前言
不管是开发同学还是DBA,想必大家都遇到慢查询(select,update,insert,delete 语句慢),影响业务稳定性。这里说的慢,有两个含义一是比正常的慢,有可能正常执行时间是10ms,异常的是100ms 。二是sql执行时间超过设置的慢查询标准比如500ms。
本文从IT架构以及数据库纬度来分析导致sql执行慢的原因/场景,抛砖引玉,有不足之处还请大家多多提建议。
二、基础知识
分析慢查询之前,我们先看看sql执行的路径,理清楚可能会影响sql执行速度的相关因素。
执行路径
app —[proxy]—db
app — db
目前大部分的数据库架构基本都是上面的路径,sql从app的应用服务器发起经过proxy然后到db,db执行sql进过proxy或者直接返回给app应用服务器。分析这个过程我们可以得到几个会影响sql执行速度的因素
1 网络,各个节点之间的网络
2 OS系统 ,即数据库服务器
3 MySQL数据库本身
三、基础系统层面
3.1 网络层面
网络丢包,重传
其实这个比较容易理解。当sql 从app端发送到数据库,执行完毕,数据库将结果返回给app端,这个将数据返回给app端的过程本质是网络包传输。因为链路的不稳定性,如果在传输过程中发送丢包会导致数据包重传,进而增加数据传输时间。从app端来看,就会觉得sql执行慢。
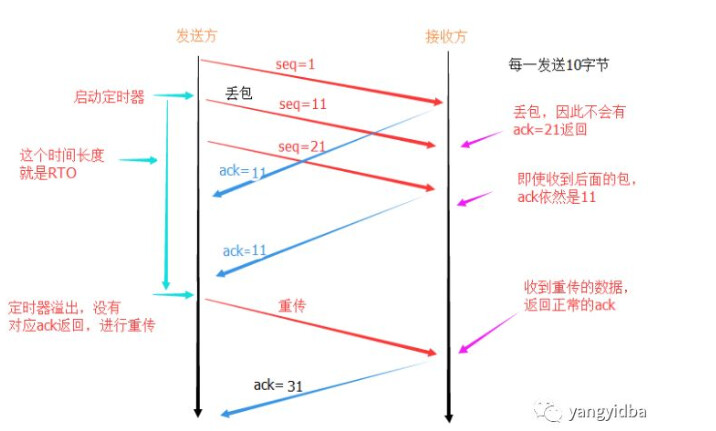
(图来自 https://cloud.tencent.com/developer/article/1195037)
网卡满 比如大字段
这个场景可能不容易遇到,如果公司业务体量很大,比如平时每天300w订单的电商平台,平台大促(双十一,618)的时候极有可能出现网卡被打满。网卡带宽被占满类似各种节假日高速公路收费站(网卡)拥堵导致车流(数据包传输的速度)行动缓慢。

网络链路变长
该场景会影响应用纬度的一个事务比如交易下单整体耗时。
我们知道每个节点之间的数据传输是需要时间的,比如同城跨机房(15KM)之间的访问一般网络耗时1.5ms左右。
链路1 [app1]–调用–[app2]—[proxy]—[db] 相比 链路2[app1] – [proxy] --[db]
执行一条sql请求会增加 [app1]–[app2]之间的网络传输耗时大约3ms。如果一个业务事件包含30个sql ,那么链路1要比链路2 多花至少90ms的时间成本。导致业务整体变慢。
3.2 受到影响IO的场景
磁盘io被其他任务占用
有些备份策略为了减少备份空间的使用,基于xtrabckup备份的时候 使用了 compress 选项将备份集压缩。当我们需要在数据库服务器上恢复一个比较大的实例,而解压缩的过程需要耗费cpu和占用大量io导致数据库实例所在的磁盘io使用率100%,会影响MySQL 从磁盘获取数据的速度,导致大量慢查询。
raid卡 充放电,raid 卡重置
RAID卡都有写cache(Battery Backed Write Cache),写cache对IO性能的提升非常明显,因为掉电会丢失数据,所以必须由电池提供支持。电池会定期充放电,一般为90天左右,当发现电量低于某个阀值时,会将写cache策略从writeback置为writethrough,相当于写cache会失效,这时如果系统有大量的IO操作,可能会明显感觉到IO响应速度变慢,cpu 队列堆积系统load飙高。下面是一个raid充放电导致sql慢查的案例。
root@rac1#megacli -FwTermLog dsply -aALL
11/08/143:36:58: prCallback: PR completed for pd=0a
11/08/143:36:58: PR cycle complete
11/08/143:36:58: EVT#14842-11/03/12 3:36:58: 35=Patrol Read complete
11/08/143:36:58: Next PR scheduled to start at 11/10/123:01:59
11/08/140:48:04: EVT#14843-11/04/12 0:48:04: 44=Time established as 11/04/12 0:48:04; (25714971 seconds since power on)
11/08/1415:30:13: EVT#14844-11/05/12 15:30:13: 195=BBU disabled; changing WB virtual disks to WT ---问题的原因
11/08/1415:30:13: Changein current cache property detected for LD : 0!
