正确匹配出’12345678‘,原因在于第一个正则表达式的意思匹配一个字符串只有6-10个数字组成,而第二个正则表达式意思是匹配字符串中的6-10个连续数字。
除了这三个元字符表示位置外,还有零宽断言、负向零宽断言也表示位置,后续会详细介绍。
字符转义的概念大家肯定不陌生,对于, +等有特殊意义的元字符,假如你想匹配5个号应该怎么写,{5}吗?肯定不是,这样写是语法错误,应该使用\将其转义:*{5}。这样一来*的特殊意义就被\给取消了,想要匹配\的话,也是一样,再用一个\把特殊意义取消掉就好了。
前面列出了部分用于表示意义的元字符,但是可能这几个元字符覆盖的都太广泛了,想要具体的匹配某一类字符。比如就是想匹配abcd这四个字符中的某一个,正则表达式当然也是支持的。
这时候就需要用到第二种括号,中括号。匹配abcd中的某一个可以写成[abcd]或者[a-d],意思是匹配一个a-d中的任意字符。相反若匹配非abcd的任意字符,可以写成[^abcd],意思是匹配一个不是abcd的字符。
括号内也可以写入不同类型的元素,如[a-d1-7@],表示的是匹配一个a-d或1-7或@中的任意字符,[^a-d1-7@]则与之相反
讲完中括号后我们可以看一下小括号(),小括号的意思是分组,即小括号内部的所有元字符是一个整体。
之前有学过表示数量的元字符,但是那个表示的数量都是针对于一个元字符来说的,比如ab+表示的是匹配一个a后面跟着1个或多个b的子字符串。
倘若我们想要匹配的是1个或多个ab(如:abababab),此时分组就派上作用了,可以这么写:(ab)+。此时ab被绑定为一个整体,后面的数量元字符对这个整体起作用。
元字符中有一个或运算符,它与大多数编程语言类似都是用 | 来表示。它的作用为:Ab|aB表示的是匹配Ab或者aB。通过这个例子可以很直观的理解该元字符的作用。当然它也经常和分组一起使用:(Ab|aB)+c,该正则匹配开始为1-N个Ab或aB之后是c的子字符串,如:AbaBc, AbAbAbaBc。
后向引用的使用是依附于分组的,分组的概念之前讲过了。
首先,我们先看一下正则表达式中组号的分配方式,此时先看一个用到分组的正则表达式:(ab)?(c|C)d。这个正则的意思大家现在肯定都清楚了。这个正则表达式里面用到了两个分组分别是(ab)和(c|C)。
正则内部会对所有分组进行组号分配,从左向右,第一个分组(ab)的组号是1,第二个分组(c|C)的组号是2。而组号0代表的是整个正则表达式。尝试过python正则的此处应该有印象,匹配对象的group方法传参为0或不传则返回整个正则所匹配的结果,传参为1为第一个分组匹配的结果。
了解了组号分配方式后,可以开始解释后向引用了。后向引用就是将前面某个分组已经匹配的数据拿过来用,第一个分组匹配的数据用\1代替,第二个分组匹配的数据用\2代替,依次类推。
似乎不是特别好理解,直接看例子吧,(ab)?(c|C)d\2D该正则中\2表示的是第二个分组匹配到的数据,若第二个分组匹配到了c那么\2就是c,反之亦然。所以它能匹配到:abcdcD, abCdCD。不能匹配:abcdCD, abCdcD。通过这个例子可以理解它的作用了吧。
当然分组除了有自己的组号外,还可以给它自定义组名。不同编程语言中的方式不同,Python中自定义组名的格式为:(?Pexp),Name为你自定义的组名,exp代表任意元字符的组合。后面引用的方法为(?P=name)。所以上面例子可以修改成:(ab)?(?Pc|C)d(?P=CWord)D。
上一节简单的讲了一下正则表达式是如何分配组号的,但其实还有几个需要注意的地方。 - 虽然组号是从左向右进行分配,但是扫描两遍,第一遍先分配给未命名的分组,第二遍再分配给命名的分组。所以命名后的分组组号会更大
- 使用(?:exp)可以使一个分组不分配组号,如(?:ab)?(c|C)d\2D中(ab)就没有分配到组号,而(c|C)组号为1
人性是贪婪的,正则表达式与人一样也是贪婪的。一个正则表达式会尽量多的去匹配字符串,如:ab.+c去匹配’abccccc’是会将该字符串全部匹配出来。但有时候我们只想要其匹配’abcc’,此时怎么办呢?需要给正则表达式中表示数量的元字符加一个?变成ab.+?c。此时该正则表达式就变懒了,不会再去匹配那么多,匹配到‘abcc’就完事了。
这两个个概念有些不太好理解。正如前面所说这两个也是表示位置的元字符。从字面意思上理解,零宽代表其没有宽度,即如之前介绍表示位置的元字符中提到的一样,不会实际占用字符。
断言是什么?是assert,是用来判断条件是True还是False。理解完这两个词语的意思后,零宽断言的概念应该也就能理解了。那么负向无非就是它的反义词。
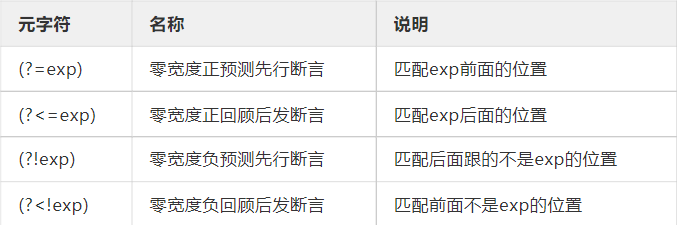
上面的表格主要看第一列它是什么格式就好,反正后面的名称和说明也很难看懂。接下来我来用自己的理解通俗的解释一下这些概念。
