场景:有一个新增/编辑数据的接口,有50个参数,假设针对每个参数设计五个测试用(实际情况中不止),在不考虑参数之间的依赖关系的情况下,至少就有250条用例,这种情况下,肯定是需要使用参数化来编写自动化用例,在这种情况下怎么设计用例的断言呢?
疑问:
1、断言的颗粒度(很多小公司就只有那么一两个人在搞自动化,没有标准,也没有参考的东西,什么东西都是自己定)
2、这种情况下用例怎么设计,是写一个测试用例,还是说根据某种条件分为多个测试用例
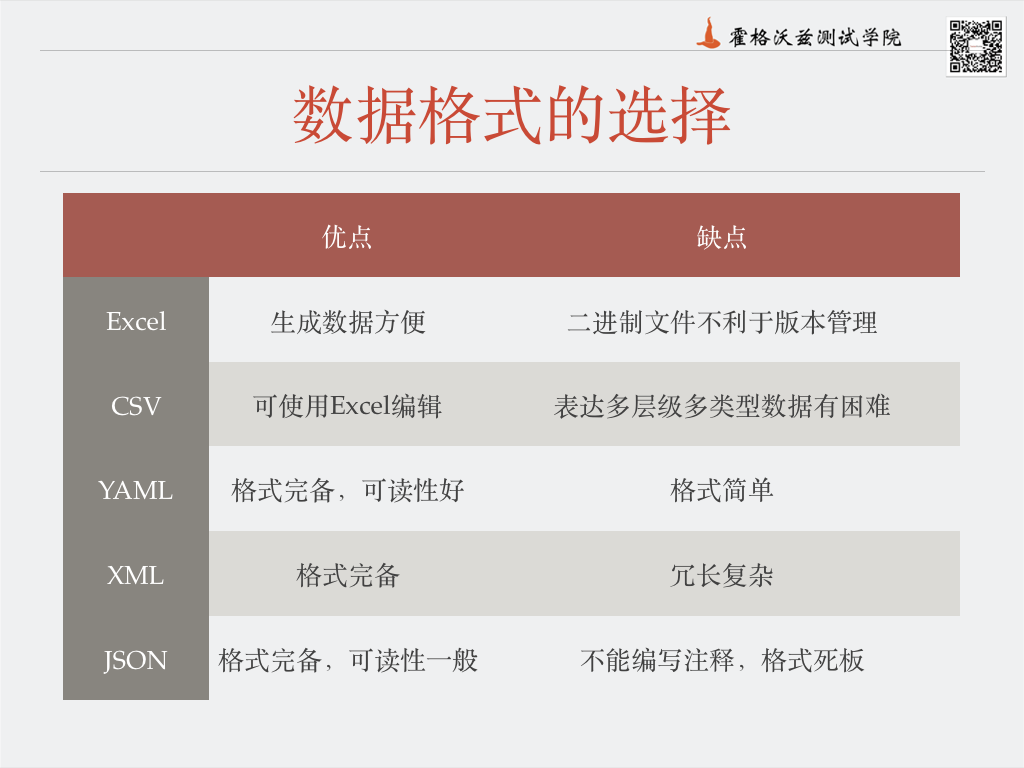
3、yaml、json、excel、csv,这几种方式那种更优,或者说他们分别适合什么样的场景,例如,上面这个场景适合使用什么?我个人目前算是用的json。如上述场景下,我是将请求体放到一个json文件作为源数据,然后使用python去读取json文件,用字典的方式去修改想要测试的字段,一个接口的数据文件还是有上百行代码。如果参数少的接口,直接用python定义一个字典,然后去修改字典。把修改过的字典转成json格式存到列表,代码如下
import json
test_data = {‘id’: None, ‘name’: ‘test’, ‘age’: 18}
def body():
list_data = []
test_data[‘name’] = ‘’
list_data.append(json.dumps(test_data).encode(encoding=‘utf-8’))
test_data[‘name’] = ‘123455’
list_data.append(json.dumps(test_data).encode(encoding=‘utf-8’))
test_data[‘name’] = ‘@!#!$%#^&’
list_data.append(json.dumps(test_data).encode(encoding=‘utf-8’))
test_data[‘name’] = ‘测试’
list_data.append(json.dumps(test_data).encode(encoding=‘utf-8’))
return list_data
不知道这种方法是否可取
1 个赞
首先说下这个情况发生的背景,多数都是一些国企部门当年搞服务的时候留下的技术债。一直没拆分重构导致形成了也给庞大的接口服务。他本质是很多功能的大杂烩。也不排除有一些接口的确是参数多。他这个接口接口后面有非常重的逻辑,做的好点的可能会路由到了其他的服务模块拿回结果做聚合
断言通常分2种情况
- 根据业务编写断言。这个的确是需要的。但是不要在一个脚本里去断言所有的。而是根据功能、分开用例,每个用例只断言自己关注的数据即可。
- 断言使用算法来做,比如新老版本之间进行diff,跨环境之间进行diff
- 拆分用例是需要的。有必要的话,测试数据也尽量拆分。不要互相干扰。
- 根据业务功能拆分用例即可
如果你用例清晰了,那么用什么格式都是可以的。 所有格式之都有自己的特点。整体推荐使用yaml。你用json也是可以的。不是最佳的,也影响不大。
这个方式也不够好,你需要做一个自己的造数的工具。原始数据类似这样
- template: {‘id’: None, ‘name’: ‘test’, ‘age’: 18}
- name: [a, b, c]
- age: [16, 18, 20, 55]
根据这份源数据,你用笛卡尔积或者正交法,去生成你想要的各种排列组合。然后使用参数化用例去生成所需要的各种测试用例
2 个赞