11/08/1415:30:13: EVT#14845-11/05/12 15:30:13: 54=Policy change on VD 00/0 to [ID=00,dcp=0d,ccp=0c,ap=0,dc=0,dbgi=0,S=0|0] from [ID=00,dcp=0d,ccp=0d,ap=0,dc=0,dbgi=0,S=0|0]
raid 卡充电将磁盘的写策略有write back 修改为write through ,io性能急剧下降导致sql慢查,进而影响应用层的逻辑处理。
raid 卡重置 当raid卡遇到异常时,会进行重置,相当于程序重启,导致系统io hang。此时也会导致sql慢。下图是生产中遇到的 RAID卡重置案例。

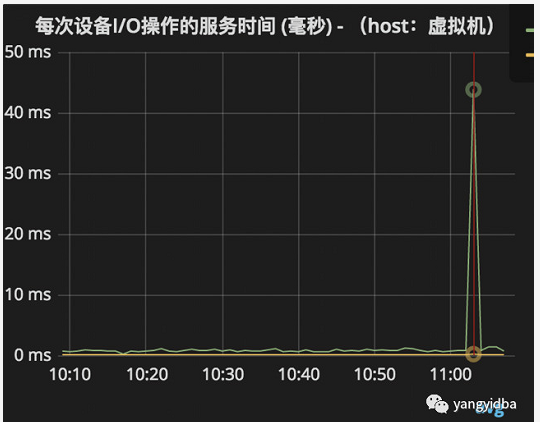
io调度算法
noop(电梯式调度策略):
NOOP实现了一个FIFO队列,它像电梯的工作方式一样对I/O请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一个介质。NOOP倾向于饿死读而利于写,因此NOOP对于闪存设备,RAM以及嵌入式是最好的选择。
deadline(介质时间调度策略):
Deadline确保了在一个截至时间内服务请求,这个截至时间是可调整的,而默认读期限短于写期限。这样就防止了写操作因为不能被读取而饿死的现象。Deadline对数据库类应用是最好的选择。
anticipatory(预料I/O调度策略):
本质上与Deadline一样,但在最后一次读操作后,要等待6ms,才能继续进行对其他I/O请求进行调度。它会在每个6ms中插入新的I/O操作,而会将一些小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量。AS适合于写入较多的环境,比如文件服务器,AS对数据库环境表现很差。
3.3 cpu 类型
cpu 电源策略是控制cpu运行在哪种模式下的耗电策略的,对于数据库服务器推荐最大性能模式 以下内容摘自 《Red Hat Enterprise Linux7 电源管理指南》:

https://access.redhat.com/documentation/zh-cn/red_hat_enterprise_linux/7/pdf/power_management_guide/Red_Hat_Enterprise_Linux-7-Power_Management_Guide-zh-CN.pdf
指令集 最近遇到的一个性能案例是hw的机器,因为指令集合默认关闭导致性能下降15%。

https://support.huawei.com/enterprise/zh/doc/EDOC1000039566/c2662e35
自己对CPU并不精通,所以这里的2个点并非CPU优化配置的全部,自建机房的运维朋友依赖官方技术支持的建议或者技术资料的指导来设置cpu相关参数。
四、数据库层面
4.1 没有索引,或者索引不正确
这个场景其实比较容易理解。相信每个DBA工作过程中都会或多或少遇到性能案例都和索引设计有关:创建表,没有索引,sql随着数据量增大全表扫描而变慢。这个就不额外举例子了。
4.2 隐式转换
发生隐式转换时,MySQL选择执行计划并不能利用到合适的索引而是选择全表扫描导致慢查询。常见的引发隐式转换的场景如下:
in 参数包含多个类型,**简单说,就是在IN的入口有一个判断, 如果in中的字段类型不兼容, 则认为不可使用索引.**例如 --图
判断符号左边是字符串,右边是数字 ,比如 where a=1;其中a是字符串
多表join时,where 左右两边的字段的字符集类型不一致。
推荐阅读《聊聊隐式转换》
4.3 执行计划错误
由于MySQL优化器本身的不足,选择执行计划时会导致错误的执行计划使sql走了错误的索引或者没有做索引。比如
在检查某业务数据库的slowlog 时发现一个慢查询,查询时间 1.57s ,检查表结构 where条件字段存在正确的组合索引,正确的情况下优化器应该选择组合索引,而非为啥会导致慢查询呢?
