魔法师们请编写一个魔法,将字符串
'霍\\u683c沃\\u5179' 转为 霍格沃兹
不明白考查的知识点是不是这个?希望老师指点。。
#字符转码
def fun_a(a):
b=str(a)
c=b.replace('\\\\u683c','\u683c')
d=c.replace('\\\\u5179','\u5179')
return d
x=r'霍\\u683c沃\\u5179'
print(str(fun_a(x)))
汉字和\u 混合的字符串 转为 汉字 的问题,不能直接这样替换呢
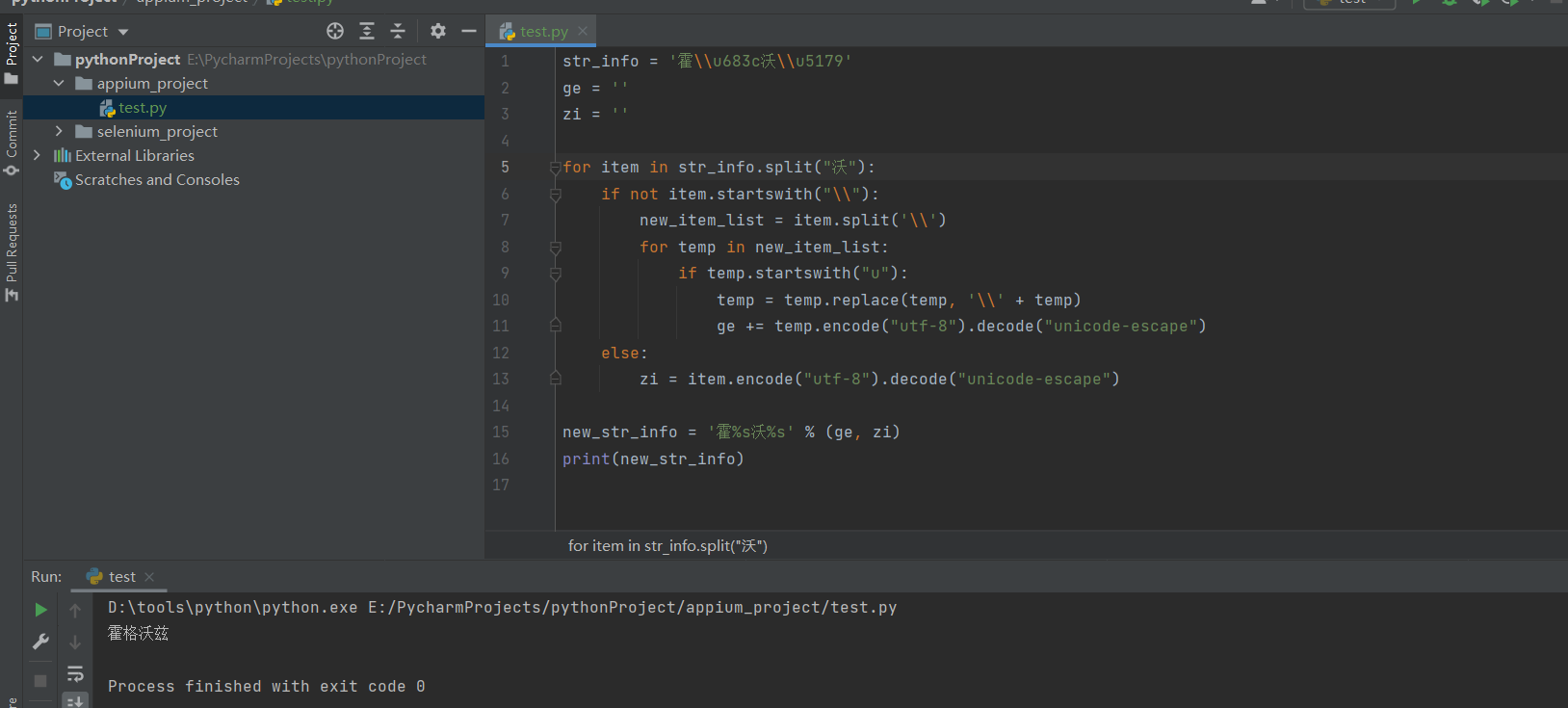
def rev_string():
""" 字符转换"""
s = '霍\\u683c沃\\u5179'
re = ''
# print(s.encode('utf-8').decode('raw_unicode-escape'))
for item in s.split('沃'):
if not item.startswith('\\'): #如果不是\开头,则说明第一位是中文
re += item[0]
re += item[1:].encode('utf-8').decode('raw_unicode-escape')
else: #如果是\开头,说明这边就是一开始的分割点,则需要加上原分割的中文:沃
re += '沃'
re += item.encode('utf-8').decode('raw_unicode-escape')
print(re)
字符编码太烦了。。。
def my_test(data: str):
data = data.replace('\\\\u', '\\u')
regex = re.compile('[\u4e00-\u9fa5]')
chinese_word = regex.findall(data)
result = ''
for i, row in enumerate(chinese_word):
new_list = data.split(row)
result += new_list[0].encode('ascii').decode('unicode_escape')
result += row
if len(new_list) == 2:
data = new_list[1]
else:
new_list.pop(0)
data = row.join(new_list) # 将数据重新拼成这句
if i + 1 == len(chinese_word) and new_list[1]:
result += new_list[1].encode('ascii').decode('unicode_escape')
return result
data = r'霍\\u683c沃\\u5179'
ss = my_test(data)
print(ss)
import json
def parse(inp_str):
return json.loads('"%s"' % inp_str)
assert "霍格沃兹" == parse('霍\\u683c沃\\u5179')

import re
def decode_item(content):
content = re.sub(r'(\\u[a-zA-Z0-9]{4})', lambda x: x.group(1).encode("utf-8").decode("unicode-escape"), content)
return content