听完企业微信实战(三)的直播课后,按照老师的步骤在实战(二)的基础上进行代码改造,把driver私有化,增加find_element、find_elements和显式等待,改造完成并且成功运行,但是重复执行几次后,有几次运行很快,有几次运行半天还在转圈,只能停止运行,感觉奇怪的我就查看了进程,然后发现进程中有一堆的chromedriver,我就想着加上quit方法,结果问题仍然存在。去群里求助,同学和老师都给出了建议,遗憾的是我实在找不到解决方案,所以来此发帖求助。下面是我写的代码:
test_add_member.py:
from time import sleep
from webchat.page.index import Index
class TestAddMember:
def setup(self):
self.index = Index(reuse=True)
def teardown(self):
self.index.driver_quit()
print('teardown')
def test_add_member(self):
member = self.index.goto_add_member()
# 测试添加成员
member.add_member()
sleep(2)
# 获取通讯录表格中所有成员的姓名
names = member.get_table_names()
# 断言新添加的成员姓名在通讯录中
assert 'test_add' in names
add_member.py:
from selenium.webdriver.common.by import By
from webchat.page.base_page import BasePage
class AddMember(BasePage):
# 添加成员操作
def add_member(self):
# 添加姓名
self.find_element(By.ID, "username").send_keys("test_add")
# 添加账号
self.find_element(By.ID, "memberAdd_acctid").send_keys("hogwarts")
# 添加手机号
self.find_element(By.ID, "memberAdd_phone").send_keys("12345678910")
# 点击保存按钮
self.find_element(By.CSS_SELECTOR, ".js_btn_save").click()
# 获取通讯录界面table里所有姓名的值
def get_table_names(self):
names = []