root@rac1 10:48:11>explain select id,gmt_create, gmt_modified,order_id,service_id, seller_id,seller_nick, sale_type from lol where seller_id= 1501204and service_id= 1and sale_type in(3, 4) and use_status in(3, 4, 5, 6) and process_node_id= 6 order by id desc limit 0,20 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: lol
type: index
possible_keys:idx_sellerid,idx_usestatus_saletype,idx_sellerid_saletype,idx_sidustsvidtype
key: PRIMARY --- 应该选择 idx_sidustsvidtype
key_len: 8
ref: NULL
rows: 3076
Extra: Usingwhere
1 row inset (0.00 sec)
推荐阅读《order by 主键id导致全表扫描的问题 》
4.4 数据巨大
比如select count(*) from t1 where a=‘xxxx’; 尽管字段a有索引,但是如果符合条件的记录数超高10w,查询速度还是会比较慢。
select count(*) from t1 where app = 'marketing';
+----------+
| count(*) |
+----------+
| 2671690 |
+----------+
1 row inset (0.92 sec)
4.5 MetaData Lock锁等待
MDL锁这个场景其实蛮多案例的,比如ddl开始时,针对同一个表的长查询还没结束,后续的写操作都会被堵住导致 thread running 飙高。实例整体的sql执行慢。
案例一 长查询/mysqldump 阻塞DDL

未提交事务阻塞ddl 阻塞查询

推荐阅读《MetaData Lock 之三》
4.6 并发更新同一行
常见的秒杀场景:数据库并发执行update,更新同一行的动作会被其他已经持有锁的会话堵住,并且需要要进行判断会不会由于自己的加入导致死锁,这个时间复杂度O(n),如果有1000个请求,每个线程都要检测自己和其他999个线程是否死锁。如果其他线程都没有持有其他锁,约比较50w次(计算方式 999+998+…+1)。这个种锁等待和检查死锁冲突带来巨大的时间成本。对于OLTP 业务高并发大流量访问的情况下,锁等待会直接导致thread running飙高,所有的请求会被阻塞并等待innodb引擎层处理,于是sql 会变慢。
推荐阅读《热点更新优化方案》
4.7 数据分布不均
其实和数据分布相关,常见的比如 字段a 是标记状态0,1,总行数1000w,a=0的值大概几千条,a=1的有999w多。显然执行
select count(*) from tab where a=1 ;
的查询效率肯定比查询a=0的要慢很多。
select count(*) from tab where a=0 ;
4.8 sql 姿势不合理
常见的分页查询 ,使用大分页深度查询。
SELECT * FROM table where kid=1342 and type=1 order id desc limit 149420 ,20;
该SQL是一个非常典型的排序+分页查询:order by col desc limit N,M MySQL 执行此类SQL时需要先扫描到N行,然后再去取 M行。对于此类操作,取前面少数几行数据会很快,但是扫描的记录数越多,SQL的性能就会越差,因为N越大,MySQL需要扫描越多的数据来定位到具体的N行,这样耗费大量的IO 成本和时间成本。
针对limit 优化有很多种方式:
1 前端加缓存、搜索,减少落到库的查询操作。比如海量商品可以放到搜索里面,使用瀑布流的方式展现数据,很多电商网站采用了这种方式。
