本文节选自霍格沃兹测试学院内部教材
logstash是ElasticStack(ELK)的一个重要技术组件,用于对数据进行转换处理。他可以接受各种输入源,并按照记录对数据进行变换,并导出到输出源中。
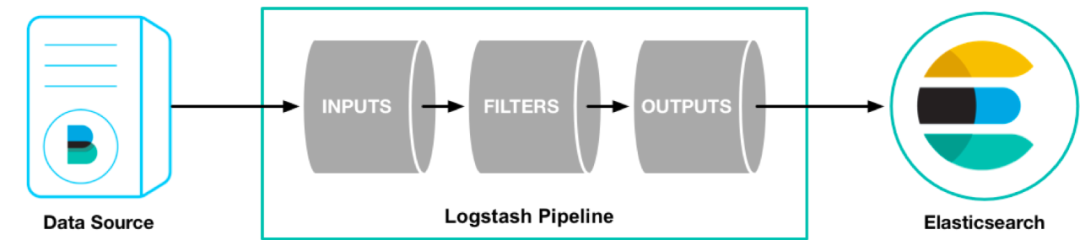
安装
docker pull docker.elastic.co/logstash/logstash
quick start
简单的输入一行内容,并发送给远程的elastic search服务器
docker run -it --rm logstash -e '
input { stdin { } }
filter { json {source => "message"} }
output {
elasticsearch{ hosts=>["x.x.x.x"] }
stdout {}
}
'
输入源
#从csv文件读取
file { path => "/data/ELK/data/*.csv" }
#从kafka中读取
kafka { topic_id => 'topic_name'; zk_connect => '${zookeeper的地址}:2181/kafka'}
常见的filter
#读取csv,并设置表头
csv{columns =>[ "log_time", "real_ip", "status", "http_user_agent"]
#读取json数据
json {source => "message"}
输出源
elasticsearch{ hosts=>["x.x.x.x"] }
stdout {}
完整配置实例
读取csv数据
input {
file {
path => "/data/ELK/data/*.csv"
start_position => beginning
}
}
filter {
csv{
columns =>[ "log_time", "real_ip", "status", "http_user_agent"]
}
date {
match => ["log_time", "yyyy-MM-dd HH:mm:ss"]
}
}
output {
elasticsearch {}
}
读取kafka数据
input {
kafka {
topic_id => 'topic_name'
zk_connect => '${zookeeper的地址}:2181/kafka'
}
}
filter {
csv{
separator => "|"
columns => [ "host", "request", "http_user_agent"]
}
date {
match => ["log_time", "yyyy-MM-dd HH:mm:ss"]
}
}
output {
elasticsearch {
index => "logstash-topic-%{+YYYY.MM.dd}"
}
}
Filebeat
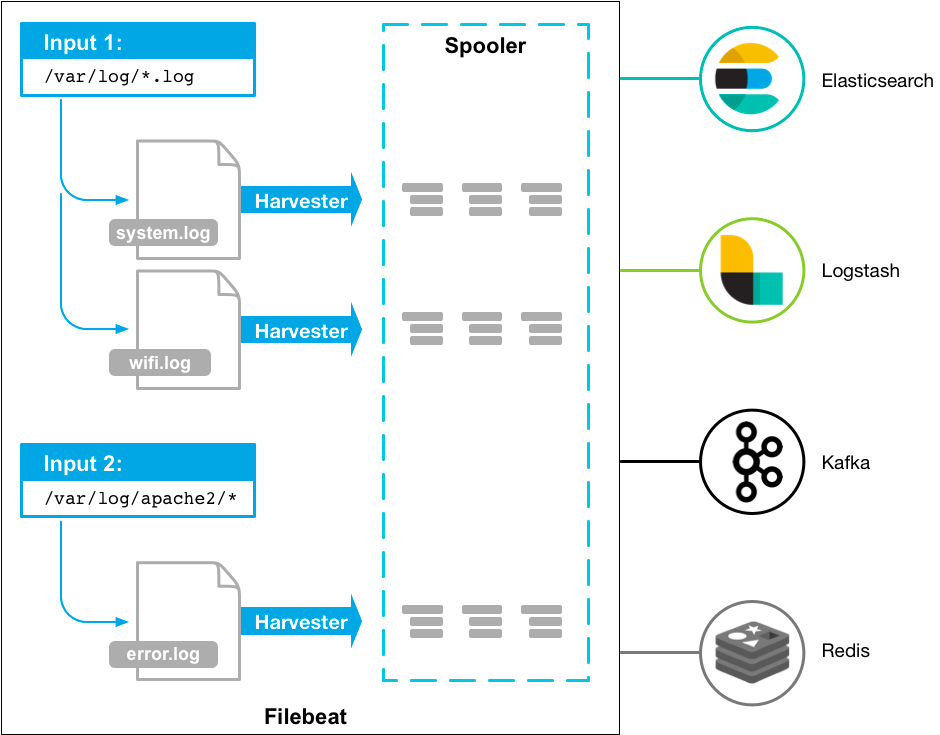
Filebeat是一个高性能的日志采集框架,它主要是以agent模式工作,特点是高性能。用以解决logstash的性能问题,一般我们都会把数据先借助于filebeat采集,并存到redis里,再由logstash对数据进行编辑变换,再输出到es中。
logstash就先介绍到这里,大家可以试着做一下实战练习,分析nginx日志保存到elastic search!
推荐学习
**内容全面升级,4 个月 20+ 项目实战强化训练,资深测试架构师、开源项目作者亲授 **BAT 大厂前沿最佳实践,****带你一站式掌握测试开发必备核心技能(对标阿里P6+,年薪50W+ )!直推 BAT 名企测试经理 ,普遍涨薪 50%+!