# td:nth-child(2):获取td父元素的第二个子元素,即获取tr的第二个td,也就是姓名
td_names = self.find_elements(By.CSS_SELECTOR, "#member_list td:nth-child(2)")
for td in td_names:
# 获取姓名的值
title = td.get_attribute("title")
names.append(title)
return names
index.py:
from selenium.webdriver.common.by import By
from webchat.page.add_member import AddMember
from webchat.page.base_page import BasePage
class Index(BasePage):
# 打开企业微信首页(需要浏览器已登录企业微信)
base_url = "https://work.weixin.qq.com/wework_admin/frame"
def goto_add_member(self):
# 点击通讯录按钮
self.find_element(By.ID, "menu_contacts").click()
def wait(x):
# 页面中是否有姓名输入框
e_len = len(self.find_elements(By.ID, "username"))
if e_len < 1:
# 如果没有,则点击添加成员按钮
self.find_element(By.CSS_SELECTOR, ".ww_operationBar:nth-child(1) > .js_add_member").click()
return e_len > 0
# 显式等待
self.wait_for(wait)
# 跳转至添加成员页(对AddMember进行了实例化)
return AddMember(reuse=True)
base_page.py:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
class BasePage:
_driver = ""
base_url = ""
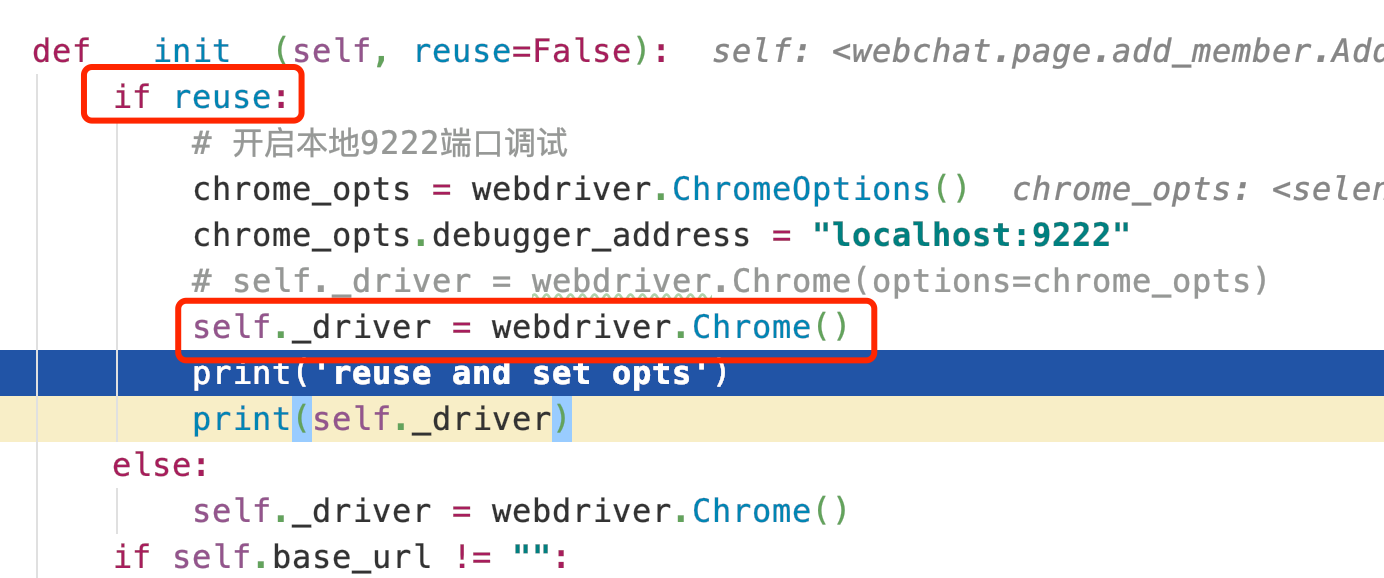
def __init__(self, reuse=False):
if reuse:
# 开启本地9222端口调试
chrome_opts = webdriver.ChromeOptions()
chrome_opts.debugger_address = "localhost:9222"