首先字符串中可以有四种方式确认某个子字符串的位置,如字符串‘BACAB’中有两个A,A前面是B、A前面不是B、A后面是C、A后面不是C。上述四种条件都能够匹配出唯一一个子字符串A。这个例子大概理解的话就可以往后看了。 - (?=exp)中exp指代的是任意元字符的组合,结合具体的例子来理解该元字符的用法,一个正则表达式为A(?=C),它代表的情况就是A后面是C的情况。所以匹配出了第一个A,由于该元字符是零宽所以它只能匹配出A而不是AC。
- (?<=exp)与上面用法相反,一个正则表达式为(?<=B)A,它代表的情况就是A前面是B的情况。所以匹配出了第一个A。如果改成(?<=C)A,则能匹配出第二个A。
- (?!exp)的例子为:A(?!C),它代表的情况为A后面不是C,所以匹配出第二个A。
- (?<!exp)的例子为:(?<!B)A,它代表的情况为A前面不是B,所以匹配出第二个A。
通过上面四个例子的介绍,应该对于这两个概念、四个元字符有了了解。理解是重点,记下来也是重点。本人是这样记下来的,四个元字符的基本格式都是(?),只不过问号后面的不一样。分下面两种情况: - XXX前/后是XXX的话就写一个=,XXX前/后不是XXX的话就写一个!。这个和日常用的=和!=差不多。
- 如果表示的意思是前的话,这个元字符就需要出现在前面且要加一个类似于向前指的箭头<。如果表示的意思是后的话,就什么都不需要加。
通过上面两个情况的归纳,是不是这四个元字符就都记下来了?
到目前为止,正则表达式的基本内容都介绍完了。但是文中用的例子都比较简单,只能帮助你理解概念。如果感兴趣或者工作中能用到的话,还需要后续勤加练习。
你以为文章到总结就结束了?So naive,我再来列举一个测试日常工作中的案例,将理论应用到实践(编程语言选择 Python,因为我目前只会这个)。
设想这么一个场景,在测试过程中需要获取某个时间段内某个程序的运行情况,从而分析出该程序的稳定性或使用频率等指标,该程序的日志记录完备,日志格式固定且已知。这时候最佳的办法就是从该程序日志中进行相关信息的获取。
假如该日志内容格式大概如下(注:该日志样例不是实际项目中的日志文件,为个人举例):
从这个日志中可以看到访问成功的IP及其认证账号、访问失败的IP、程序的错误信息。那么我们怎么把这些数据给抓取出来呢?抓取的方法肯定有很多,如果此时你第一时间想到了正则表达式,那么恭喜你,通过阅读前面的文章,正则已经在你心中留下了痕迹,或者它本来就留有痕迹。
我们先来分析一下第一条日志,其余的与此类似,有用的信息可以分成如下几个片段: - 时间字符串:2020-02-17 11:04:34
- 日志级别:INFO
- IP:182.168.3.111
- 认证邮箱:110232123@qq.com
- 状态码:1
- 客户端获取到的数据大小:12931KB
上面几个片段对应的正则为: - 时间字符串:\d{4}-\d{2}-\d{2}\s*\d{2}:\d{2}:\d{2}
- 日志级别:[INFO]
- IP:(\d{1,3}.){3}\d{1,3}
- 认证邮箱:\w+@\w+.\w+
- 状态码:\d+
- 客户端获取到的数据大小:\d+KB
上述中某几个正则其实并不严谨,比如IP对应的正则还可以匹配出999.999.999.999。严谨的正则表达式是((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)。由于该正则太长,加之此处重点在于如何应用,故暂用其宽松版的正则表达式。
知道了各个字段的正则后,我们可以将它们各自写成一个分组,分组之间填充上其余元字符,把匹配整行日志的正则表达式写出来,如下:
现在我们通过这个正则表达式可以抓取出日志文件中这种格式的日志字符串,再根据组号就可以拿出来对应的数据了。不过根据组号取数据可能会有些含糊不清,或许我们可以给每个分组进行命名(使用python支持的方式),形成如下正则表达式:
好了现在我们可以很清楚的看到,表示时间的分组命名为Time,依次类推。接下来,我们可以使用上述正则表达式去抓取一行日志,再通过分组的名称拿到对于的字符串数据了。具体的代码可以参考下面的样例:
代码中实现了一个函数reg_deal,后面代码都是对于这个函数的实际应用,该函数入参为:正则表达式组成的列表、待匹配的字符串、特殊函数组成的字典。其先循环将字符串与列表中各个正则表达式进行匹配,匹配成功后得到一个匹配对象,调用该匹配对象的groupdict函数可以返回一个结果字典,该结果字典的键为分组的名称,值为分组匹配到的值。针对这一结果字典再进行一步特殊函数处理,如上述中的status字段日志中是码值,但输出结果需要是具体的汉字。故对其进行了一步码值转换操作,对与数据大小将KB转化成了MB。
若使用该函数,需自己将正则表达式写出来并对正则表达式中的分组进行命名,若有些分组数据需要特殊处理,则维护一个特殊函数字典,键为分组名,值为函数(匿名函数或者是函数名称)。将参数传入后即可获得结果字典或者 None。得到结果字典后具体怎么处理就看你接下来的发挥啦。
以上,仅供大家参考,期待多交流指正。