2 优化SQL 访问数据的方式,直接快速定位到要访问的数据行。
3 使用书签方式 ,记录上次查询最新/大的id值,向后追溯 M行记录。对于第二种方式 我们推荐使用"延迟关联"的方法来优化排序操作,何谓"延迟关联" :通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。
推荐阅读《性能优化之分页查询》
4.9 表结构设计
表结构设计是否合理也是影响sql性能的重要因素之一。以下表格展示了字段类型不同带来的rt性能差异。其中字段c1 为int类型的字段,字段c2则是表名对应的字符串长度类型varchar(200)到varchar(5000) ,还有text字段。
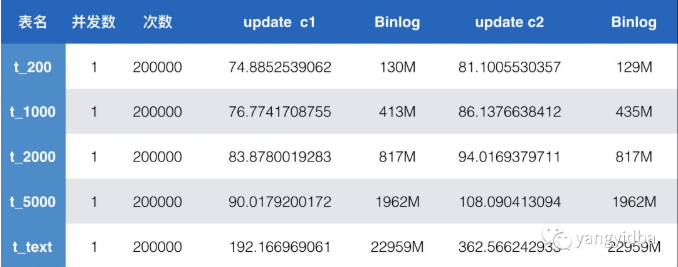
对于读请求,单独查询c1 int类型的性能并无差异。查询字段c2时,随着字段占用的实际字节大小增大,耗费的时间增加,也即rt增大。带宽逐步增大,text的带宽147MB 对于千兆网卡已经满了。
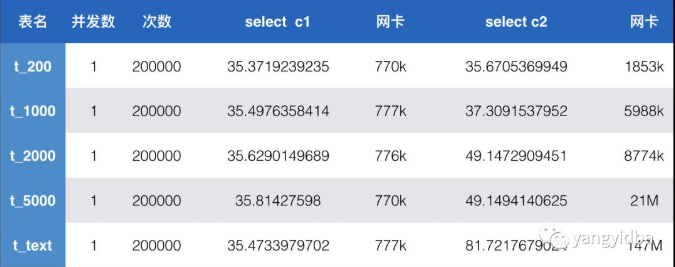
对于写请求,因为binlog为row模式,字段长度越大,binlog也越大,网络传输带宽增加。整体rt也增加。
4.10 innodb 刷脏页
对数据库运行机制有一定了解的朋友都会知道InnoDB引擎采用Write Ahead Log(WAL)策略,即事务提交时,先写日志(redo log),再写磁盘。为了提高IO效率,在写日志的时候会先写buffer,然后集中flush buffer pool 到磁盘。 这个过程 我们称之为刷脏页。官方文档中描述:
With heavy DML activity, flushing can fall behind if it is not aggressive enough, resulting in excessive memory use in the buffer pool; or, disk writes due to flushing can saturate your I/O capacity if that mechanism is too aggressive. 这个过程中就有可能导致平时执行很快的SQL突然变慢。
推荐阅读:
https://dev.mysql.com/doc/refman/5.7/en/innodb-lru-background-flushing.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-performance-adaptive_flushing.html
4.11 undo 没有被purge/回收
UNDO 日志是 MVCC 的重要组成部分,当一条数据被修改时,UNDO 日志里面保存了记录的历史版本。当事务需要查询记录的历史版本时,可以通过 UNDO 日志构建特定版本的数据。
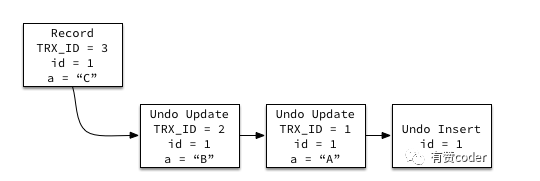
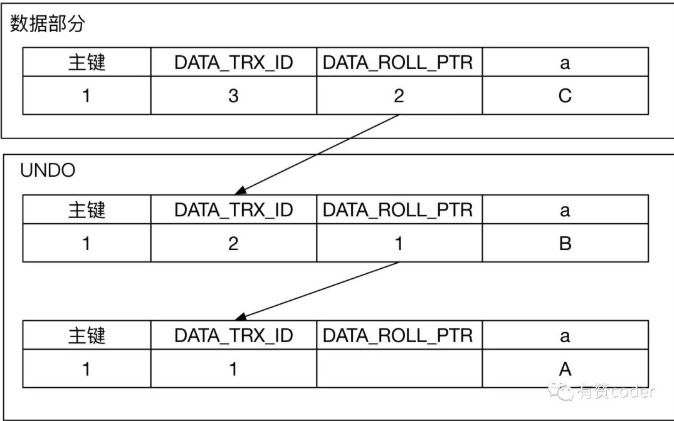
每条行记录上面都有一个指针 DATA_ROLL_PTR,指向最近的 UNDO 记录。同时每条 UNDO 记录包含一个指向前一个 UNDO 记录的指针,这样就构成了一条记录的所有 UNDO 历史的链表。当 UNDO 的记录还存在,那么对应的记录的历史版本就能被构建出来。
当记录对应的版本通过 DATA_TRX_ID 比对发现不可见时,通过系统列 DATAROLLPTR,找到对应的回滚段记录,继续通过上述判断记录可见的规则,进行判断,如果记录依旧不可见,继续通过回滚段查找之前的版本,直到找到对应可见的版本。
所以当有长事务/异常未提交的情况就会因为其他查询需要构建快照导致undo 不能被及时回收。查询遍历的undo越多sql执行的越慢。
推荐阅读《一次大量删除导致 MySQL 慢查的分析》
五、小结
这里总结了我工作经历中遇到的一部分可能会影响SQL执行效率的场景或者案例,经历有限,难免有遗漏的案例/场景,抛砖引玉,欢迎各位有兴趣的读者朋友留言说说你们遇到的场景。
转自有赞Coder公众号