self._driver = webdriver.Chrome(options=chrome_opts)
else:
self._driver = webdriver.Chrome()
if self.base_url != "":
self._driver.get(self.base_url)
# 隐式等待
self._driver.implicitly_wait(3)
def driver_quit(self):
self._driver.quit()
print('exc driver quit')
def find_element(self, by, value):
return self._driver.find_element(by, value)
def find_elements(self, by, value):
return self._driver.find_elements(by, value)
def wait_for(self, func):
WebDriverWait(self._driver, 10).until(func)
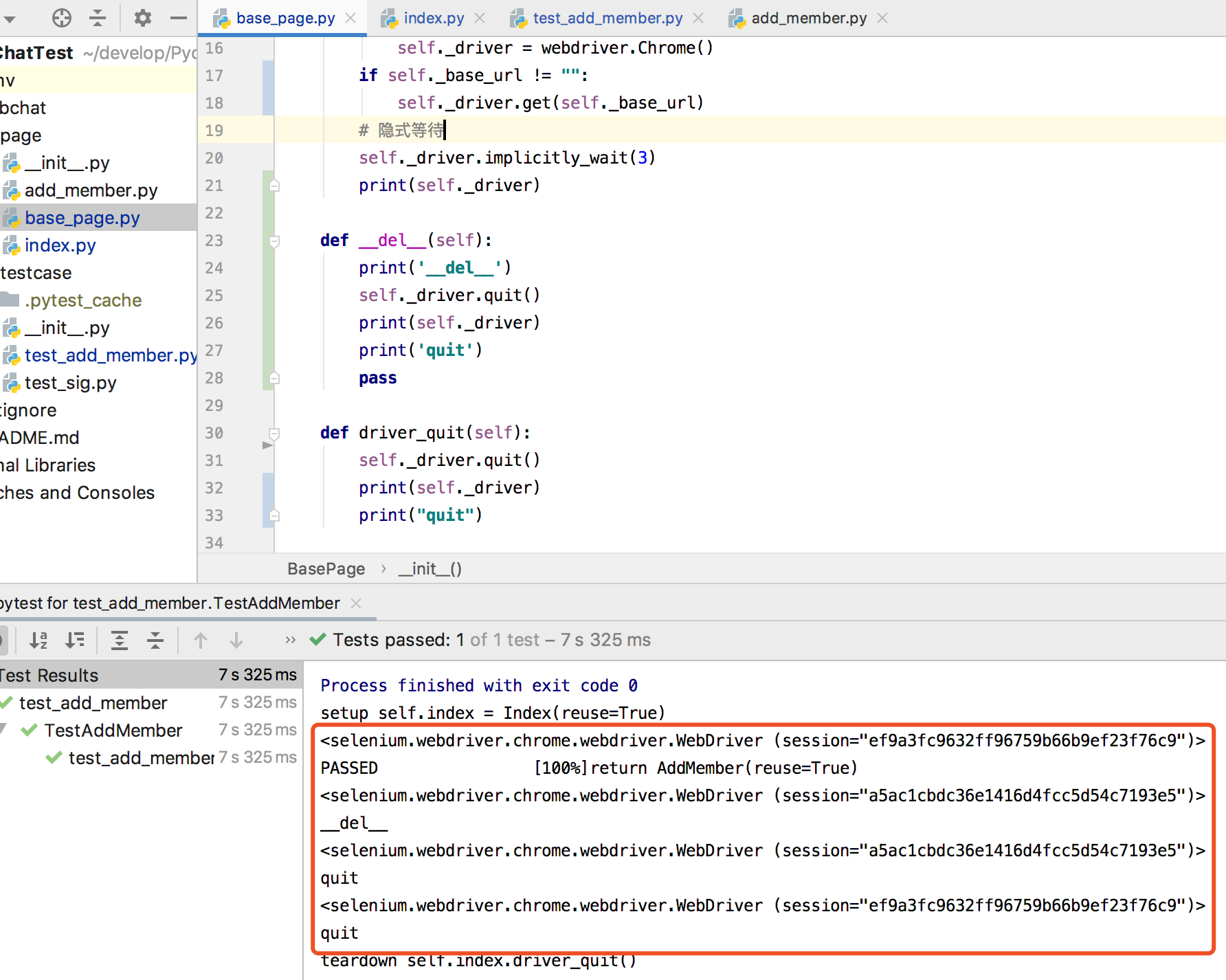
之前只关注了quit是否执行,根据控制台的信息,quit确实执行了,但是进程并没有并关掉,后来在BasePage的__init__方法中打印self._driver发现了问题,如下图:
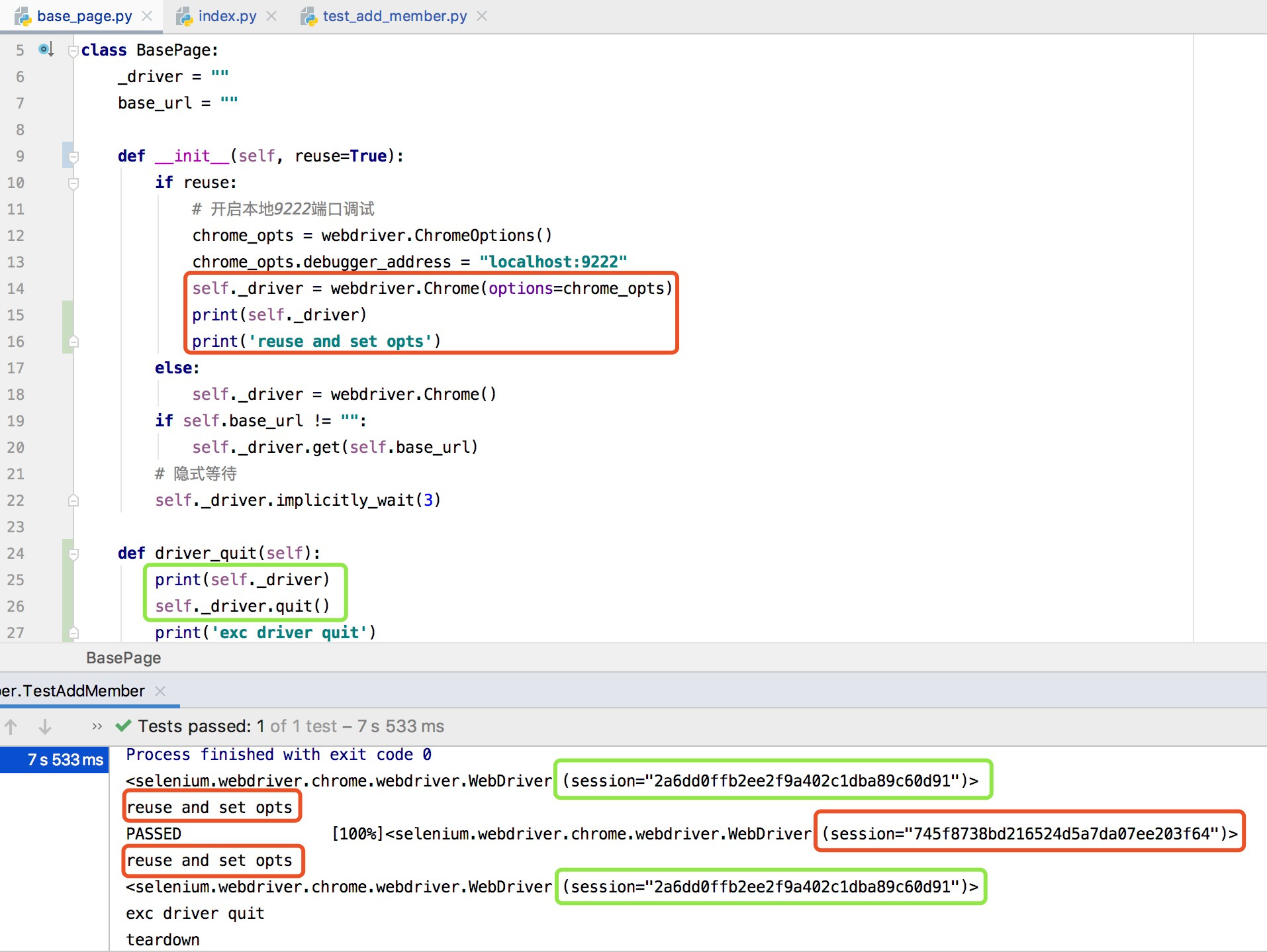
根据图中打印的信息,貌似是index.py的return AddMember(reuse=True)和test_add_member.py的self.index = Index(reuse=True)这两行代码都走了reuse为True的方法,即执行了两遍下列代码:
chrome_opts = webdriver.ChromeOptions()
chrome_opts.debugger_address = "localhost:9222"
self._driver = webdriver.Chrome(options=chrome_opts)
所以每次运行都生成了两个self._driver,quit方法只退出了第一次生成的那个self._driver,第二次生成的self._driver在进程中保留,所以每执行一次,进程中就多一个chromedriver。
然后我又想到,如果是这样的话,那么我之前没加quit方法的时候,岂不是每次执行都多出两个chromedriver的进程。。。 但是当我去掉quit方法运行观察后,加不加quit方法都是每次执行多出一个chromedriver的进程,实在不知道什么原因,无从下手